






本人机器学习小白一枚,入坑不久,也就是对人工智能有一些兴趣,所以在业余时间学习了一下机器学习,在这里总结一下自己的感想和心得,学习的第一个算法是线性回归算法,在机器学习里面是很基础但是很重要,也很常用的算法之一了,我是通过吴恩达的视频和周老师的西瓜书来理解这个算法的,加上上网多百度百度,由于数学忘的差不多了,看的其实还蛮吃力的,还要经常啃啃数学。废话不多说了,走出我们紧张刺激的人工智能第一步吧:
单变量线性回归
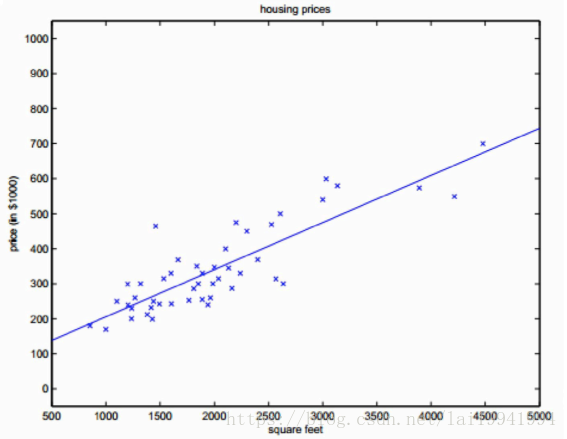
就拿最经典的房屋预测价格来说吧,我们假设想用房屋面积去预测房屋价格,我们需要去假设自变量房屋面积和因变量房屋面积是线性相关关系的,而线性回归正适合解决连续性变量预测问题,所以这里我们可以用单变量线性回归去预测它。
如图,我们的数据集变化趋势拟合一条直线,而我们的目的就是尽可能去找到一条直线拟合最多的点
代价函数
对于多元线性回归,我们只需要确定w=[w0,w1,w2…wn]w=[w0,w1,w2…wn]就能确定f(x)f(x)。如何确定最优的ww,就需要损失函数。这里我们使用
均方误差得到损失函数。
J(w)=12m∑i=1m(f(xi)−yi)2
J(w)=12m∑i=1m(f(xi)−yi)2
f(xi)f(xi):当前ww下,预估的yy。
yiyi:原始的yy。
我们可以去假设一个代价函数 h(x)=θ1x+θ0
这里,我们只需要最小化该代价函数,就能拿到最优ww。均方误差对应了欧氏距离。基于均方误差最小化来求解的方法叫做”最小二
乘法”。在线性回归中,最小二乘法就是试图找到一条直线,使得所有样本到直线上的欧式距离之和最小。
使得J(w)=12m∑mi=1(f(xi)−yi)2J(w)=12m∑i=1m(f(xi)−yi)2最小化来求解ww叫做线性回归最小二乘的参数估计。这里J(w)J(w)是关于ww的凸函数,当它
关于ww的导数为零时,得到ww的最优解。
对于这种凸函数,只有一个最低点。除了直接求导的方式,当参数非常非常多时,还有一种方式,在计算机的世界里,可以逐步的去
逼近最低点。我们要做的是以最快的方式去逼近最低点。这里,我们就用到了梯度下降。梯度下降,就是在每一点,去对每一个ww求偏
导,确定梯度(前进的方向),每次前进一点(步长),去逼近最低点。当此次和上一次前进的差值达到设定的阈值或达到迭代次数,就停止,
取此时的ww为最接近的ww。这个过程类似于下山,每前进一步,按最陡的方向下山是最快的;梯度的作用就是帮我们找到这个陡的方向。
这里是可视化单变量线性回归中假设的梯度下降的模型,没有局部最优解,只有一个全局最优解,所以是很好求出这个最优解时θ1和θ0的
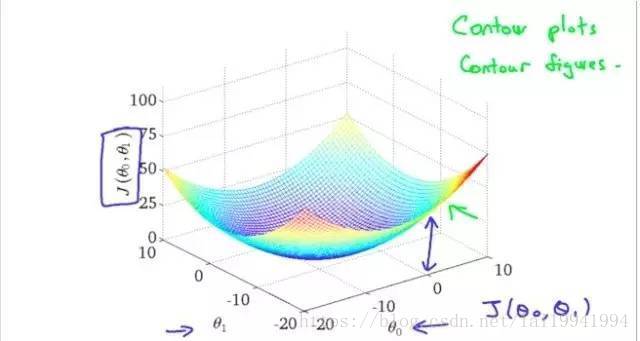
需要注意的是学习速率的取值,一般是0.01,然后0.03.然后01这样去试,在不同场景下学习速率的初始取值也是不一样的,尽管我还没碰到什么时候回不一样的问题
当到达最优解的时候,我们的假设函数H(x)是最拟合实际数据集的一元二次方程,也就建立了我们的训练模型,接下来需要做的就是调参和优化问题了,需要考虑过拟合问题还有对特征向量的一些处理,比如特征放缩,归一化一类的。
ok,今天第一天写博客,可能写的不好,排版也没搞懂,下次我再把多项回归和一些算法处理细节分享总结一下吧。














 1209
1209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









