







1. 决策树
决策树(Decision Tree)是一种预测模型;它是通过一系列的判断达到决策的方法。下面是一个判断是否买房的例子,一共15个实例,有Age, Has_job, Own_house, Credit_rating四个属性,树的各个分叉是对属性的判断,叶子是各分枝的实例个数。
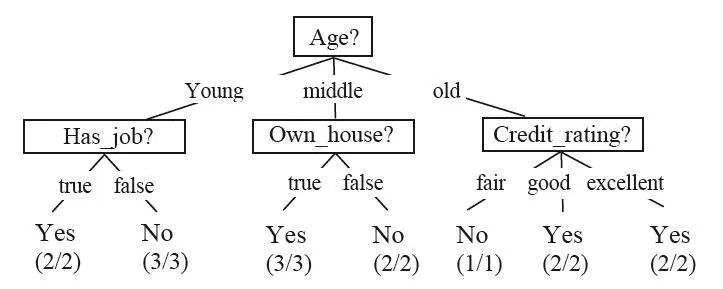
这是个很简单的例子,只用了两层,每个叶子节点就得到了一致的结果(如2/2),如果不一致,则会使用其它属性递归地划分,直到属性用完,或分支下得到一致的结果,或者满足一定停止条件。对于有歧义的叶子节点,一般用多数表决法。
决策树的优点是复杂度低,输出结果直观,对中间值缺失不敏感;缺点是可能过拟合,有时用到剪枝的方法避免过拟合。
决策树的原理看起来非常简单,但在属性值非常多,实例也非常多的情况下,计算量是庞大的,我们需要采用一些优化算法:先判断哪些属性会带来明显的差异,于是引出了信息量的问题。
2. 信息量
意外越大,越不可能发生,概率就越小,信息量也就越大,也就是信息越多。比如说“今天肯定会天黑”,实现概率100%,说了和没说差不多,信息量就是0。
信息量= log2(1/概率)=log2(概率^-1)=-log2(概率),log2是以2为底的对数。
举个例子:掷色子每个数有1/6的可能性,即log2(6)=2.6,1-6的全部可能性,二进制需要3位描述(3>2.6);抛硬币正反面各1/2可能性,log(2)=1,二进制用一位即可描述,相比之下,掷色子信息量更大。
3. 熵
熵=H=-sum(概率*log2(概率)),可以看到它是信息量的期望值,描述的也是意外程度,即不确定性。0<H<log2(m),m是分类个数,log2(m)是均匀分布时的熵。二分类熵的取值范围是[0,1],0是非常确定,1是非常不确定。
4. 信息量与熵
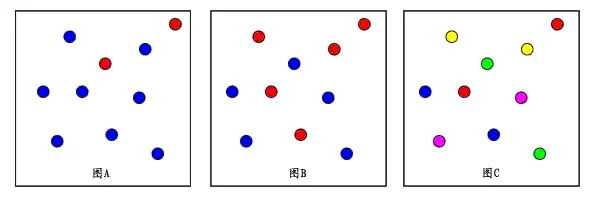
分类越多->信息量越大->熵越大,如图所示:图C将点平均分成5类(熵为2.32),图B将点平均分成两类(熵为1),则看起来C更复杂,更不容易被分类,熵也更大。
分类越平均->熵越大。图B(熵为1)比A(熵为0.72)更复杂,更不容易被分类,熵也更大。
5. 信息增益
信息增益(Information Gain):熵A-条件熵B,是信息量的差值。也就是说,一开始是A,用了条件后变成了B,则条件引起的变化是A-B,即信息增益(它描述的是变化Delta)。好的条件就是信息增益越大越好,即变化完后熵越小越好(熵代表混乱程度,最大程度地减小了混乱)。因此我们在树分叉的时候,应优先使用信息增益最大的属性,这样降低了复杂度,也简化了后边的逻辑。
6. 举例
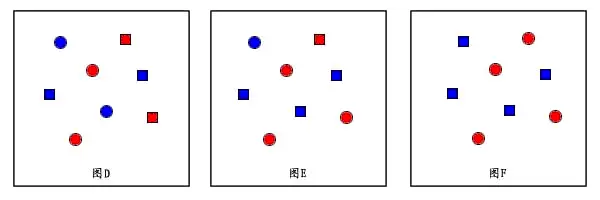
假设使用8天股票数据实例,以次日涨/跌作为目标分类,红为涨,蓝为跌,如上图所示涨跌概率各50%:50%(2分类整体熵为1),有D,E,F三个属性描述当日状态,它们分别将样本分为两类:方和圆,每类四个。D中方和圆中涨跌比例各自为50%:50%(条件熵为1,信息增益0)。E中方的涨跌比例为25%:75%,圆的涨跌比例为75%:25%(条件熵为0.81,信息增益0.19),F中方的涨跌比例为0:%:100%,圆的涨跌比例为100%:0%(条件熵为0,信息增益1)。
我们想要寻找的属性是可直接将样本分成正例和反例的属性,像属性F为圆一旦出现,第二天必大涨,而最没用的是D,分类后与原始集合正反比例相同。E虽然不能完全确定,也使我们知道当E为圆出现后,比较可能涨,它也带有一定的信息。
使用奥卡姆剃刀原则:如无必要,勿增实体。不确定有用的就先不加,以建立最小的树。比如,如个属性X(代表当日涨幅),明显影响第二天,则优先加入,属性Y(代表当天的成交量),单独考虑Y,可能无法预测第二天的涨跌,但如果考虑当日涨幅X等因素之后,成交量Y就可能变为一个重要的条件,则后加Y。属性Z(隔壁张三是否买了股票),单独考虑Z,无法预测,考虑所有因素之后,Z仍然没什么作用。因此属性Z最终被丢弃。策略就是先把有用的挑出来,不知道是不是有用的往后放。
7. 熵的作用
熵是个很重要的属性,它不只是在决策树里用到,各个分类器都会用到这个量度。比如说,正例和反例为99:1时,全选正例的正确率也有99%,这并不能说明算法优秀。就像在牛市里能挣钱并不能说明水平高。另外分成两类,随机选的正确率是50%;分而三类,则为33%,并不是算法效果变差了。在看一个算法的准确率时,这些因类都要考虑在内。在多个算法做组合时,也应选择信息增益大的放在前面。
在决策树中利用熵,可以有效地减小树的深度。计算每种分类的熵,然后优先熵小的,依层次划分数据集。熵的算法,一般作为决策树的一部分,把它单拿出来,也可以用它筛选哪个属性是最直接影响分类结果的。
8. 计算熵的程序
# -*- coding: utf-8 -*-
import math
def entropy(*c):
if(len(c)<=0):
return -1
result = 0
for x in c:
result+=(-x)*math.log(x,2)
return result;
if (__name__=="__main__"):
print(entropy(0.99,0.01));9. 决策树的核心程序
(1) 软件安装
ubuntu系统
$ sudo pip install sklearn
$ sudo pip install pydotplus
$ sudo apt-get install graphviz
(1) 代码
# 训练决策树
X_train, X_test, y_train ,y_test = cross_validation.train_test_split(X,y,test_size=0.2)
clf = tree.DecisionTreeClassifier(max_depth=5)
clf.fit(X_train,y_train)
accuracy = clf.score(X_test,y_test)
print("accuracy:",accuracy)
# 生成决策树图片
dot_data = StringIO()
tree.export_graphviz(clf,out_file=dot_data,
feature_names=["open","high","low","close","turnover"],
filled=True,rounded=True,
impurity=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
open('/tmp/a.jpg','wb').write(graph.create_jpg())10. 如何看待决策树的结果
使用sklearn的tree训练数据后,可得到准确度评分。如果数据集中包含大量无意义的数据,评分结果可能不是很高。但是从图的角度看,如果某一个叶子节点,它的实例足够多,且分类一致,有的情况下,我们可以把这个判断条件单独拿出来使用。
使用一个模型,不是丢进一堆数据,训练个模型,看个正确率,预测一下就完了。要需要仔细去看树中的规则。树本身就是一个无序到有序的变化过程。
















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









