







目录
Trino 的资源组管理者 InternalResourceGroupManager
一、在内存中创建和管理队列groups,groups中的属性赋值来自查询 db中的配置
2. 调用canRunMore(),作用:判断一个新提交的任务是否可以直接执行?
3. 调用canQueueMore(),作用:判断一个新提交的任务是否可以排队?
1. InternalResourceGroup 资源组实例中的重要动态属性
a. eligibleSubGroups :有能力运行查询的子组的集合,是一个队列,有四种实现方式,默认是FifoQueue
b. queuedQueries:排队查询任务的集合,是一个队列,有四种实现方式,默认是FifoQueue
2. eligibleSubGroups 和 queuedQueries 的实现方式
3. eligibleSubGroups 和 queuedQueries 的加入数据
a. eligibleSubGroups 加入数据的调用入口
Trino 的资源组管理者 InternalResourceGroupManager
其作用:
零、提交查询到资源组
一、在内存中创建和管理队列groups,groups中的属性赋值来自查询 db中的配置
二、判断一个查询是是否执行、是否排队、是否失败
三、排队的任务如何被拿出来执行
重要属性:
//定时刷新执行器,取出队列中的排队任务执行
private final ScheduledExecutorService refreshExecutor = newSingleThreadScheduledExecutor(daemonThreadsNamed("ResourceGroupManager"));
//根节点的 InternalResourceGroup 集合
private final List<InternalResourceGroup> rootGroups = new CopyOnWriteArrayList<>();
//从根节点开始的所有节点的 InternalResourceGroup 集合
//ResourceGroupId用一个 list存放队列group的name全称。如:root.boss,则list有2个元素,分别是root,boss
private final ConcurrentMap<ResourceGroupId, InternalResourceGroup> groups = new ConcurrentHashMap<>();
//根据配置文件实现的ResourceGroupConfigurationManager,db存储:DbResourceGroupConfigurationManager
private final AtomicReference<ResourceGroupConfigurationManager<C>> configurationManager;InternalResourceGroup 资源组实例
重要静态属性
//此队列的根节点,从父节点继承而来,比如:root.id=root
private final InternalResourceGroup root;
//此队列的父节点,比如:root.id=roo.boss
private final Optional<InternalResourceGroup> parent;
//此队列的name全称,比如:id=roo.boss.dac1
private final ResourceGroupId id;零、提交查询到资源组
//submit 是提交查询到资源组的入口
public void submit(ManagedQueryExecution queryExecution, SelectionContext<C> selectionContext, Executor executor)
{
checkState(configurationManager.get() != null, "configurationManager not set");
//一、在内存中创建和管理队列groups,groups中的属性赋值来自查询 db中的配置
createGroupIfNecessary(selectionContext, executor);
//二、判断一个查询是是否执行、是否排队、是否失败
groups.get(selectionContext.getResourceGroupId()).run(queryExecution);
}一、在内存中创建和管理队列groups,groups中的属性赋值来自查询 db中的配置
二、判断一个查询是是否执行、是否排队、是否失败
1. 调用 run()
作用: 从上到下判断队列路径上是否可以执行、或者排队,只要一个路径为false,则为总体为false
比如:队列路径 root.boss.dac1, 判断 dac1否可以执行、或者排队,然后判断 boss否可以执行、或者排队,再判断 root否可以执行、或者排队,直到根节点。
public void run(ManagedQueryExecution query)
{
synchronized (root) {
//其子组不为空,非叶子节点,不让执行查询
//当 root 节点下没有添加子组时,可以提交查询;当添加一个boss 子组时,root 队列就不能再提交查询
if (!subGroups.isEmpty()) {
throw new TrinoException(INVALID_RESOURCE_GROUP, format("Cannot add queries to %s. It is not a leaf group.", id));
}
// Check all ancestors for capacity
InternalResourceGroup group = this;
boolean canQueue = true;
boolean canRun = true;
//从上到下判断整个路径上是否可以执行、或者排队,只要一个路径为false,则为总体为false
while (true) {
canQueue = canQueue && group.canQueueMore();
canRun = canRun && group.canRunMore();
if (group.parent.isEmpty()) {
break;
}
group = group.parent.get();
}
//不能执行也不能排队,任务直接失败
if (!canQueue && !canRun) {
query.fail(new QueryQueueFullException(id));
return;
}
//可以执行,在后台开始执行查询任务
if (canRun) {
startInBackground(query);
}
//可以排队,将查询加到队列中
else {
enqueueQuery(query);
}
query.addStateChangeListener(state -> {
if (state.isDone()) {
queryFinished(query);
}
});
}
}2. 调用canRunMore(),作用:判断一个新提交的任务是否可以直接执行?
直接执行需要同时满足2个条件
a. hard_cpu 使用时长 和 memory 使用量不大于配置
b.(本组+子组)的runningQueries 之和 小于 hard并发数
--from InternalResourceGroup
private boolean canRunMore()
{
checkState(Thread.holdsLock(root), "Must hold lock");
synchronized (root) {
long cpuUsageMillis = cachedResourceUsage.getCpuUsageMillis();
long memoryUsageBytes = cachedResourceUsage.getMemoryUsageBytes();
//hard_cpu 使用时长 和 memory 使用量不大于配置,可以 RunMore
if ((cpuUsageMillis >= hardCpuLimitMillis) || (memoryUsageBytes > softMemoryLimitBytes)) {
return false;
}
//最大并发
int hardConcurrencyLimit = this.hardConcurrencyLimit;
//如果 cpu >= soft_cpu,那么调整 hardConcurrencyLimit
if (cpuUsageMillis >= softCpuLimitMillis) {
// TODO: Consider whether CPU limit math should be performed on softConcurrency or hardConcurrency
// Linear penalty between soft and hard limit
double penalty = (cpuUsageMillis - softCpuLimitMillis) / (double) (hardCpuLimitMillis - softCpuLimitMillis);
hardConcurrencyLimit = (int) Math.floor(hardConcurrencyLimit * (1 - penalty));
// Always penalize by at least one
hardConcurrencyLimit = min(this.hardConcurrencyLimit - 1, hardConcurrencyLimit);
// Always allow at least one running query
hardConcurrencyLimit = Math.max(1, hardConcurrencyLimit);
}
//(本组+子组)的runningQueries 之和 小于 hard并发数
return runningQueries.size() + descendantRunningQueries < hardConcurrencyLimit;
}
}3. 调用canQueueMore(),作用:判断一个新提交的任务是否可以排队?
可以排队需要1个条件
a.(本组+子组)的排队数 之和 小于 最大排队数
-- from
private boolean canQueueMore()
{
checkState(Thread.holdsLock(root), "Must hold lock");
synchronized (root) {
//(本组+子组)的排队数 之和 小于 最大排队数
return descendantQueuedQueries + queuedQueries.size() < maxQueuedQueries;
}
}三、排队的任务如何被拿出来执行
1. InternalResourceGroup 资源组实例中的重要动态属性
//有能力运行查询的子组的集合,是一个队列,有四种实现方式,默认是FifoQueue
//有能力运行查询的子组的认定方式:isEligibleToStartNext = true
//有能力运行查询的子组的表现:当对它们调用 internalStartNext()时,它们必须返回true
@GuardedBy("root")
private Queue<InternalResourceGroup> eligibleSubGroups = new FifoQueue<>();
// Sub groups whose memory usage may be out of date. Most likely because they have a running query.
// 内存使用可能已过期的子组。很可能是因为他们有一个正在运行的查询
@GuardedBy("root")
private final Set<InternalResourceGroup> dirtySubGroups = new HashSet<>();
@GuardedBy("root")
//排队查询任务的集合,是一个队列,有四种实现方式,默认是FifoQueue
private UpdateablePriorityQueue<ManagedQueryExecution> queuedQueries = new FifoQueue<>();
@GuardedBy("root")
//正在运行任务的集合
private final Map<ManagedQueryExecution, ResourceUsage> runningQueries = new HashMap<>();
@GuardedBy("root")
//子代运行查询
private int descendantRunningQueries;
@GuardedBy("root")
//子代排队查询
private int descendantQueuedQueries;a. eligibleSubGroups :有能力运行查询的子组的集合,是一个队列,有四种实现方式,默认是FifoQueue
1. 有能力运行查询的子组的认定方式:isEligibleToStartNext
同时满足2个条件时,认定为有能力运行查询
a. canRunMore=true,即:一个新提交的任务可以直接执行
b. 排队查询任务的集合不为空 或者 有能力运行查询的子组的集合不为空
//同时满足2个条件时=true
// 1.canRunMore 2.排队查询任务的集合不为空 或者 有能力运行查询的子组的集合不为空
private boolean isEligibleToStartNext()
{
checkState(Thread.holdsLock(root), "Must hold lock");
synchronized (root) {
if (!canRunMore()) {
return false;
}
return !queuedQueries.isEmpty() || !eligibleSubGroups.isEmpty();
}
}2. 将有能力运行查询的子组,加入父组的 eligibleSubGroups中
private void updateEligibility()
{
checkState(Thread.holdsLock(root), "Must hold lock to update eligibility");
synchronized (root) {
if (parent.isEmpty()) {
return;
}
//当 isEligibleToStartNext=true 时,子组是有能力运行查询的
if (isEligibleToStartNext()) {
//将子组加入到 父组的 eligibleSubGroups中
parent.get().addOrUpdateSubGroup(this);
}
else {
parent.get().eligibleSubGroups.remove(this);
lastStartMillis = 0;
}
parent.get().updateEligibility();
}
}b. queuedQueries:排队查询任务的集合,是一个队列,有四种实现方式,默认是FifoQueue
1. canqQueueMore=true,即:可以排队时,将查询加入到排队队列中
//将查询加入到排队队列中
private void enqueueQuery(ManagedQueryExecution query)
{
checkState(Thread.holdsLock(root), "Must hold lock to enqueue a query");
synchronized (root) {
//将查询加入到排队队列中
queuedQueries.addOrUpdate(query, getQueryPriority(query.getSession()));
InternalResourceGroup group = this;
while (group.parent.isPresent()) {
group.parent.get().descendantQueuedQueries++;
group = group.parent.get();
}
updateEligibility();
}
}2. eligibleSubGroups 和 queuedQueries 的实现方式
a. 实现方式调用入口
b. 实现方式方法
// from InternalResourceGroup
// 根据配置的调度策略,对 eligibleSubGroups 和 queuedQueries 选择不同的实现方式
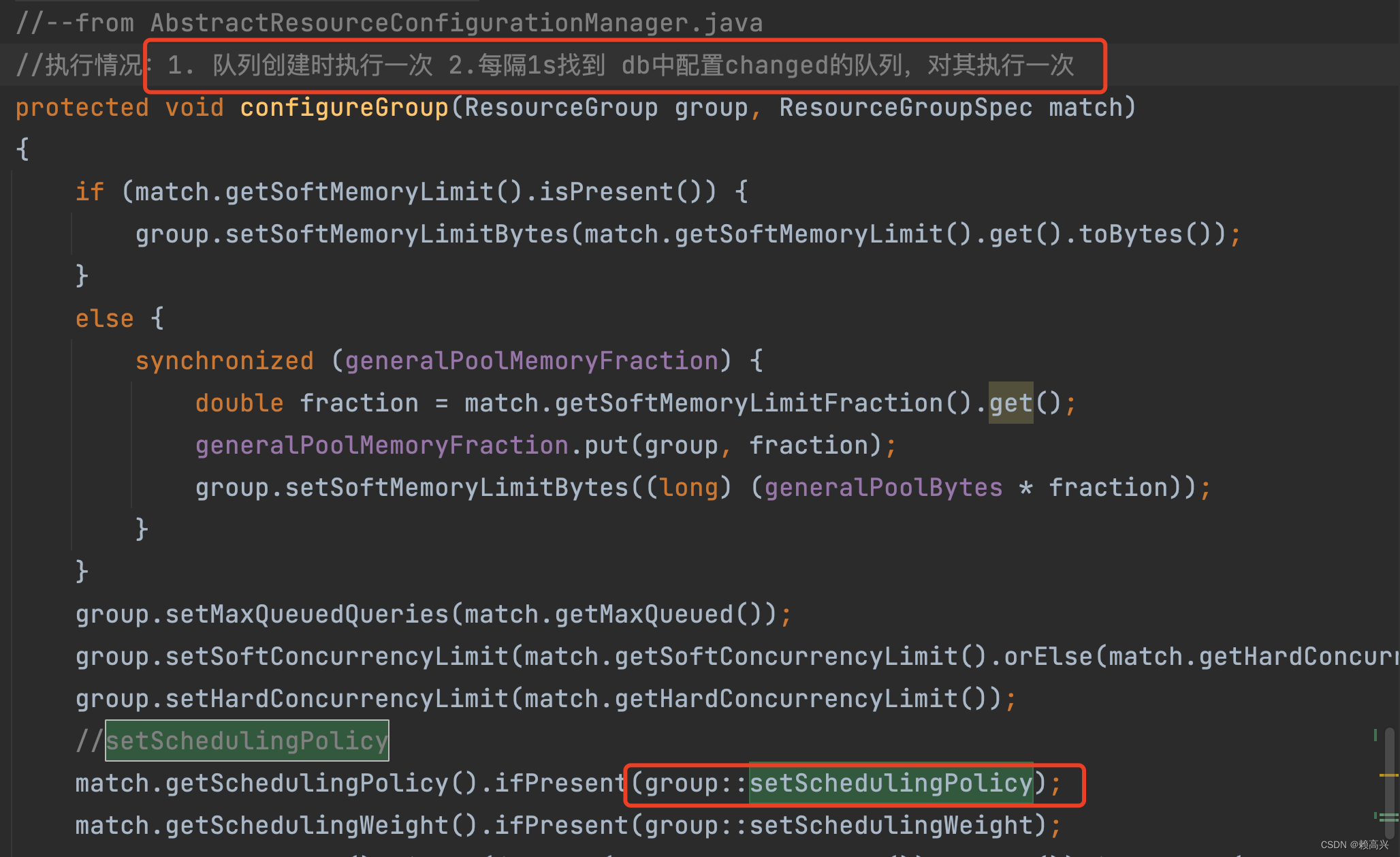
// 执行时机:1. 队列创建时执行一次 2.每隔1s找到 db中配置changed的队列,对其执行一次
public void setSchedulingPolicy(SchedulingPolicy policy)
{
synchronized (root) {
// policy == fair 就返回
if (policy == schedulingPolicy) {
return;
}
if (parent.isPresent() && parent.get().schedulingPolicy == QUERY_PRIORITY) {
checkArgument(policy == QUERY_PRIORITY, "Parent of %s uses query priority scheduling, so %s must also", id, id);
}
// Switch to the appropriate queue implementation to implement the desired policy
//eligibleSubGroups,有能力运行查询的子组的集合
Queue<InternalResourceGroup> queue;
//queuedQueries,排队查询任务的集合
UpdateablePriorityQueue<ManagedQueryExecution> queryQueue;
switch (policy) {
case FAIR:
queue = new FifoQueue<>();
queryQueue = new FifoQueue<>();
break;
case WEIGHTED:
queue = new StochasticPriorityQueue<>();
queryQueue = new StochasticPriorityQueue<>();
break;
case WEIGHTED_FAIR:
queue = new WeightedFairQueue<>();
queryQueue = new IndexedPriorityQueue<>();
break;
case QUERY_PRIORITY:
// Sub groups must use query priority to ensure ordering
for (InternalResourceGroup group : subGroups.values()) {
group.setSchedulingPolicy(QUERY_PRIORITY);
}
queue = new IndexedPriorityQueue<>();
queryQueue = new IndexedPriorityQueue<>();
break;
default:
throw new UnsupportedOperationException("Unsupported scheduling policy: " + policy);
}
schedulingPolicy = policy;
//策略更新前的队列不为空,需要拿出来一个放到到新策略队列中
while (!eligibleSubGroups.isEmpty()) {
InternalResourceGroup group = eligibleSubGroups.poll();
addOrUpdateSubGroup(queue, group);
}
eligibleSubGroups = queue;
//策略更新前的队列不为空,需要拿出来一个放到到新策略队列中
//todo 注意:策略更新,会导致排队的任务丢失
while (!queuedQueries.isEmpty()) {
ManagedQueryExecution query = queuedQueries.poll();
queryQueue.addOrUpdate(query, getQueryPriority(query.getSession()));
}
queuedQueries = queryQueue;
}
}c. 不同策略下的实现队列
| scheduling_policy | queuedQueries 排队查询任务的集合 实现类 | eligibleSubGroups 有能力运行查询的子组的集合 实现类 |
| fair | FifoQueue | FifoQueue |
| query_priority | IndexedPriorityQueue | IndexedPriorityQueue |
| weighted | StochasticPriorityQueue | StochasticPriorityQueue |
| weighted_fair | IndexedPriorityQueue | WeightedFairQueue |
3. eligibleSubGroups 和 queuedQueries 的加入数据
a. eligibleSubGroups 加入数据的调用入口
将有能力运行查询的子组,加入父组的 eligibleSubGroups中
private void updateEligibility()
{
checkState(Thread.holdsLock(root), "Must hold lock to update eligibility");
synchronized (root) {
if (parent.isEmpty()) {
return;
}
//当 isEligibleToStartNext=true 时,子组是有能力运行查询的
if (isEligibleToStartNext()) {
//将子组加入到 父组的 eligibleSubGroups中
parent.get().addOrUpdateSubGroup(this);
}
else {
parent.get().eligibleSubGroups.remove(this);
lastStartMillis = 0;
}
parent.get().updateEligibility();
}
} private void addOrUpdateSubGroup(Queue<InternalResourceGroup> queue, InternalResourceGroup group)
{
if (schedulingPolicy == WEIGHTED_FAIR) {
//WEIGHTED_FAIR 策略
((WeightedFairQueue<InternalResourceGroup>) queue).addOrUpdate(group, new Usage(group.getSchedulingWeight(), group.getRunningQueries()));
}
else {
//其他策略
((UpdateablePriorityQueue<InternalResourceGroup>) queue).addOrUpdate(group, getSubGroupSchedulingPriority(schedulingPolicy, group));
}
}
b. queuedQueries 的加入数据的调用入口
1. canqQueueMore=true,即:可以排队时,将查询加入到排队队列中
//将查询加入到排队队列中
private void enqueueQuery(ManagedQueryExecution query)
{
checkState(Thread.holdsLock(root), "Must hold lock to enqueue a query");
synchronized (root) {
//将查询加入到排队队列中
queuedQueries.addOrUpdate(query, getQueryPriority(query.getSession()));
InternalResourceGroup group = this;
while (group.parent.isPresent()) {
group.parent.get().descendantQueuedQueries++;
group = group.parent.get();
}
updateEligibility();
}
}c. 加入数据addOrUpdate 方法的第二个参数
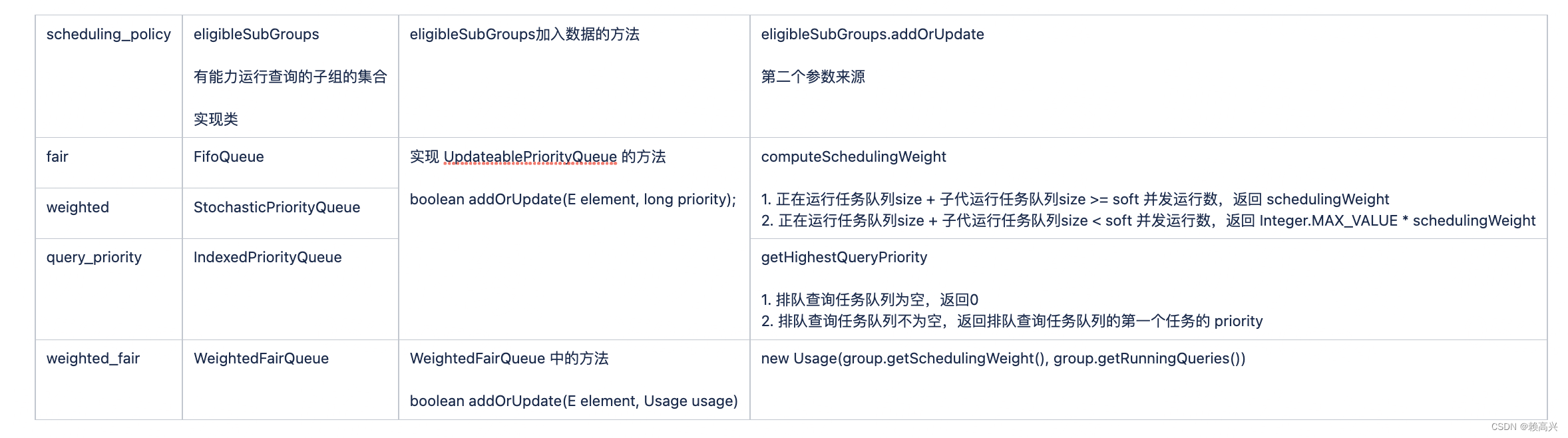
| scheduling_policy | queuedQueries 排队查询任务的集合 实现类 | queuedQueries加入数据的方法 | queuedQueries.addOrUpdate 第二个参数来源 |
| fair | FifoQueue | 实现 UpdateablePriorityQueue 的方法 | 查询 session 中设置的 Query priority |
| weighted | StochasticPriorityQueue | ||
| query_priority | IndexedPriorityQueue | ||
| weighted_fair | IndexedPriorityQueue |
| scheduling_policy | eligibleSubGroups | eligibleSubGroups加入数据的方法 | eligibleSubGroups.addOrUpdate |
| fair | FifoQueue | 实现 UpdateablePriorityQueue 的方法 | computeSchedulingWeight |
| weighted | StochasticPriorityQueue | ||
| query_priority | IndexedPriorityQueue | getHighestQueryPriority | |
| weighted_fair | WeightedFairQueue | WeightedFairQueue 中的方法 | new Usage(group.getSchedulingWeight(), group.getRunningQueries()) |
4. 四种实现队列介绍
a. FifoQueue
默认的调度策略,就是典型的FIFO,对于 addOrUpdate方法传入的 priority参数,实际是没有起作用的,所以没有任何的优先级考量。
fair 策略下的两个调度队列,都是使用了FifoQueue这个队列
private final Set<E> delegate = new LinkedHashSet<>();
@Override
//加入数据时,没有使用到第二个参数
public boolean addOrUpdate(E element, long priority)
{
return delegate.add(element);
}
@Override
//取出数据时,返回、并删除第一个元素
public E poll()
{
Iterator<E> iterator = delegate.iterator();
if (!iterator.hasNext()) {
return null;
}
E element = iterator.next();
iterator.remove();
return element;
}b. StochasticPriorityQueue
对于weighted这个策略,两个调度队列使用的都是StochasticPriorityQueue这个类
使用 Node<E> root 保存查询任务信息,index可以理解为索引,可以实现O(1)时间复杂度的contain和remove操作,效率比较高。
在 Node 中,
1. tickets,是 addOrUpdate(E element, long priority) 的第二个参数,查询的优先级
2. totalTickets,该节点以及所有子节点的tickets总和;
3. descendants,表示当前节点的孩子数,当add或者remove节点时,该值就会进行更新。需要注意的是,在插入新节点时,会根据左右子节点的descendants,来加入少的一边,保证树的平衡。
4. 将 element 加入到 root二叉树时,并更新每个节点的 totalTickets,descendants
// 使用 Fenwick tree 保存查询任务信息
//index可以理解为索引,可以实现O(1)时间复杂度的contain和remove操作,效率比较高。
private final Map<E, Node<E>> index = new HashMap<>();
// This is a Fenwick tree, where each node has weight equal to the sum of its weight
// and all its children's weights
private Node<E> root;
private static final class Node<E>
{
private Optional<Node<E>> parent;
private E value;
private Optional<Node<E>> left = Optional.empty();
private Optional<Node<E>> right = Optional.empty();
//tickets,是 addOrUpdate(E element, long priority) 的第二个参数,查询的优先级
private long tickets;
//totalTickets,该节点以及所有子节点的tickets总和;
private long totalTickets;
//descendants,表示当前节点的孩子数,当add或者remove节点时,该值就会进行更新。需要注意的是,在插入新节点时,会根据左右子节点的descendants,来加入少的一边,保证树的平衡。
private int descendants;
}取出数据操作
//取出数据
public E poll()
{
if (root == null) {
return null;
}
//winningTicket 生成一个[0,getTotalTickets)范围内随机整数
long winningTicket = ThreadLocalRandom.current().nextLong(root.getTotalTickets());
Node<E> candidate = root;
//不是叶子节点,一直循环
while (!candidate.isLeaf()) {
long leftTickets = candidate.getLeft().map(Node::getTotalTickets).orElse(0L);
if (winningTicket < leftTickets) {
candidate = candidate.getLeft().get();
continue;
}
//winningTicket >= winningTicket ,则 winningTicket = winningTicket - leftTickets
winningTicket -= leftTickets;
//winningTicket 的范围是 [0,rightTickets + candidate.getTickets())
if (winningTicket < candidate.getTickets()) {
break;
}
winningTicket -= candidate.getTickets();
checkState(candidate.getRight().isPresent(), "Expected right node to contain the winner, but it does not exist");
candidate = candidate.getRight().get();
}
checkState(winningTicket < candidate.getTickets(), "Inconsistent winner");
E value = candidate.getValue();
remove(value);
return value;
}
简单这样理解这种调度策略:以权重总和为上限生成随机数,按照从上往下,从左往右的顺序,找到一个 ticket (优先级) 大于该随机数的节点。查询的权重就是query_priority;eligible sub-groups的权重就是其priority,与schedulingWeight有关。
c. IndexedPriorityQueue
使用TreeSet来保存查询任务信息。index可以理解为索引,可以实现O(1)时间复杂度的contain和remove操作,效率比较高。
generation可以理解为插入的顺序,每次插入新的成员,都会将队列的当前 generation赋值给节点,然后自增1。
加入数据时,按照priority和generation进行比较, priority 不同时, priority大的查询优先出队列,priority 相同时, 先进入队列的查询优先出队列。
private final Map<E, Entry<E>> index = new HashMap<>();
//使用TreeSet来保存查询任务信息,加入数据时,按照priority和generation进行比较,
//priority 不同时, priority大的查询优先出队列,priority 相同时, 先进入队列的查询优先出队列,
//index可以理解为索引,可以实现O(1)时间复杂度的contain和remove操作,效率比较高。
//generation可以理解为插入的顺序,每次插入新的成员,都会将队列的当前 generation赋值给节点,然后自增1。
private final Set<Entry<E>> queue = new TreeSet<>((entry1, entry2) -> {
int priorityComparison = Long.compare(entry2.getPriority(), entry1.getPriority());
if (priorityComparison != 0) {
return priorityComparison;
}
return Long.compare(entry1.getGeneration(), entry2.getGeneration());
});
//任务累加器
private long generation;
@Override
//加入数据
public boolean addOrUpdate(E element, long priority)
{
Entry<E> entry = index.get(element);
if (entry != null) {
queue.remove(entry);
Entry<E> newEntry = new Entry<>(element, priority, entry.getGeneration());
queue.add(newEntry);
index.put(element, newEntry);
return false;
}
Entry<E> newEntry = new Entry<>(element, priority, generation);
generation++;
queue.add(newEntry);
index.put(element, newEntry);
return true;
}
@Override
public boolean contains(E element)
{
return index.containsKey(element);
}
@Override
public boolean remove(E element)
{
Entry<E> entry = index.remove(element);
if (entry != null) {
queue.remove(entry);
return true;
}
return false;
}
@Override
//取出数据
public E poll()
{
Iterator<Entry<E>> iterator = queue.iterator();
if (!iterator.hasNext()) {
return null;
}
Entry<E> entry = iterator.next();
iterator.remove();
checkState(index.remove(entry.getValue()) != null, "Failed to remove entry from index");
return entry.getValue();
}
d. WeightedFairQueue
addOrUpdate方法加入数据时,第二个参数是 Usage , Usage 的构造方法是 new Usage(int share, int utilization) 调用传参是 new Usage(group.getSchedulingWeight(), group.getRunningQueries()) 因此 Usage 的 share 存储SchedulingWeight,utilization存储 RunningQueries
//使用LinkedHashMap来保存查询任务信息
private final Map<E, Node<E>> index = new LinkedHashMap<>();
private long currentLogicalTime;
//加入数据
// new Usage(group.getSchedulingWeight(), group.getRunningQueries())
// new Usage(int share, int utilization)
//Usage 的 share 存储SchedulingWeight,utilization存储 RunningQueries
public boolean addOrUpdate(E element, Usage usage)
{
Node<E> node = index.get(element);
if (node != null) {
node.update(usage);
return false;
}
node = new Node<>(element, usage, currentLogicalTime++);
index.put(element, node);
return true;
}取出数据
//取出数据,取出【正在执行的任务占比 / SchedulingWeight占比】值最小的元素
public E poll()
{
//candidates 是所有 Node<E> 的集合
Collection<Node<E>> candidates = index.values();
//SchedulingWeight 之和
long totalShare = 0;
//RunningQueries 之和
long totalUtilization = 1; // prevent / by zero
for (Node<E> candidate : candidates) {
totalShare += candidate.getShare();
totalUtilization += candidate.getUtilization();
}
List<Node<E>> winners = new ArrayList<>();
double winnerDelta = 1;
for (Node<E> candidate : candidates) {
double actualFraction = 1.0 * candidate.getUtilization() / totalUtilization;
double expectedFraction = 1.0 * candidate.getShare() / totalShare;
// 正在执行的任务占比/SchedulingWeight占比
double delta = actualFraction / expectedFraction;
// 找到delta 最小的放到 winners中
if (delta <= winnerDelta) {
if (delta < winnerDelta) {
winnerDelta = delta;
winners.clear();
}
// if multiple candidates have the same delta, picking deterministically could cause starvation
// we use a stochastic method (weighted by share) to pick amongst these candidates
winners.add(candidate);
}
}
if (winners.isEmpty()) {
return null;
}
Node<E> winner = Collections.min(winners);
E value = winner.getValue();
index.remove(value);
return value;
}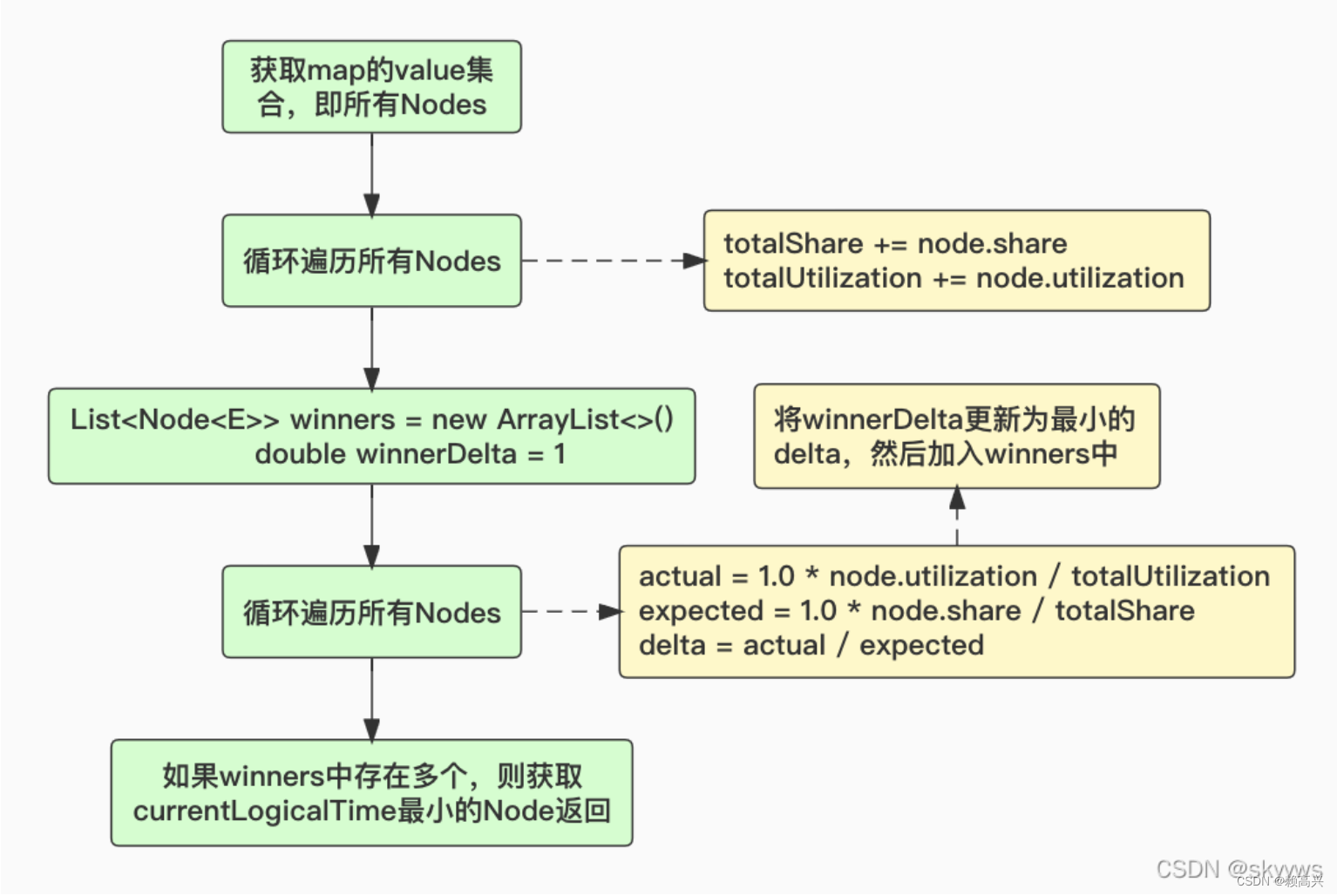
获取每个节点 utilization和 share占总的比例,然后计算一个实际占比/期望占比的delta,取delta最小的节点,这里utilization代表runningQueries,可以理解为group实际使用的占比;而share代表schedulingWeight,可以理解为group预期的占比,最终相除就是实际/期望的delta
5. 四种调度策略取出数据策略

| scheduling_policy | queuedQueries 排队查询任务的集合 实现类 | queuedQueries 排队查询任务的集合 取出数据的优先级 | eligibleSubGroups 有能力运行查询的子组的集合 实现类 | eligibleSubGroups 有能力运行查询的子组的集合 取出数据的优先级 |
| fair | FifoQueue | FIFO | FifoQueue | FIFO |
| weighted | StochasticPriorityQueue | 按照从上往下,从左往右的顺序,找到一个 ticket (Query priority) 大于该随机数的节点 | StochasticPriorityQueue | 按照从上往下,从左往右的顺序,找到一个 ticket ( computeSchedulingWeight ) 大于该随机数的节点 |
| query_priority | IndexedPriorityQueue | priority (Query priority)不同时, priority大的查询优先出队列,priority 相同时, 先进入队列的查询优先出队列。 | IndexedPriorityQueue | priority (getHighestQueryPriority)不同时, priority大的查询优先出队列,priority 相同时, 先进入队列的查询优先出队列。 |
| weighted_fair | IndexedPriorityQueue | priority (Query priority)不同时, priority大的查询优先出队列,priority 相同时, 先进入队列的查询优先出队列。 | WeightedFairQueue | 取出【正在执行任务数占比 / SchedulingWeight占比】值最小的队列 |
简单来看,就是:
1)如果我们需要严格按照 query_priority来执行 sql,那么需要选择 weighted_fair或者 query_priority策略
2)当我们想要通过 schedulingWeight来控制多个 group的优先执行顺序,可以选择 weighted和 weighted_fair策略
3)不考虑任务执行优先级,选择 Fair策略















 3009
3009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









