







一般使用BeautififulSoup解析得到的Soup文档可以使用
find_all()、find()、select()方法定位所需要的元素。find_all()是获得list列表、find()是获得map一条数据。select()是根据选择器可以获得多条也可以获得单条数据。一般最常用的是find_all()和find()两个参数。
select()方法的使用
- 从页面中自定义获得选择器:
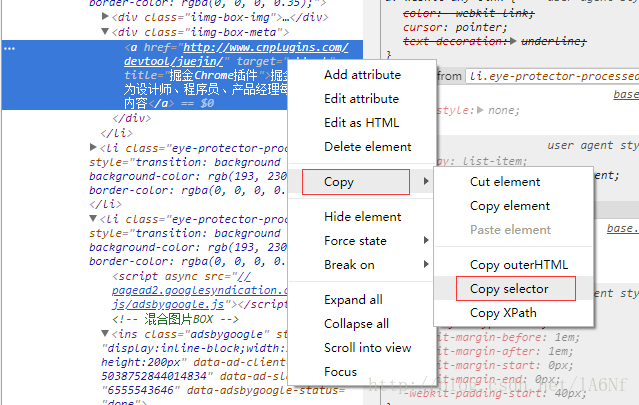
F12中选择了目标element之后,右键—Copy—Copy selector 如图:
nth-child在Python中运行会报错,需要改为nth-of-type:
如果所复制的选择器中包含nth-child,则需要改为nth-of-type,否则会报错。- demo:
import requests
from bs4 import BeautifulSoup
url = 'http://www.cnplugins.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
res = requests.get(url,headers = headers) #get方法中加入请求头
#查看下当前requests请求url抓去的数据编码,这里获取的是ISO-8859-1
print (requests.get(url).encoding)
#翻阅下要爬去的网站的编码是什么,这里看了下是utf-8,编码不一样会乱码,将requests获取的数据编码改为和目标网站相同,改为utf-8
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser') #对返回的结果进行解析
# print (soup.select('body > section > div.wrapbox > div:nth-child(1) > div > ul > li:nth-child(6)'))
# nth-child 在python中运行会报错,需改为 nth-of-type
# print (soup.select('body > section > div.wrapbox > div:nth-of-type(1) > div > ul > li:nth-of-type(6)'))
textlist = soup.select('body > section > div.wrapbox > div > div > ul > li > div.iimg-box-meta > a')
for t in textlist:
print (t) #获取单条html信息
print (t.get_text()) #获取中间文字信息














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









