







10 月开发者嘉年华,我正在参与「开源博客马拉松挑战」,点击链接 1024 开发者嘉年华 了解活动详情。
OpenMLDB项目开源地址:https://github.com/4paradigm/OpenMLDB
与OpenMLDB结缘
本人与OpenMLDB结缘源自于中科院开源之夏(OSPP)和GitLink开源夏令营,这俩个活动都是难度很高但性价比很高的开源活动,适合有一定程度开源经验的同学参与。其中活动群内有个小助手特别活跃得宣传OpenMLDB的项目,抱着了解了解的兴趣就了解一下,了解后发现这是一个很有意思的并尝试做了一些开源任务,值得一提OpenMLDB经常推出各式各样的活动奖励,很有助于提高新人的积极性。
废话不多说了,我们来好好介绍一下该项目叭。

OpenMLDB是什么?
这里我就引用官方的介绍
OpenMLDB是d第四范式旗下一款开源机器学习数据库,提供线上线下一致的生产级特征平台。
在机器学习的很多应用场景中,为了获得高业务价值的模型,对于实时特征有很强的需求,比如实时的个性化推荐、风控、反欺诈等。但是,由数据科学家所构建的特征计算脚本(一般基于 Python 开发),由于无法满足低延迟、高吞吐、高可用等生产级特性,因此无法直接上线。为了在生产环境中上线特征脚本用于模型推理,并且满足实时计算的性能要求,往往需要工程化团队进行代码重构和优化。那么,由于两个团队、两套系统参与了从离线开发到部署上线的全流程,线上线下一致性校验成为一个必不可少的步骤,其往往需要耗费大量的沟通成本、开发成本,和测试成本。
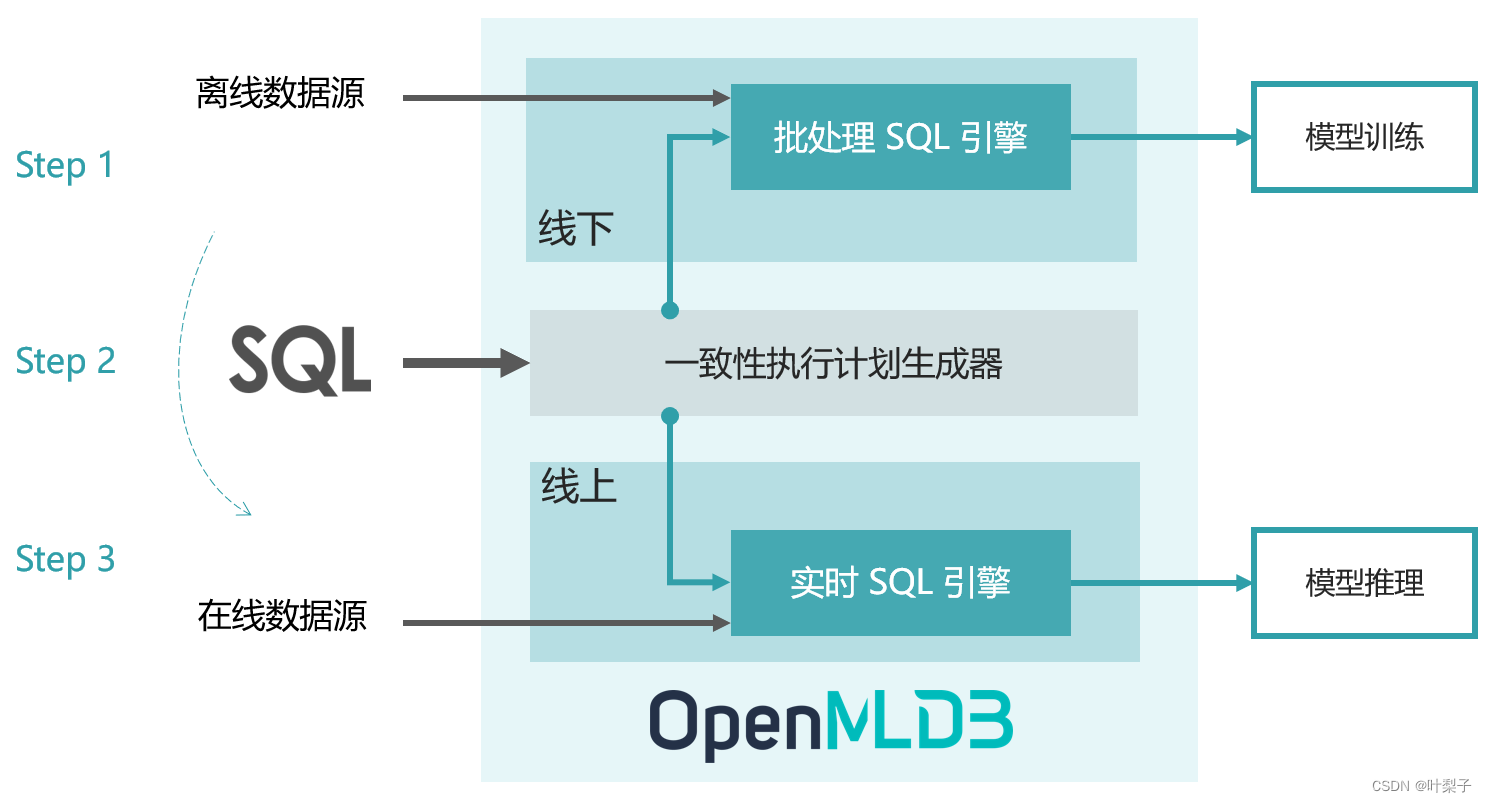
OpenMLDB 的整体架构设计是为了达到特征平台从开发到部署的流程优化目标:开发即上线 ,以此来大幅降低人工智能的落地成本。其完成从特征的离线开发到上线部署,只需要三个步骤:
步骤一:使用 SQL 进行离线特征脚本开发,用于模型训练
步骤二:SQL 特征脚本一键部署上线,由线下模式切换为线上模式
步骤三:接入实时数据,进行线上实时特征计算,用于模型推理
如何参与OpenMLDB开源呢?
从good first issue开始
这里给予大家一个建议,首先进入社区的微信群对开源项目进行基本的了解,了解最近的活动(OpenMLDB的活动非常多),无论是老手还是新手都可以先在Issues中选取一个有good first issue标签的任务进行尝试。此类任务难度极低,主要是为了让新人体验开源项目的整个pr过程,帮助新人树立信心。
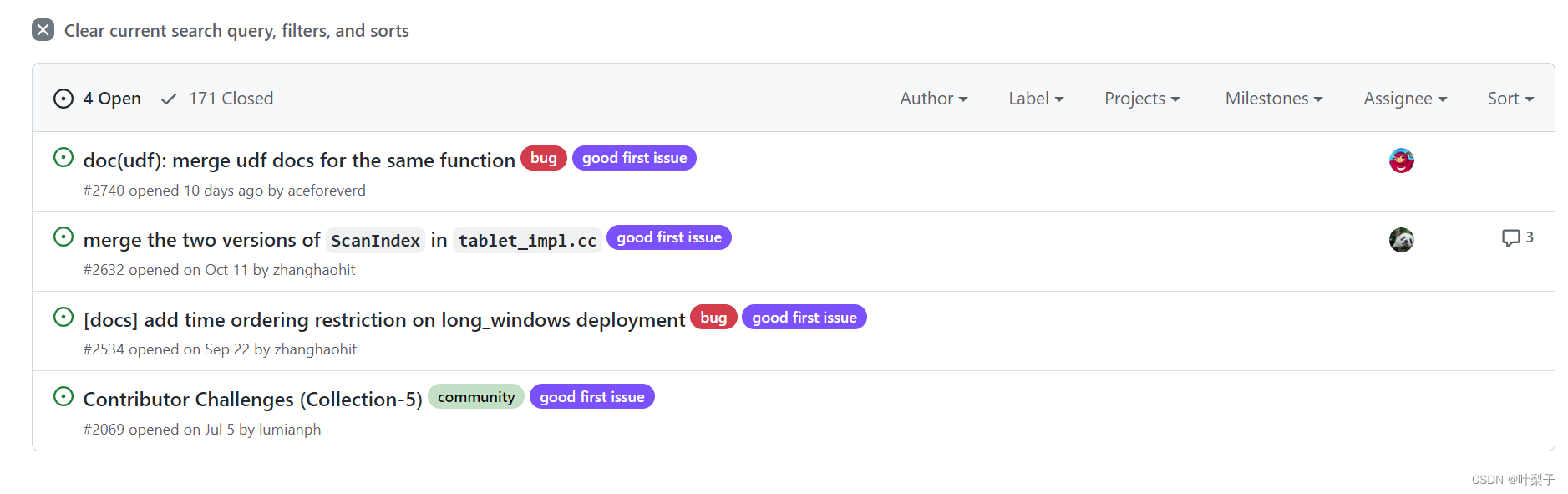
上图就是good first issue标签的项目,Assignee就是已经分配了该项目给某个用户啦!
如果想要申请对应的项目,我们可以点进对应的issue中进行回复:please assign this to me
给大家一个样例,可见下图

编译与安装
官方安装部署介绍地址:https://openmldb.ai/docs/zh/main/deploy/index.html
- 操作系统:CentOS 7, Ubuntu 20.04, macOS >= 10.15。其中Linux glibc版本 >= 2.17。其他操作系统版本没有做完整的测试,不能保证完全正确运行。
- 内存:视数据量而定,推荐在 8 GB 及以上。
- CPU:
- 目前仅支持 x86 架构,暂不支持例如 ARM 等架构。
- 核数推荐不少于 4 核,如果 Linux 环境下 CPU 不支持 AVX2 指令集,需要从源码重新编译部署包。
- 运行环境:zookeeper和taskmanager部署需要java runtime environment。其他组件无要求。
由于我们是进行开源贡献,因此我们需要选择编译安装,为了方便可以选择docker内安装,参考官网指导:https://openmldb.ai/docs/zh/main/deploy/compile.html
无论你是在虚拟机中还是wsl中,都可以很方便得实现官方docker编译教程。
对于新手而言,这可能是会一个较为耗费时间的环节,但这个环节是很重要的,无论你以后做不做OpenMLDB,在其他的项目中都会常用到这个过程,如果你是第一次做可以花费两个整天的时间好好吃透这整个编译流程,以后遇到类似的问题就可以触类旁通了。
使用案例
提交开源贡献前,我们应当先学会使用这个工具!官方已经有非常详尽的使用案例了,这里大家可以根据自己需求先找实际的使用案例。
参考官方的使用案例:
| 应用 | 所用工具 | 简介 |
|---|---|---|
| 出租车行程时间预测 | OpenMLDB, LightGBM | 这是个来自 Kaggle 的挑战,用于预测纽约市的出租车行程时间。你可以从这里阅读更多关于该应用场景的描述。本案例展示使用 OpenMLDB + LightGBM 的开源方案,快速搭建完整的机器学习应用。 |
| 使用 Pulsar connector 接入实时数据流 | OpenMLDB, Pulsar, OpenMLDB-Pulsar connector | Apache Pulsar 是一个高性能的云原生的消息队列平台,基于 OpenMLDB-Pulsar connector,我们可以高效的将 Pulsar 的数据流作为 OpenMLDB 的在线数据源,实现两者的无缝整合。 |
| 使用 Kafka connector 接入实时数据流 | OpenMLDB, Kafka, OpenMLDB-Kafka connector | Apache Kafka 是一个分布式消息流平台。基于 OpenMLDB-Kafka connector,实时数据流可以被简单的引入到 OpenMLDB 作为在线数据源。 |
| 使用 RocketMQ 接入实时数据流 | OpenMLDB, RocketMQ, OpenMLDB-RocketMQ connector | Apache RocketMQ 是一个云原生“消息、事件、流”实时数据处理平台,使用 OpenMLDB-RocketMQ connector,可以将实时数据从 RocketMQ 高效的引入到 OpenMLDB,进行实时计算。 |
| 在 DolphinScheduler 中构建端到端的机器学习工作流 | OpenMLDB, DolphinScheduler, OpenMLDB task plugin | 这个案例新演示了基于 OpenMLDB 和 DolphinScheduler(一个开源的工作流任务调度平台)来构建一个完整的机器学习工作流,包括了特征工程、模型训练,以及部署上线。 |
| 在线广告点击欺诈检测 | OpenMLDB, XGBoost | 该案例演示了基于 OpenMLDB 以及 XGBoost 去构建一个在线广告反欺诈的应用。 |
| 基于 SQL 构建机器学习全流程 | OpenMLDB, Byzer, OpenMLDB Plugin for Byzer | Byzer 是一门面向 Data 和 AI 的低代码、云原生的开源编程语言。Byzer 已经把 OpenMLDB 整合在内,用来一起构建完整的机器学习应用全流程。 |
| 在 Airflow 中构建机器学习应用 | OpenMLDB, Airflow, Airflow OpenMLDB Provider, XGBoost | Airflow 是一个流行的工作流编排和管理软件。该案例展示了如何在 Airflow 内,通过提供的 provder package,来方便的编排基于 OpenMLDB 的机器学习任务。 |
| 精准营销 | OpenMLDB, OneFlow | OneFlow 是一个用户友好、可扩展、高效的深度学习框架。改案例展示了如何使用 OpenMLDB 做特征工程,串联 OneFlow 进行模型训练和预测,来构造一个用于精准营销的机器学习应用。 |
开始尝试更有挑战性的项目
除了good first issue标签,issues内还有许多别的有意思的标签,比如document就是文档这块需要精进。
除了正在提出的issues外,我们可以检查历史已经closed的issues进行学习,观察别人是怎么提交pr的,是如何解决问题的,这个过程会有助于我们解决新issue的时候有一个对比依据。
我们随便挑一个closed的issue进去看一看别人是怎么做的

这里就可以看到详细提交内容啦!
尝试开源活动
类似一开始说的中科院开源之夏(OSPP)和GitLink开源夏令营,OpenMLDB每年都会在其中投入几个很有意思的课题,当你有一定基础了以后就可以参与这类开源项目活动了(0基础是不行的,一定要提前对OpenMLDB有了解并且明白如何进行贡献哟!从现在开始好好准备的话,正好可以赶上明年暑期的活动呢),给自己的简历狠狠的添上一笔!而且还有奖金可以拿哟!
希望大家一起在开源学习的道路上越走越远!















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









