







决策树算法理论篇
1、决策树直观理解:

假设,已知10人房产、婚姻、年收入以及能否偿还债务的样本,那么第11个人来,知其房产、婚姻、以及年收入情况,问他是否能偿还债务?
2、前置知识:
理解决策树,我们必须知道一下概念:
信息熵:描述系统的不确定度,熵越高,代表系统越混乱,包含的信息量也就越多,其公式:
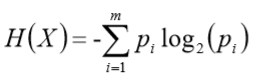
例(计算前10个样本能否还债y的信息熵):-0.7log2(0.7)- 0.3log2(0.3)= 0.88
条件熵:给定条件X的情况下,所有不同x值情况下Y的信息熵的平均值叫做条件熵。
例(计算y能否还债相对于房产的条件熵):0.40 + 0.6[-0.5log2(0.5)]*2 = 0.6
3、解决问题
在明白了信息熵和条件熵后,我们再来看之前的问题,我们会发现房产、婚姻以及能否还债均是离散值,而年收入一项是连续值,所以:
第一步:连续值的离散化,其方法很多,主要有:(要根据实际业务需求)
- 用KMeans算法
- 计算均方差
- 计算该字段相对于离散型预测字段的条件熵、条件基尼或者条件错误率等
这里为了简便,假设以100为界,大于等于它的为“高”收入,否则为“低”收入;
第二步:计算y相对于各个x的条件熵:
- H(能否偿债/房产) = L(能否偿债/房产=有) * P(房产=有) + L(能否偿债/房产=无) * P(房产=无)
=0 * 0.4 + [-0.5*log(0.5)*2]*0.6 = 0.6 - H(能否偿债/婚姻) = 1 * 0.4 + 0 * 0.3 + 0.9183 * 0.3 = 0.6755
- H(能否偿债/收入) = 0 * 0.5 + 0.9710 * 0.5 = 0.4855
熵小的,信息增益必然大,所以ID3中可以只看熵(越小越好)
按收入划分

**第三步:**计算各个子结点中y相对于各个x的条件熵
- 左边:能否偿债恒等于能,终止继续往下划分,并确定为“能”偿债
- 右边:H(能否偿债/房产) = 0 * 0.2 +0.8113 * 0.8 = *0.6490,
H(能否偿债/婚姻) = 1 * 0.4 + 0 * 0.4 + 0 * 0.2 = *0.4
所以右边按婚姻划分

第四步:最后按照唯一剩下的字段房产划分

第五步:预测

首先收入85小于100,所以为低收入,其次,婚姻状况为单身,所以判定不能还债















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









