






使用python的xpath库来对链家网的二手房数据进行爬取,通过数据预处理和数据清洗,最后做出线性回归模型,个人兴趣,仅供参考。
from lxml import etree
import requests
import csv
from time import sleep
f = open('ZheJiang.csv', mode='w', newline='', encoding='utf-8-sig')
csv_writer = csv.writer(f)
csv_writer.writerow(['名称','地址', '大小', '价格','平方价格'])
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}
def grt_info(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
tree = etree.HTML(rep.text) # 数据解析
list = tree.xpath('//*[@id="content"]/div[1]/ul/li')
#print(list)
for i in list:
try:
data=i.xpath('.//div[1]/div[1]/a/text()')[0]
a= i.xpath('.//div[1]/div[2]/div/a[2]/text()')[0]
b= i.xpath('.//div[1]/div[3]/div/text()')[0]
c= i.xpath('.//div[1]/div[6]/div[1]/span/text()')[0]
d= i.xpath('.//div[1]/div[6]/div[2]/span/text()')[0]
print(d)
csv_writer.writerow([ data,a,b,c,d])
except:
pass
print(data)
for i in range (1,101):
url='https://sx.lianjia.com/ershoufang/pg%25s/'%i
grt_info(url)
数据爬取完成后,使用pandas模块对zhejiang.csv文件导入
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import numpy as np
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
warnings.filterwarnings('ignore')
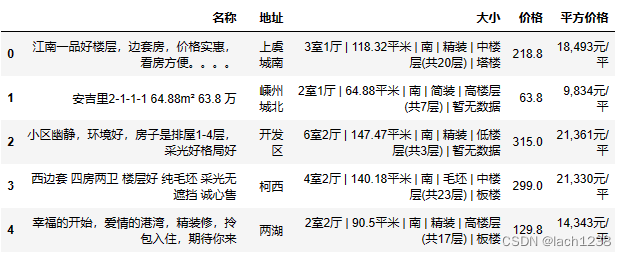
df1 = pd.read_csv('zhejiang.csv')
df1.head()
.head()输出前五条数据,确保数据爬取成功。
def split_data(data, sep=' | '):
split_data = data.split(sep)
return split_data
df = pd.read_csv('zhejiang.csv')
df[['房间规格', '平方', '位置', '装修', '楼层', '样式']] = df['大小'].apply(split_data).tolist()
df = df.drop('大小', axis=1)
df = df.drop('名称', axis=1)
# 将 "平方" 列中的 "平米" 字符替换为空字符串
df['平方'] = df['平方'].astype(str)
df['平方'] = df['平方'].str.replace('平米', '')
# 将 "平方" 列转换为浮点数
df['平方'] = pd.to_numeric(df['平方'], errors='coerce')
df['平方价格'] = df['平方价格'].astype(str)
df['平方价格'] = df['平方价格'].str.replace('元/平', '')
df['平方价格'] = df['平方价格'].str.replace(',', '')
#df['平方价格'] = pd.to_numeric(df['平方价格'], errors='coerce')
#df.fillna(0, inplace=True)
df['平方价格'] = df['平方价格'].astype(float)
df.head()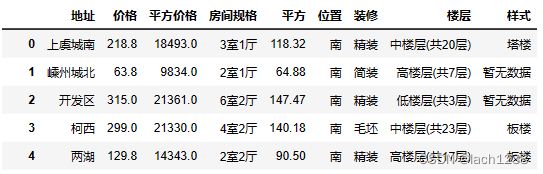
数据拆分清洗完毕后,通过箱型图对装修风格的不同价位可视化
sns.boxplot(x="价格",y="装修",data=df[(df.装修=='精装')],orient="h",palette="magma")
sns.boxplot(x="价格",y="装修",data=df[(df.装修=='简装')],orient="h",palette="magma")
sns.boxplot(x="价格",y="装修",data=df[(df.装修=='毛坯')],orient="h",palette="magma")
sns.boxplot(x="价格",y="装修",data=df[(df.装修=='其他')],orient="h",palette="magma")使用机器学习库对房间规格进行热编码后与价格对比
df['房间规格'] = df['房间规格'].astype('category')
df['位置'] = df['位置'].astype('category')
df['装修'] = df['装修'].astype('category')
df['价格'] = pd.to_numeric(df['价格'], errors='coerce')
df['平方价格'] = pd.to_numeric(df['平方价格'], errors='coerce')
df['平方'] = pd.to_numeric(df['平方'], errors='coerce')
df = df.dropna(subset=['价格'])
# 对“房间规格”进行独热编码
df_encoded = pd.get_dummies(df['房间规格'], prefix='房间规格')
# 合并编码后的数据和数字数据
df_new = pd.concat([df_encoded, df[[ '价格']]], axis=1)
# 定义输入特征和标签
X = df_new.iloc[:, :-1].values
y = df_new.iloc[:, -1].values
# 划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估预测结果
from sklearn.metrics import mean_squared_error, r2_score
print('MSE: %.2f' % mean_squared_error(y_test, y_pred))
print('R^2: %.2f' % r2_score(y_test, y_pred))
# 可视化预测结果和真实结果# 对“房间规格”进行独热编码
df_encoded = pd.get_dummies(df['装修'], prefix='装修')
# 合并编码后的数据和数字数据
df_new = pd.concat([df_encoded, df[[ '价格']]], axis=1)
# 定义输入特征和标签
X = df_new.iloc[:, :-1].values
y = df_new.iloc[:, -1].values
# 划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估预测结果
from sklearn.metrics import mean_squared_error, r2_score
print('MSE: %.2f' % mean_squared_error(y_test, y_pred))
print('R^2: %.2f' % r2_score(y_test, y_pred))
# 可视化预测结果和真实结果最后drop去掉无用值后对二手房价的模型有个简单的建立,注意:影响房价的因素有很多,本篇仅个人学习中的一个小作品,希望大家多多包涵
df = df.drop('地址', axis=1)
df = df.drop('位置', axis=1)
df = df.drop('楼层', axis=1)
df = df.drop('样式', axis=1)
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), ['装修', '房间规格'])], remainder='passthrough')
X = np.array(ct.fit_transform(df))
# 定义标签
y = np.array(df['价格'])
# 划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估预测结果
from sklearn.metrics import mean_squared_error, r2_score
print('MSE: %.2f' % mean_squared_error(y_test, y_pred))
print('R^2: %.2f' % r2_score(y_test, y_pred))
# 输出模型的系数和截距
print('Coefficients:', model.coef_)
print('Intercept:', model.intercept_)














 9761
9761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









