






文章目录
如愿了٩(๑❛ᴗ❛๑)۶2020.3报名,满分了hiahiahia~虽然4个模拟叭
注意事项
- PAT不允许用gets(),要用fgets(s, maxn, stdin); 读取字符串的长度比真正的长度多1,因此再减去1即可
- 如果给编号 0 n − 1 0~n-1 0 n−1,以±区分男女,注意 − 0 -0 −0的处理情况
- 给字符串可能不合法 如L1-059上半句可能少于3个字母
- 给的时间可能不按顺序,要看题
- 给的图可能不连通,要看题目有没有说明
- 超时可以考虑不用cin,string -> s.c_str();字符串比较:strcmp(a, b) < 0 -> a < b;strcmp(a, b) = 0 -> a = b
- 有些需要控制格式的可以先把所有结果弄到数组里再控制输出
- java大数的输入输出格式控制考前要熟悉一遍
- File -> new -> Java Project name:Main
- src -> new -> package name:Main
- Main_package -> new -> Java class -> name: Main 勾选:public static void main(Sting[] args)
- import java.util.*
- 全部的函数都用static
- BigInteger[] a = new BigInteger[1000];
- 大数x ,x = x.divide(BigInteger.one);一定要有等于号
- boolean
- 粘代码之前不要带package一行,但是写代码的时候需要有
- 滥用大数运算会T的(1136)……所以 用String,toString()等会更方便,参考1136的提交记录
- 模拟题要仔细读题
- 一些小点可能是0的问题 / 输出问题(逻辑控制 / 格式控制)天梯赛L1-009
- 最短路的优先队列是大根堆,一定要重载反着的比较函数
- 复习树上倍增LCA,1151
- 若 n < = 1 0 5 n<=10^{5} n<=105,可以考虑排序进行有序化
- 一定要注意 l o n g l o n g long long longlong的问题, 1 e 5 1e5 1e5的情况下 i ∗ i i*i i∗i会超过 l o n g l o n g long long longlong 1104
- The result must be rounded to the nearest integer that is no greater than the maximum length.这个不是四舍五入,是向下取整(no greater than)
- 复习一遍任意符号分割
- 需要注意数位个数,前面可能需要补0
- 有些模拟题里的分数,需要注意0分和-1(没有值)的区别
- debug可以找找所有可能的情况(等价类)
- 任何数不能被0整除
- 1125 如果ans.size() == 0 直接return不要最后再输出一个’\n’,否则格式错误
- 有些题目要模,如果有错可以再读一遍题,看清输入输出等
- BST二叉搜索树要注意题目中是左子树<=根 or 右子树<=根
- 1108 输出单词的复数形式还是单数形式(读题),且字符串表示的浮点数可能有多个小数点,所以一开始小数点pos初始化应设为n
- round down to the nearest integer 向下取整
- 关于树的问题,注意检查节点数n=1、2(两种:左子/右子)的情况 例:1110
- 如果给百分数,看清给的r是否带%,即给的是r 还是已经除过100的 r%
- 字符串到数字的映射统一从1开始
- 前导零处理 (参考1038) 注意全都是0的情况,只有一个0就不是前导零:CF记录:76967384
- 可能会爆long long(如进制转换、给的是比较大的数字),注意计算范围
- c++字符串大数加法:
int res[maxn];
string stringadd(string a, string b) {
int la = a.size(), lb = b.size();
reverse(a.begin(), a.end());
reverse(b.begin(), b.end());
if(la < lb) {
for(int i = 0; i < lb - la; i++) a += "0";
} else {
for(int i = 0; i < la - lb; i++) b += "0";
}
int ma = max(la, lb);
for(int i = 0; i < ma + 5; i++) {
if(i >= ma) {
res[i] = 0;
continue;
}
res[i] = 0;
int now = a[i] - '0' + b[i] - '0';
res[i] = now;
}
for(int i = 0; i < ma; i++) {
int c = res[i] / 10;
res[i] = res[i] % 10;
res[i + 1] += c;
}
if(res[ma] != 0) ma++;
string ret = "";
for(int i = ma - 1; i >= 0; i--) {
ret += res[i] + '0';
}
return ret;
}
- 超时可以关同步统一用cin i o s : : s y n c w i t h s t d i o ( f a l s e ) ; ios::sync_with_stdio(false); ios::syncwithstdio(false);
- 段错误一般都是开小了 / 爆栈了,注意有些是查询的大小不是所有的大小 1039;pat手动加栈不好使:
#pragma comment(linker,"/STACK:1024000000,1024000000"),所以遇到dfs数据大的情况改成bfs 1091 - 类似1022这种归类的题目都用map将下标和名称对应起来,下标从1开始,不要用0,由此可以区分“不存在”这种情况
- cin 和 getline(cin, str)之间要用cin.get() <==> getchar()
- 负数不能直接求gcd,先换成绝对值再求
暴力思维
- 结构体应用 1006 1012 1025 1028 1036 1055 1062 1075(细节题,多次提交满分计数会出错) 1083 1084 1141 1137(四舍五入) 1109(注意题目说的是先从后排开始排,因此如果所有人身高都一样,不能先划分好每排的人再确定位置,因为要求名字小的先排(名字小的在后排)) 1080(排序以后id和下标会变化,因此要注意存一个mp对应,看一次最后提交)
- 括号匹配一定用栈,只有一种括号才用计数器;配对的这种:如果消除掉中间的一对可以减小问题规模,就可以用栈实现
- 模拟,注意边界如0等 1001 1005 1008 1011 1035 1041 1042 1046 1047 1048 1050 1054 1056 1060(将一个数转化为科学计数法,注意0的情况) 1061(读题要死) 1063(求交集和并集) 1069 1082(将数字转化为拼音) 1092 1120 1116 1124 1128(虽然数据范围很大,但是并不卡 O ( t ∗ n 2 ) O(t*n^{2}) O(t∗n2) ) 1132(注意除零错误) 1140 1125 1108(注意如果只有一个合法数组要输出number而不是numbers) 1105(找规律,先变位置再填数) 1149 1153(日期到数字的映射要从1开始才能表示不存在的日期) 1039 1022
- 多项式加法、乘法 1002 1009
- for控制图案 1031
- 进制转换 1010(二分找进制) 1019(判回文)1027 1100(理解题意,只有两位,并且当结果是13、26等13的倍数时,只输出高位不输出低位的tret)
- 用栈:10进制 -> r进制:短除法,一直不停的除,余数对应的字符(如16进制可能有字母)的逆序输出;r进制 -> 10进制:每一位系数乘 r i r^{i} ri 的和
- 注意结果为0的时候
- 进制必须比所有字符都大(1010要判断)
- 可能转换成10进制以后的结果会爆long long 注意考虑判断(1010)
stack<int> st;
char digit[] = {'0', '1', ……};
while(n > 0) {
st.push(digit[n % base]);
n /= base;
}
//main
while(!st.empty()) {
printf("%c", st.top());
st.pop();
}
- 二分 1044 1085 1117(给出N天 要求出一个最大的E天,每天骑行的距离都大于E)
- 高精度 1023(大数加法模拟) 1058(不同进制) 1065(判断溢出即可,但是若要求出是几,就用java大数叭) 1136*第十次加法成功也算失败,因为第一次判n是不是回文数也算一次迭代,先判断,再求和(注意1也要输出为00001,因此可以用string作为输入,输出按照string就可以保留0,构造大数时以string作为参数)
- 排序 1089(判断采用什么排序方法) 1098(同1089)
- 插入排序:前面升序,后面两序列一样
- 归并排序 1029(找中位数)
- 快速排序 1101
- 尺取法/二分 1085(先排序,有序化会更好考虑)
- 思维:1104(求一个数列所有子段的和:统计每个数出现的次数) 1113 1144 1049(规律:计算每一位对应的1的个数,然后相加,每一位的1的计算情况分三种情况)
- 时间处理:1026 1014 1017 1016
dp
- 最大子段和 1007
- 硬币问题(类似01背包) 1068
- 1045:dp[i] = 以a[i]结尾的(包括a[i])最长值,设a[i]是第x个喜欢的数,则a[i]可以接到 a[1, i - 1] 里,喜欢的数为[1, x]的所有位置后面。
贪心
- 1037
- 1033 注意贪心策略
- 可分割背包 1070
- 区间dp(伪) 1125(区间有相邻要求考虑区间dp,否则考虑哈夫曼树)
- 因为区间dp要求是相邻的区间,但是该题没有相邻的要求,所以该题形式化后为:求一组 a , b , c , … n a,b, c,…n a,b,c,…n 使得 a 2 n − 1 \frac{a}{2^{n-1}} 2n−1a + b 2 n − 1 \frac{b}{2^{n-1}} 2n−1b + c 2 n − 2 \frac{c}{2^{n-2}} 2n−2c + d 2 n − 3 \frac{d}{2^{n-3}} 2n−3d + …… + n 2 \frac{n}{2} 2n 最大,两边乘 2 n − 1 2^{n-1} 2n−1得: a + b + 2 ∗ c + 4 ∗ d + … + 2 n − 2 ∗ n a + b + 2*c + 4 * d+…+2^{n - 2}*n a+b+2∗c+4∗d+…+2n−2∗n最大,即最大的往后面放(×)因为不一定是把一个新的往一个集合里加,而是可能构造好的一组和构造好的另一组放在一起最优,所以上述方法错误
- 哈夫曼树即可(√):
因为所有长度都要串在一起,每次都等于(旧的绳子长度+新的绳子长度)/2,所以越是早加入绳子长度中的段,越要对折的次数多,所以既然希望绳子长度是最长的,就必须让长的段对折次数尽可能的短。注意k-哈夫曼树:每一次合并会减少K - 1堆,所以只要n - 1是k - 1的倍数就可以了,用0补齐
搜索
- 隐式搜索bfs + 判回文 1024(注意用字符串存,可能爆long long)
- 1053 给一棵树,求所有根到叶子的路径,使其路径和为给定值s(dfs,剪枝?剪了一点点)
- 1091 三维连通块大小(注意条件:mp[i][j][k] == 1 && !vis[i][j][k]),注意层、长、宽的对应 不能dfs因为1e7的数量爆栈也会段错误,改成bfs
- 1103 因子分解
字符串
- 马拉车求最长回文子串 1040
- 找最长公共后缀 1077(暴力即可 / 可以尝试逆序字典树)
- 类似统计对数的方法 1093(求有几个特定的子序列,要模)
- 按非数字字母分割字符串 1071
- 排列字符串使得字典序(数字)最小(重载cmp) 1038
- 处理前导零:
//1038
int lead = 1;
int flag = 0;
for(int i = 0; i < s.size(); i++) {
if(lead) {
int len = s[i].size();
string now = "";
for(int j = 0; j < len; j++) {
if(s[i][j] != '0') {
lead = 0;
now = s[i].substr(j, len - j);
flag = 1;
break;
}
}
cout << now;
} else {
cout << s[i];
flag = 1;
}
}
if(!flag) printf("0");
puts("");
数论
- 筛素数,颠倒顺序 1015
- 根号判素数 1152 (注意0 和 1)
- 质因子分解(唯一分解定理) 1059
void decompose(ll x){//唯一分解定理
for(ll i = 2; i * i <= x; i++){
if(x % i == 0){
fa[k].factor = i;
while(x % i == 0){
x /= i;
fa[k].Count++;
}
k++;
}
}
if(x > 1){
fa[k].factor = x;
fa[k].Count = 1;
k++;
}
}
- gcd 1088(分数加减乘除,注意看题,细节处理) 1081(分数相加:注意负数问题,还有全是0的情况)
- 因数分解 1096(模拟) 注意素数的情况(即只有一个不为1的因子:n本身)
数据结构
哈希
- 构造哈希表,二次探测 1078(注意题意,如果n不是素数才找大于他的素数,且不考虑往前返) 1145(注意查找的时候,对于没有的数:①若探测到hash[pos] == -1(pos存在),则就是没有;②step都探测完了(所有pos上都有数)也没有)
- 二次探测:若当前key与原来key产生相同的哈希地址,则当前key存在该地址后偏移量为[1,2,3…size - 1]的二次方地址处:
注意 是(key + step * step) % size 而不是(key % size + step * step) - 只带正增量:step∈[1, msz) (msz是哈希表的表长)
- 二次探测:若当前key与原来key产生相同的哈希地址,则当前key存在该地址后偏移量为[1,2,3…size - 1]的二次方地址处:
for(int i = 0; i < n; i++) {
int val; scanf("%d", &val);
int res;
int flag = 0;
for(int j = 0; j < msz; j++) {
res = (val + j * j) % msz;
if(hashar[res] == -1) {
hashar[res] = val;
flag = 1;
break;
}
}
if(!flag) printf("%d cannot be inserted.\n", val);
}
链表
- 模拟链表 1032 1052(给出的节点不一定都在链表上,需要遍历一遍求出链表上的值、注意空表) 1074 1133 1097
栈
- 计算中缀表达式:可以在表达式前后加一个’$’,就会容易操作:操作符栈op和操作数栈num,扫描到一个数,就入num;一个符,与op栈顶比较,若op栈顶优先级高,则出栈计算;否则该符入栈;当‘)’遇到‘(’时,中间的都已经计算完了,因此直接op.pop()弹出左括号,扫描位置++脱去右括号
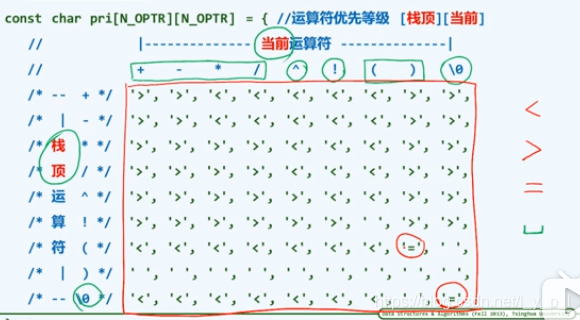
- 逆波兰表达式RPN:不用括号就能表示优先级
- 只有一个操作数栈num,每遇到操作数就入栈
- 遇到一个操作符op,随即执行运算并将结果压回占栈内
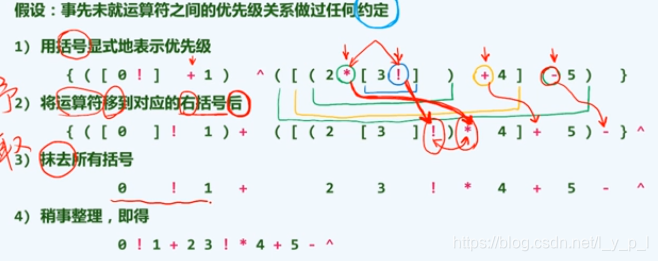
- 转换算法:先将所有的运算都加入括号以明确所有的运算优先级,然后将每一个操作符移到它被界定的那对括号的右括号的后面:所有操作数在RPN的相对次序=在中缀表达式中的次序
- 给一个入栈序列,判断某序列是否为出栈序列 1051
-
栈混洗:两个对顶栈A、B,借助一个中间栈S将A中的元素全部转移到B中,只允许两种操作:将A的顶元素压入S、将S的顶元素压入B
-
栈混洗的个数为卡特兰数: ( 2 n ) ! ( n + 1 ) ! n ! \frac{(2n)!}{(n+1)!n!} (n+1)!n!(2n)!
-
若把 ′ ( ′ '(' ′(′ 看做S的一次入栈, ′ ) ′ ')' ′)′ 看做S的一次出栈,栈混洗 一 一对应一种相同长度的合法括号序列
-
栈混洗的甄别:任意三个元素的甄别与其他元素无关,对于任意三个整数入栈次序为: i < j < k i<j< k i<j<k,若栈混洗是 … k , … , i … , j … …k, …,i…,j… …k,…,i…,j…,则一定不是(充要条件:312模式):因此可以
- 对于一对 i < j i< j i<j,检查结果中没有 j + 1 , i , j j + 1, i , j j+1,i,j 即可 O ( n 2 ) O(n^{2}) O(n2)
- 或者模拟栈混洗,贪心:对顶栈A(原始入栈序列)、B(结果序列),中间栈S,i指B,j指A,i = j = 1;若栈里有元素且B[i] == st.top(),i++,st.pop();否则就贪心的从A里面一直放元素到S中,直到 j > n || 栈容量不足 -> 不合法;栈顶等于b[i] -> 合法
-
int a[maxn], b[maxn];
stack<int> st;
int main() {
int cap, n, k;
scanf("%d%d%d", &cap, &n, &k);
for(int i = 1; i <= n; i++) a[i] = i;
for(int t = 0; t < k; t++) {
while(!st.empty()) st.pop();
for(int i = 1; i <= n; i++) scanf("%d", &b[i]);
int i = 1, j = 1;
int ok = 1;
while(i <= n) {
if(!st.empty() && b[i] == st.top()) {
i++;
st.pop();
} else {
int flag = 0;
while(j <= n && st.size() < cap) {
st.push(a[j++]);
flag = 1;
if(st.top() == b[i]) break;
}
if(flag == 0) {
ok = 0;
break;
}
}
}
if(ok) puts("YES");
else puts("NO");
}
return 0;
}
并查集
- 1114(求多个家族的财产) 1118 1107 1034(维护集合的点的个数和边权和)
差分数组
- 区间修改,单点查询 :差分数组(+树状数组) 1095(时间映射->最多1e5)
树和森林(树是为了综合链表和数组的优点,查找、插入均快速)
- 边数为顶点数 - 1 ( n n n与 m m m是同阶的)
- 给二叉树的前序和中序,求后序遍历……类似
- 1020
- 1102(颠倒的中序:右根左)
- 1138(n很大,不要存)
- 1043(复习代码,注意镜像的时候,中序的右半边和前序的左半边对应,xx的值要求对)
- 1086(按照非递归方式给二叉树的中序遍历,求后序遍历:变相的给了先序:push的数字序列;和中序:pop的数字序列,即先序+中序确定一棵树,再算出后序)
- 1127(之字形bfs:两个栈)
- 1130(表达式二叉树求中序遍历,对于一个节点x: ‘(’ -> x.lf -> x -> x.rt -> ‘)’;找谁是根:没有父亲的编号即为根。该种读入形式可以参考该题代码)
- 1119 (给先序、后序遍历,确定树是否唯一,输出随意一个中序遍历)
- 判断是否为红黑树 1135(可能不是BBST,因此要判断能否建树成功;注意题目中的黑深度是:每个节点的左右子树中黑色节点的个数相同)
-
红黑树:
-
一种BBST -> 中序遍历是排好序的
-
任何动态操作使树的拓扑结构变化(即旋转)都不超过 O ( 1 ) O(1) O(1)
-
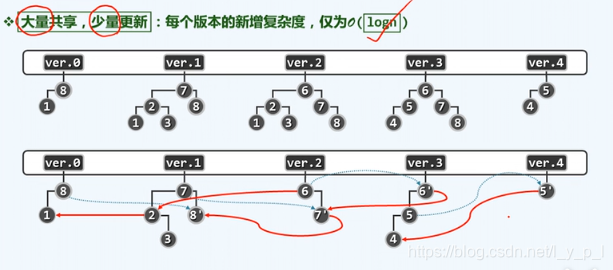
*持久性结构:能支持查看历史版本 或 对历史版本做修改 -> 利用相邻版本的关联性:和上一版本相比,有相同的子树就直接指过去,没有就新建
-
结构:引入真二叉树:增加外部节点NULL(第4条:不计外部节点,计根)

- 提升变换(使红点与父亲等高)后,所有底层节点都变为平齐的高度
-
- 用结构体表示的树状关系(家谱、供应链……),dfs + bfs 1004 1094 1090 1106 1079
- 无根树找最深的根 + 判森林 1021
- 判断是否为完全二叉树 1110(bfs中用两个bool记录有没有中间有空余的形式,注意数每层的个数是不能确定的有无空余的情况 两个反例见提交记录)
- 给一个序列,求唯一的完全二叉搜索树的bfs 1064 1099(给树的形状,建立二叉搜索树)
- 完全二叉搜索树要求左子树小于根,右子树大于等于根(看题),除最后一层外,每一层都必须铺满,最后一层要从左到右铺,中间不能有空缺;搜索树的中序遍历是一个有序数组 解法:二叉树的中序遍历建树即为输出
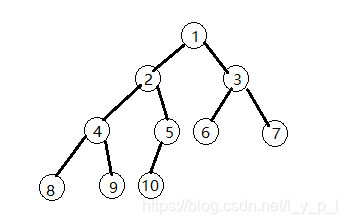
因为完全二叉树的层次遍历标号如上;而使用左儿子为 x ∗ 2 x*2 x∗2,右儿子为 x ∗ 2 + 1 x*2+1 x∗2+1的编号方法也如上,因此直接中序方法建树即可
- 完全二叉搜索树要求左子树小于根,右子树大于等于根(看题),除最后一层外,每一层都必须铺满,最后一层要从左到右铺,中间不能有空缺;搜索树的中序遍历是一个有序数组 解法:二叉树的中序遍历建树即为输出
- 像空二叉搜索树中依次插入(从根开始左右下放)节点,求树的遍历 1115(默认根是输入第一个数,注意是左子树<=根)
- 模拟实现AVL树左旋右旋(zig、zag)操作 1066:
-
插入操作:按树左右下放即可
-
删除操作:
- 被删除的点若只有一个孩子,则用他的孩子替换他即可
- 若有两个孩子,要找到根节点的直接后继(中序遍历的下一个数)
x
x
x(
x
x
x只可能有右孩子,不会有做孩子,因为是中序的下一个,如果有左孩子则还会往下,直接后继就不会是
x
x
x),用
x
x
x替换他,然后将原来
x
x
x的右孩子替换他即可
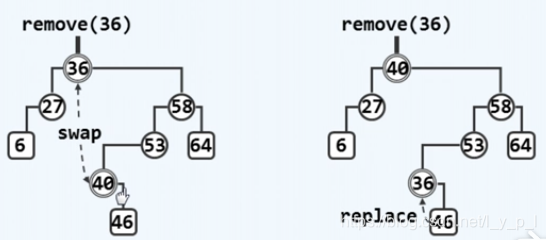
-
对于新插入的点,对于他的第一个不平衡的祖先(沿着到根的路径),进行操作后,所有祖先都会平衡;也可能没有祖先失衡,整个树还是平衡的:从被插入节点的祖父开始
-
对于新删除的点,其更高的祖先仍可能失衡,需要 O ( l o g n ) O(logn) O(logn)次调整:从被删除节点的父亲开始
-
zig(v)(v右旋):v的左子节点c变为根,v变为c的右子节点,c原来的右子节点变为v的左子节点
-
zag(v)(v左旋):v的右子节点c变为根,v变为c的左子节点,c原来的左子节点变为v的右子节点
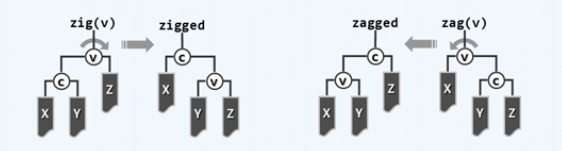
-
zagzag(g) 连续三代全都向右;zigzig(g) 连续三代全都向左
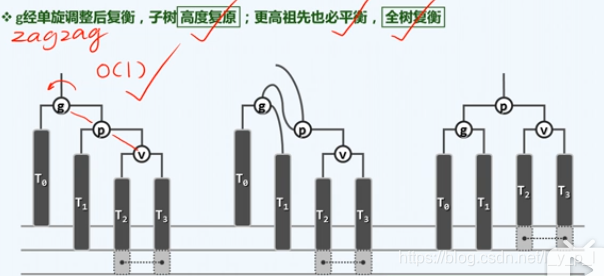
-
zigzag:之字形(图为zigzag),先zig§,再zag(g)
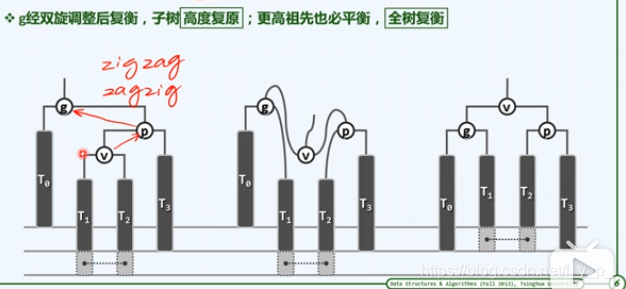
-
堆
-
用set<结构体>模拟 1129(求当前出现次数最多的k个数)
-
对顶堆+栈:求动态中位数 1057
-
给一个完全二叉树,判断是否为堆/大根堆/小根堆 1155
-
构造(判断)完全二叉堆 1147(完全二叉树的层次遍历<=>秩)
-
堆:逻辑上是完全二叉树;物理上是一个数组:1为根,x2为左孩子, x2+1为右孩子
- 完全二叉树:逻辑节点与物理元素在数组中的秩以层次遍历序列相对应
- 注意与二叉搜索树的区别:二叉搜索树不一定是完全树,且左儿子、右儿子、根均有关系
- 任何一个点的值都<=他父亲: x / 2 x/2 x/2(大根堆)
- 获取最值:堆顶(tree[1])
- 插入:插入在数组的最后<==>在完全二叉树的末尾拓展一个节点,然后上滤进行合法性的调整
- 上滤:原因:新插入的节点值>父亲,一直调整到合法(可能成为堆顶)
- 删除(最大元):删除堆顶,以数组最后一个元素代替,下滤进行合法性的调整
- 下滤:当前节点的值 < 至少一个孩子,则与左右孩子中更大的进行交换(保证互换后当前节点一定>=两个孩子)
- 批量建堆:
- 若依次插入每一个, O ( n l o g n ) O(nlogn) O(nlogn)
- 对于一个初始数组,自下而上,自右而左的,从第 ⌊ n / 2 ⌋ \left \lfloor n/2\right \rfloor ⌊n/2⌋个节点(秩从1开始计数)开始,对每一个节点下滤,直到1号即根节点也下滤完成
- 用完全二叉堆优化选择排序
- 堆排序(就地算法):
- 将待排序区间建堆(批量建堆 O ( n ) O(n) O(n))
- 反复交换堆顶和待排序的位置的元素(即将堆顶放在该数组的尾部),更新堆的区间长度,下滤当前的堆顶

- 堆排序(就地算法):
-
二叉搜索树上的LCA 1143 1151(二叉树的LCA ==注意该题的写法:用一个新的局部变量x表示当前idx,不要用全局变量tot == 给一棵树如果说保证惟一的,说明没有相同值)
- 将两个点向上的链找到,第一个相同的即为LCA -> 超时
- 树上倍增 / (RMQ查询)
- 注意根的下标是1,根的父亲下标为0,否则会访问下标数组为-1的元素,造成段错误
int in[maxn], pre[maxn];
struct node {
int val, l, r, f;
} tree[maxn];
int tot;
map<int, int> idx;
int build(int prel, int prer, int inl, int inr, int fa) {
tree[++tot].val = pre[prel];
int x = tot;//注意这里不要用全局变量
tree[x].f = fa;
idx[pre[prel]] = x;
int pos = -1;
for(int i = inl; i <= inr; i++) {
if(in[i] == pre[prel]) {
pos = i;
break;
}
}
if(inl <= pos - 1) {
int xx = pos - inl + prel;
tree[x].l = build(prel + 1, xx, inl, pos - 1, x);
} else tree[x].l = -1;
if(pos + 1 <= inr) {
int xx = pos - inl + prel + 1;
tree[x].r = build(xx, prer, pos + 1, inr, x);
} else tree[x].r = -1;
return x;
}
图
环
- 暴力找符合条件的环(的个数) 1139(离散化)
顶点覆盖
- 判断顶点覆盖(一组点覆盖了所有的边):1134
图的遍历
- 询问某节点的L层内的点有几个 1076(包含层这样概念的一定用bfs,因此dfs会有回向边,即可能某一点有短的路,但是dfs时走了长的,vis后就不会再访问了,造成错误) bfs注意先使vis=1再入队
最短路
- 单源最短路 1030(两种边权)
- 最短路计数 1003 c n t [ v ] + = c n t [ u ] cnt[v] += cnt[u] cnt[v]+=cnt[u] 最短路维护点权、边权
- dij + dfs 1018
- 1087(最短路,最短路计数、若有多条取点权和最大的,若仍有多条求途径的点的平均权值最大的(平均点权值最大是满足最优子结构的,因此可以不用dfs:如果点权和一样大,那么就选择路径上结点个数少的路径),输出路径)
- 有环有向图的最短路,并输出路径 1131(处理转站的情况)
最大团
- 暴力枚举判定最大团、团 1142(暴力)
连通性(并查集)
- 求连通块个数 1013
图着色
- 判断是否为合法的图着色序列 1154(离散化, 图可能不连通)
拓扑排序
- 给一个有向图,判断所给序列是否为拓扑排序 1146 只需要依次判断当前点的入度是否为0即可
欧拉路、哈密顿路与TSP
- 判断TSP 1150(TSP环首先要判断路上的个数是否为n,再判首尾是否相同)
- 每条边经过一次的路径是欧拉路,每个点只经过一次是哈密顿路
- 判断哈密顿回路 1122
- 判断欧拉路、欧拉回路 1126
- 首先图必须是联通的,用并查集判即可
- 无向图欧拉回路:所有点度数都为偶数
- 无向图欧拉路径:两个点(或0个点)度数为奇数,其余点(或所有点)度数为偶数
- 有向图欧拉回路:所有点入度=出度
- 有向图欧拉路径:一个点入度=出度+1,一个点出度=入度+1,其余点(或所有点)入度=出度
- 查找该路径:
//已知存在欧拉路径,找该路径
void dfs(int u){//s1~sn中存储的是欧拉路径上的点序列
for(int v=1;v<=n;v++){
if(mp[u][v]>0){
mp[u][v]--;
mp[v][u]--;
dfs(v);
}
}
s[temp--]=u;
}














 4529
4529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









