







New Optimizers for Deep Learning
五个Optimizer:
- SGD
- SGD with momentum(SGDM)
三个Adaptive learning rate的方法:
- Adagrad
- RMSProp
- Adam
Some Notations(符号)
θ
t
\theta_{t}
θt:model parameters at time step t
▽
L
(
θ
t
)
\triangledown L(\theta_{t})
▽L(θt) or
g
t
g_{t}
gt:gradient at
θ
t
\theta_{t}
θt ,used to compute
θ
t
+
1
\theta_{t+1}
θt+1
m
t
+
1
m_{t+1}
mt+1:momentum accumulated from time step 0 to time step t,which is used to compute
θ
t
+
1
\theta_{t+1}
θt+1
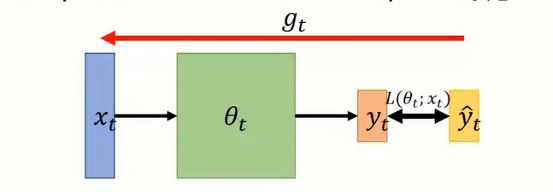
Optimization:
- find a θ \theta θ to get the lowest ∑ x L ( θ ; x ) \sum _{x} L(\theta ;x) ∑xL(θ;x)
- or, find a θ \theta θ to get the lowest L ( θ ) L(\theta) L(θ)
On-line:one pair of
(
x
t
,
y
^
t
)
(x_{t},\hat{y}_{t})
(xt,y^t) at a time step;

Off-line:one pair of
(
x
t
,
y
^
t
)
(x_{t},\hat{y}_{t})
(xt,y^t) at a time step;

 SGD:move的方向与得到的gradient方向相反;
SGD:move的方向与得到的gradient方向相反;

 引入momentum的原因:
引入momentum的原因:




Optimizers: Real Application
- bert :ADAM
- Transformer :ADAM
- Tacotron :ADAM
- YOLO:SGDM
- Mask R-CNN:SGDM
- ResNet:SGDM
- Big-GAN:ADAM
- MAML:ADAM
结论:
Adam:fast training ,large generalization gap,unstable(训练速度快,泛化差距大,不稳定)
SGDM:stable ,little generalization gap,better convergence(稳定,泛化差距小,收敛性好)
结合Adam 和SGDM:SWATS(begin with Adam ,end with SGDM)
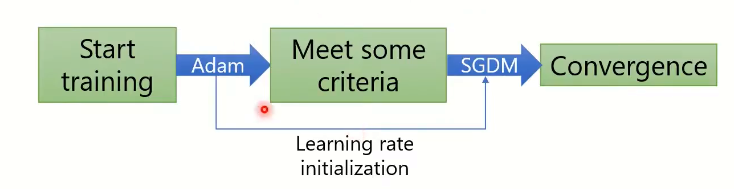 Improving Adam:
Improving Adam:
问题1:Adam在gradient大部分时候都很小的时候,就会被小的gradient牵着走;
解法1:减少较小的gradient造成的影响
AMSGrand only handles large learning rates
 问题2:Learning rates are either extremely large(for small gradients) or extremely small (for large gradients)
问题2:Learning rates are either extremely large(for small gradients) or extremely small (for large gradients)
解法2:
 ImprovingSGDM:
ImprovingSGDM:
问题:速度太慢
解决:
-
LR range test

-
Cyclical LR:

- SGDR

- One-cycle LR
 how to warm-up Adam?
how to warm-up Adam?

 比较:
比较:

Lookahead:universal wrapper for all optimizers
k step forward,1 step back
 lookahead的结果:
lookahead的结果:
 预测未来的算法:Nesterov accelerated gadient(NAG)
预测未来的算法:Nesterov accelerated gadient(NAG)

Adam in the future
- Nadam

optimizer:
 套件改进后:
套件改进后:

Smoething helps optimization:
- Shuffling(洗牌)
- Dropout
- Gradient noise
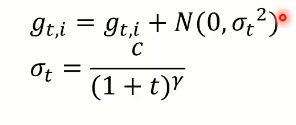
- Warm-up(热身)
- Curriculum learning(课程学习):Train your model with easy first,then difficult data.Perhaps helps to improve generalization.
- Fine-tuning(微调)
- Normalization(标准化)
 - Regularization(正则化)
- Regularization(正则化)
总结
SGD和Adam的衍生算法:
 两者的特点比较:
两者的特点比较:
 应用:
应用:















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









