







目录
注意:4.2.1中已经不支持 group( db.users.help() 查询没有group函数 )
D:MapReduce (非常适用于大数据分析,如基于java的hadoop)
一、课程大纲
- MongoDB 条件查询
- 映射 Project 与 过滤
- 去除重复 Distinct
- 分组统计 Group

二、MongoDB 条件查询
1. 制造 MongoDB 测试数据
db.users.insert({name:'frank',age:16,city:'beijing' )
db.users.insert({name:'xulei',age:17,city:'hangzhou' )
db.users.insert(name:'frankxulei'age:18,city:'shanghai')
db.users.insert({name:'alibaba',age: 25,tags:['java','mysql','mongodb'],city:'hangzhou'})
db.users.save()
db.users.insertOne()
db.users.insertMany()2. MongoDB 数据查询 与 SQL对应关系
| MongoDB | SQL语句 | 说明 |
| find() | all | |
| find({}) | all | |
| find({fage:18}) | select * from users where age =18 | |
| $lt:18 | where age<18 | less rhan |
| $gt:18 | where age>18 | greater than |
| $lte:18 | where age<=18 | less rhan or equal |
| $gte=:18 | where age>=18 | greater than or equal |
| $in:[18,19] | where age in(18,19) | |
| $or:[{age:18}, { name:' frankxulei'}] | where age=18 or name= 'frankxuleil' | |
| {age:18,name:'frankxulei'} | where age = 18 and name= 'frankxulei' | |
| ({“name”:/.*阿里.*/}) | select * from users where name like “%阿里%” |
3. MongoDB 查询运算符

4. MongoDB 数据查询、条件查询、过滤

5. MongoDB 条件查询命令

6. MongoDB 数据查询数组条件
A. 精确匹配数组元素:
db.users.find( { tags:["java","mongodb"]})- 描述:查出所有数组中包含java和mongodb的文档,且有先后顺序

B. 无顺序 and 精确 匹配
db.users.find( { tags:{$all:["java","mongodb"]}})- 描述:查出所有数组中包含java和mongodb的文档
![]()
C. 至少匹配一个
db.users.find( { tags:"java"})- 描述:查出所有数组中包含java的文档

D. 组合条件满足一个条件过滤
db.users.find( { age: { $gt: 15, $lt: 20 }})- 描述:查找 age ∈(15,20)

E. $elemMatch操作符查询内嵌文档
- 作用:用于查同于个元素中的键值组合,
- 针对 LIst<object> 查询
- 详情请参考
db.test.insert({"id":1, "members":[{"name":"BuleRiver1", "age":27, "gender":"M"}, {"name":"BuleRiver2", "age":23, "gender":"F"}, {"name":"BuleRiver3", "age":21, "gender":"M"}]});
- $elemMatch + 同一个元素中的键值组合
db.test.find({"members":{"$elemMatch":{"name":"BuleRiver1", "age":27}}});- $elemMatch+不同元素的键值组合(查不出结果)
db.test.find({"members":{"$elemMatch":{"name":"BuleRiver1", "age":23}}});F. 正则:模糊查询:/.* .*/
db.users.find( { name:/.*feng.*/ })- 描述:查找 name 包含 feng 的文档
![]()
G. 正则:以xx开头:/^ .*/
db.users.find( { name:/^zhang.*/ })- 描述:查找 name 以 zhang 开头的文档

H. 正则:以xx结尾:/.* $/
db.users.find( { name:/.*g$/ })- 描述:查找 name 以 g 结尾的文档

7. MongoDB 数据查询嵌套数组文档
- 造数据,其中 {}表示新的文档
db.users.insert([
{name:'ali',age:51,address:{country:'china',city:'beijing',district:'haidian',dd:'zhongguancunroad 10'}}
{name:'baby',age:51,address:{country:'china',city:'hangzhou',district:'xihu',dd:'zhongguancunroad 10'}}
{name:'baby2',age:17,address:{country:'china',city:'hangzhou',district:'xihu',dd:'zhongguancunroad 10'}}
{name:'baby3',age:18,address:{country:'china',city:'hangzhou',district:'xihu',dd:'zhongguancunroad 10'}}
{name:'xiaowang',age:19,address:{country:'china',city:'shanghai',district:'pudong',dd:'sjtu park 10'}}
])
db.orders.insert([
{name:"frank",items:[{title:"mongodb",count:1},{title:"java",count:3}]},
{name:"xulei",items:[{title:"iphone 8p",count:2}]},
{name:"wangsicong",items:[{title:"RR",count :1},{title:"Benz",count:10}]}]);A. 文档嵌套:单条件查询
db.users.find({"address.country":'china'})- 描述:查 "address.country"='china' 的文档
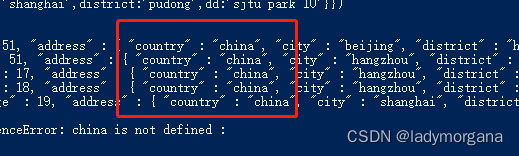
B. 文档嵌套:多条件查询(and)
db.users.find({"address.country":'china',"address.city":"hangzhou",age:{$gte:18}})- 查 "address.country"='china'
- 且 "address.city"="hangzhou"
- 且 age≥18

三、映射Project 与 过滤
作用:对查询结果的过滤
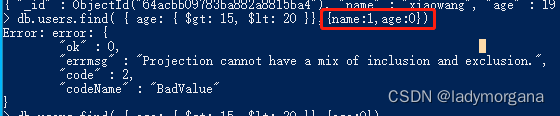
- 如:查询后加,{name:1} ,表示只显示 name字段

- 查询后加,{name:1,age:1} ,表示只显示 name + age 字段

- 如:查询后加,{age:0} ,表示不显示 age字段

- 注意: 1 和 0不能同时使用,如 name:1,age:0 ,否则会报错
四、去除重复 Distinct
作用:对查询结果去重,并不会删除原文档
db.users.distinct("city")
db.users.distinct("address.city")
五、聚合分组统计 Group By
A. 三种方式
- 聚合函数
- 聚合管道
- MapReduce (非常适用于大数据分析, 如基于java的hadoop)
B:聚合函数 ( 了解即可 )

注意:4.2.1中已经不支持 group( db.users.help() 查询没有group函数 )

1. 分组统计不同年龄段的用户
db.users.group(
{
key: { age: 1 },
cond:{ age:{$gt:16 }},
reduce:function(curr, result) {
result.total += 1;
},
initial: { total : 0 }
}
)2. 分组统计不同用户的订单总额

















 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











