







本文对应原书中第七章。其中的知识对于进一步调优MapReduce非常重要。我们先介绍MapReduce作业的运行过程,再介绍它的容错机制,然后会介绍其中的Shffle和Sort过程。
MapReduce工作过程
我们先用一张图来对整个过程有一个整体把握:
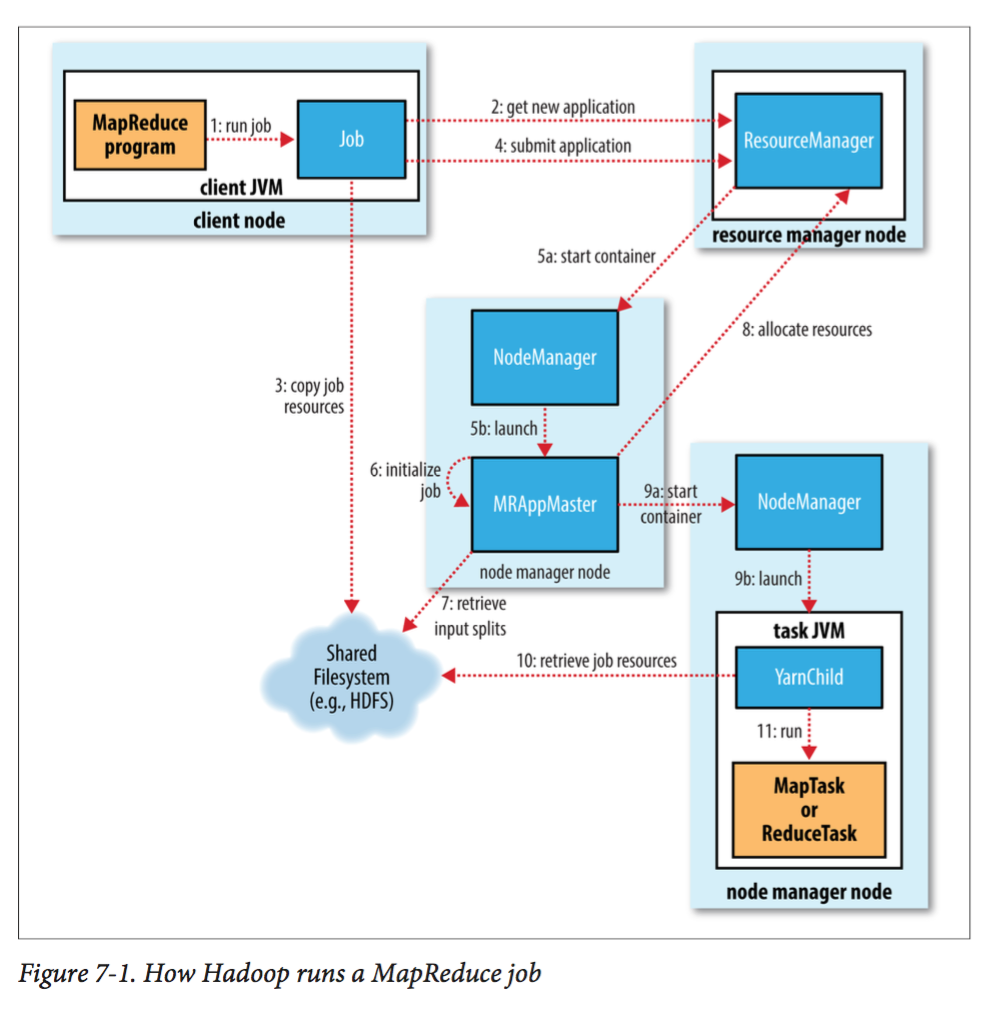
这里面有5个组件:
- client:提交MR作业
- Yarn Resource Manager:协同调度集群的全部资源
- Yarn Node Manager:启动和监视集群中的容器
- MapReduce Application Master:协同MR的tasks。它们都运行在由resource manager分配然后由node manager管理的容器中。
- 分布式文件系统
一个MR作业由如下几个过程组成:
作业提交
Job实例调用submit()方法提交一个作业,这个方法会创建一个JobSubmitter实例(图中第1步)。提交完作业后,waitForCompletion(如果代码中调用了的话)方法会每隔一秒查看作业的状态并且将变化(如果有的话)打印到终端。
在JobSubmitter中会做如下事情:
- 向Yarn RM中请求一个新的应用ID,分配给这个MR作业(第2步)。
- 检查作业的输出需求。例如,如果输出目录已经存在,则不提交作业并且抛出一个异常。
- 计算作业的输入切片(准确说是切片信息)。如果切片不能被计算出来(例如输入目录不存在),同样作业不会被提交并且发出一个异常。
- 拷贝各种作业资源(例如作业的jar包,配置文件,切片信息等)到分布式文件系统下的一个被命名为job ID的目录下(第3步)。
- 调用submitApplicatiion方法提交作业到Yarn RM(第4步)。
作业初始化
当Yarn RM收到了submitApplicatiion方法中的请求。它将这个请求交给Yarn调度器。调度器会分配一个容器,然后Yarn RM在这个容器中启动一个AM(在NM管理下)(5a和5b)。
AM是一个java应用,它的主类叫做MRAppMaster。这个类会创建一些记录对象,用来获取来自任务的报告(第6步)。然后会从分布式文件系统中获取切片信息(第7步)。为每一个分片创建一个map任务,而reduce任务的个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









