







目录
kafka的管理需要借助zookeeper完成,所以要先安装好zookeeper集群。
1、zookeeper集群安装
1、集群规划
- 在node1、node2 和 node3 三个节点上都部署 Zookeeper。
2、解压安装
官网下载地址:Apache ZooKeeper

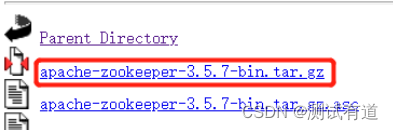
- 1、在 node1服务器解压 Zookeeper 安装包到目录下:/export/server
- 2、修改 apache-zookeeper-3.5.7-bin 名称为 zookeeper-3.5.7
3、配置服务器编号
- 1、在node1服务器下/export/server/apache-zookeeper-3.5.7这个目录下创建 zkData
- 2、zkData 目录下创建一个 myid 的文件,文件内容为:1
- 在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
- 注意:添加 myid 文件,一定要在 Linux 里面创建,在 notepad++和其他文本编辑器里面很可能乱码
- 3、拷贝配置好的 zookeeper 到其他机器上
- 并分别在 node1、node2上修改 myid 文件中内容为 2、3
scp -r apache-zookeeper-3.5.7 root@node2:$PWD
scp -r apache-zookeeper-3.5.7 root@node3:$PWD
4、配置zoo.cfg文件
- 1、重命名/export/server/apache-zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
- 2、打开 zoo.cfg 文件
vim zoo.cfg
#修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
#增加如下配置
#######################cluster##########################
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
- 3、同步 zoo.cfg 配置文件到node2、node3服务器
scp -r zoo.cfg root@node2:$PWD
scp -r zoo.cfg root@node3:$PWD
4.1、配置参数说明
server.A=B:C:D
- A 是一个数字,表示这个是第几号服务器;
- 集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据 就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比 较从而判断到底是哪个 server。
- B 是这个服务器的地址;
- C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
- D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5、集群操作
- 1、分别启动 Zookeeper
./zkServer.sh start
- 2、查看状态
./zkServer.sh status



2、kafka集群安装
2.1 集群规划

2.2、集群部署
- 官方下载地址:Apache Kafka
- 1、解压安装包
cd /export/software
tar -zxvf kafka_2.12-3.0.0.tgz -C /export/server/
- 2、修改解压后的文件名称
cd /export/server/
mv kafka_2.12-3.0.0/ kafka-3.0.0
- 3、进入到/export/server/kafka-3.0.0/conf 目录,修改配置文件server.properties
cd /export/server/kafka-3.0.0/config
vim server.properties修改以下内容:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/export/server/kafka-3.0.0/datas#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=node1:2181,node2:2181,node2:2181/kafka
- 4、分发安装包到节点node2,node3
scp -r kafka-3.0.0/ node2:$PWD
scp -r kafka-3.0.0/ node3:$PWD
- 5、分别在 node2 和 node3 上修改配置文件/export/server/kafka-3.0.0/config/server.properties 中的 broker.id=1、broker.id=2
- 注:broker.id 不得重复,整个集群中唯一。
- 6、配置环境变量
- 1、在/etc/profile 文件中增加 kafka 环境变量配置
#KAFKA_HOME
export KAFKA_HOME=/export/server/kafka-3.0.0/
export PATH=$PATH:$KAFKA_HOME/bin
- 2、刷新一下环境变量。
source /etc/profile
- 3、分发环境变量文件到其他节点,并 source。
scp -r /etc/profile node2:$PWD
scp -r /etc/profile node3:$PWDsource /etc/profile
- 7、启动集群
- 1、先启动 Zookeeper 集群,然后启动 Kafka。
./zk.sh start
- 2、依次在 node1、node2、node3 节点上启动 Kafka。
cd /export/server/kafka-3.0.0
bin/kafka-server-start.sh -daemon config/server.properties
- 8、关闭集群
cd /export/server/kafka-3.0.0
bin/kafka-server-stop.sh
2.3、集群启停脚本
- 1、在目录/export/server/scripts下下创建文件 kf.sh 脚本文件
vim kf.sh
文件内容如下:
#! /bin/bash
case $1 in
"start"){
for i in node1 node2 node3
do
echo " --------启动 $i Kafka-------"
ssh $i "/export/server/kafka-3.0.0/bin/kafka-server-start.sh -daemon /export/server/kafka-3.0.0/config/server.properties"
done
};;
"stop"){
for i in node1 node2 node3
do
echo " --------停止 $i Kafka-------"
ssh $i "/export/server/kafka-3.0.0/bin/kafka-server-stop.sh"
done
};;
esac- 2、添加执行权限
chmod +x kf.sh
- 3、启动集群命令
./kf.sh start
- 4、停止集群命令
./kf.sh stop
- 注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper 集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止, Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









