







 本文详细介绍了神经网络训练中的优化器,包括SGD、SGD+Momentum、Nesterov Momentum、AdaGrad、RMSProp和Adam等。解释了各种优化器的工作原理、优缺点,并通过伪代码展示了它们的更新过程,帮助理解如何通过优化器改进梯度下降的效率和稳定性。
本文详细介绍了神经网络训练中的优化器,包括SGD、SGD+Momentum、Nesterov Momentum、AdaGrad、RMSProp和Adam等。解释了各种优化器的工作原理、优缺点,并通过伪代码展示了它们的更新过程,帮助理解如何通过优化器改进梯度下降的效率和稳定性。
训练神经网络—梯度下降优化器(optimizer)
文章目录
1、optimizer简介
定义
优化器其实可以看做我们的下山策略,其作用是通过改善训练方式来最小化(或最大化)损失函数E(x)。
分类
优化算法分为两大类:一阶优化算法和二阶优化算法,我主要介绍的是一阶优化算法。
一阶优化算法
一阶优化算法用时使用各参数的梯度值来最大或最小化损失函数f(x),常用的一阶优化算法是梯度下降。
二阶优化算法
使用了二阶导数(海森矩阵)来最小化或最大化损失函数,由于维数过高导致二阶导数计算成本很高,这种方法并不常用。
优化器伪代码
while True:
#其中evaluate_gradient是反向传播求得的梯度,loss_fun是前向传播的损失函数
#step_size是学习率
#the evaluate_gradient is the gradient which produced in backward prop
#the loss_fun means the loss function
#step_size is the learning rate
weights_grad = evaluate_gradient(loss_fun,data_weights)
weights += - step_size * weights_grad
2、SGD(随机梯度下降)
背景
原来,我们使用传统梯度下降的方式来进行参数优化,但是传统梯度下降具有自己的缺点:
①计算整个数据集梯度,但只会进行一次更新,因此在处理大型数据集时速度很慢且难以控制,甚至导致内存溢出。
②当我们希望在某一个方向优化的多一些时,很难做到,损失函数值会在梯度较大的方向上发生振荡,不能通过单纯减小学习率来解决,因为如果单纯减小学习率,则会让优化方向改变的更少。
③陷入局部最优点,鞍点(在高维空间中更普遍)。
Q&A
鞍点与局部最优点区别?
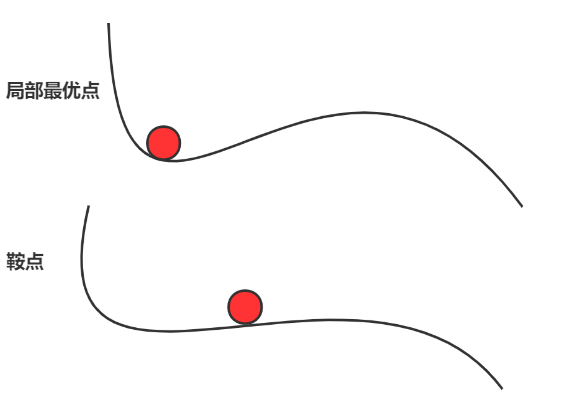
从上图可以看出局部最优点陷入“盆地”,而鞍点梯度为0。
损失函数:
L ( w ) = 1 N ∑ i = 1 N L i ( x i , y i , w ) L\left( w \right) =\frac{1}{N}\sum_{i=1}^N{\begin{array}{c} L_i\left( x_i,y_i,w \right)\\ \end{array}} \\ L(w)=N1i=1∑NLi(xi,yi,w)
梯度:
∇ w L ( w ) = 1 N ∑ i = 1 N ∇ w L i ( x i , y i , w ) \nabla wL\left( w \right) =\frac{1}{N}\sum_{i=1}^N{\nabla wL_i\left( x_i,y_i,w \right)} ∇wL(w)=N1i=1∑<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









