







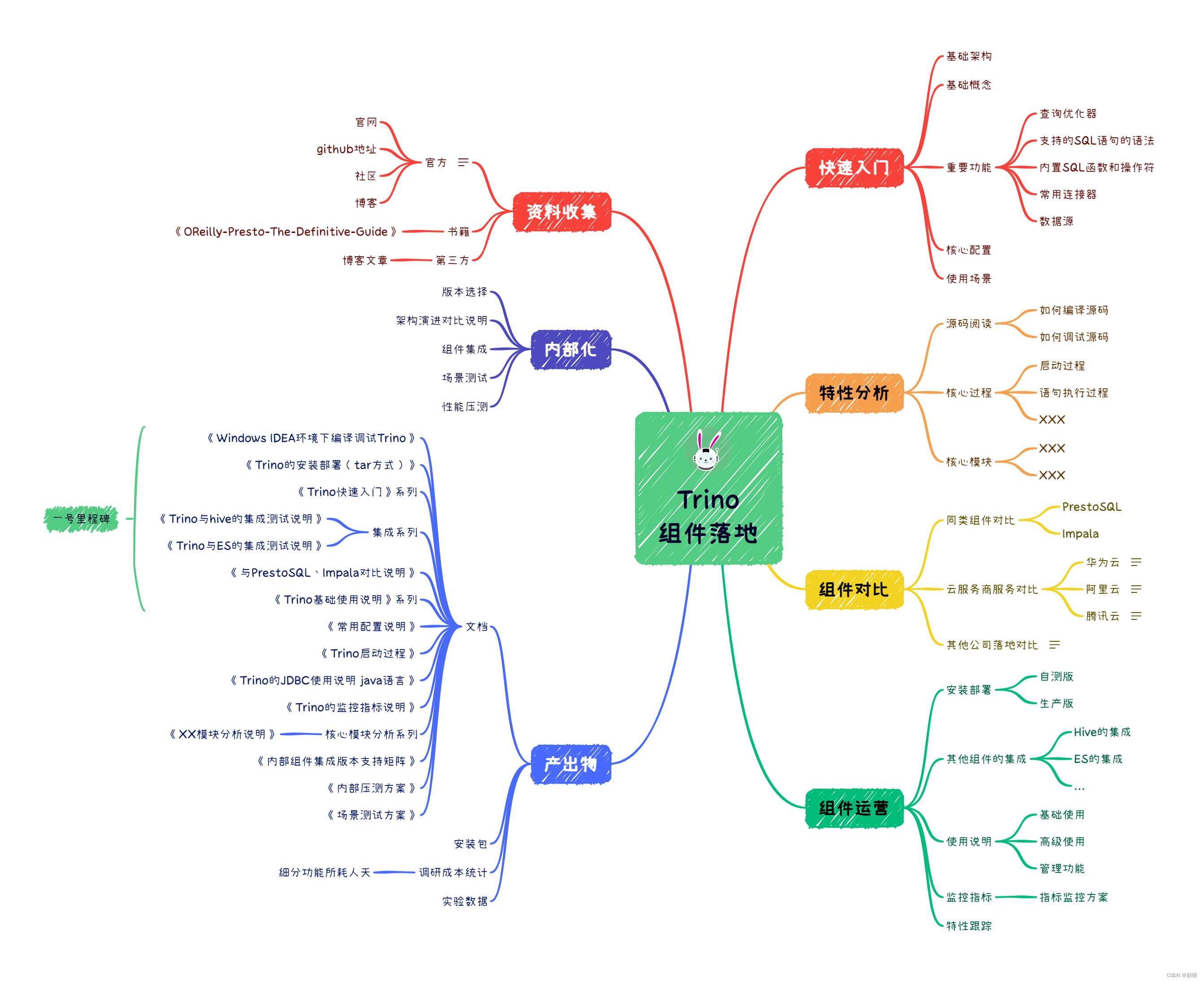
Trino调研手册
一、简介说明
什么是Trino
Trino是一个分布式SQL查询引擎,旨在查询分布在一个或多个异质数据源的大型数据集。
Trino不是一个通用的关系型数据库。它不是MySQL、PostgreSQL或Oracle等数据库的替代品。Trino不是为处理在线交易处理(OLTP)而设计的。这对于许多其他为数据仓库或分析而设计和优化的数据库来说也是如此。
Trino被设计用来处理数据仓库和分析:数据分析,聚集大量的数据和制作数据报表。这些工作通常被归类为在线分析处理(OLAP)。
使用场景
SQL分析的统一切入点
解决众多数据库语法的问题
Trino允许你解决这些问题。你可以将所有这些数据库暴露在一个地方: Trino。你可以使用一个SQL标准来查询所有的系统–标准化的SQL、函数和Trino支持的操作符。可以通过Trino访问你组织中的所有数据。
为数据仓库和其他数据源提供连接器
解决数据源众多和隔离查询的问题
Trino有丰富大的数据源连接器,可以添加任何数据仓库或数据库作为数据源,就像任何其他关系型数据库一样。甚至可以在同一个系统中查询任何数据库,数据仓库,源数据库,以及任何其他数据库 ,实现跨数据源访问。
使用SQL语言分析非关系型数据源
解决nosql系统多查询难,学习成本高的问题
Trino允许你作为一个数据源连接到所有这些系统。它将数据暴露出来,用标准的美国国家标准协会(ANSI)SQL和所有使用SQL的工具进行查询
联合查询
实现跨库,跨schema的联合查询
联合查询是一个SQL查询,在同一语句中引用和使用来自完全不同系统的不同数据库和模式。在Trino中所有的数据源都可以让你在同一时间查询,在同一查询中使用相同的SQL。你可以定义你的对象存储中的用户跟踪信息与你的RDBMS中的客户数据之间的关系。如果你的键值存储包含了更多的相关信息,你也可以把它挂到你的查询中。
虚拟数据仓库的语义层
可以实现一个中小型的虚拟数据集市。
Trino可以作为一个虚拟数据仓库使用。它可以通过使用一个工具和标准的ANSI SQL来定义你的语义层。一旦所有的数据库被配置为Trino中的数据源,你就可以查询它们。Trino提供了必要的计算能力来查询数据库中的存储。使用SQL和支持的函数和运算符,Trino可以直接从源头为您提供所需的数据。在你使用它进行分析之前,不需要复制、迁移或转换数据。
使用Trino作为这种 “即时数据仓库”,为企业提供了增强其现有数据仓库的额外功能的潜力,甚至可以完全避免建立和维护一个仓库。
数据湖查询引擎
数据湖这个词经常被用于一个大型的HDFS或类似的分布式对象存储系统,各种数据都被存储在其中,而没有友好的对其进行访问。Trino将作为其查询引擎,是它成为一个有用的数据仓库。事实上,Trino(Presto)是从Facebook出现的,它是解决比Hive和其他工具所能提供的更快、更强大的超大型Hadoop数据仓库查询的一种方式。
Trino能够使用Hive连接器来对接存储层,从而在你的数据湖上实现基于SQL的分析,无论它位于何处,无论它如何存储数据。
SQL转换和ETL
通过对RDBMS和其他数据存储系统的支持,Trino可以用来迁移数据。SQL以及丰富的SQL函数集,可以帮助查询数据,转换数据,然后将其写入同一数据源或任何其他数据源。
在实际生产中,可以将数据从你的对象存储系统或键值存储中复制出来,然后进入RDBMS,并将其用于你的分析工作。当然,你也可以对数据进行转换和聚合,以获得新的理解。
另一方面,从运行中的RDBMS,或者像Kafka这样的事件流系统中获取数据,并将其移入数据湖,以减轻RDBMS在众多查询方面的负担。ETL过程,现在通常也被称为数据准备,可以是这个过程的重要组成部分,以改善数据,并创建一个更适合查询和分析的数据模型。在这种情况下,Trino是整个数据管理解决方案的关键部分。
基本概念
要理解Trino,你必须首先理解整个Trino文档中使用的术语和概念。
架构
主要是MPP的主从式架构
| 优点 | 缺点 | |
|---|---|---|
| 支持标准SQL,每个节点都有丰富的事务处理和管理功能; | 集群规模调整要求较多,增减节点时通常需要停机,且有的系统只能增加不能减少,增加数据源,需要停机重启。 | |
| 资源管理精细;资源独立,可扩展性强 | 相对吞吐量一般,单节点缓慢会拖累整体性能(木桶短板效应) | |
| 预知数据结构模型的中等规模的固定模式数据管理; | 很难高可用,分区容错性差 |
Cluster 集群
一个Trino集群由一个协调器和许多工作机组成。(B站400+机器数)
用户用SQL查询工具连接到协调器。协调器与工作机协作。协调器和工作机访问连接的数据源(data sources)。这种访问是在**目录集(catalogs)**中配置的。
处理每个查询是一个有状态的操作。工作负载由协调器协调,并在集群中的所有工作机中平行分布。每个节点在一个JVM实例中运行Trino,并使用线程进一步并行化处理。
Coordinator 协调器
Trino协调器是负责解析语句(parsing statements)、计划查询(planning queries)和管理Trino工作节点的服务器。它是Trino安装的 “大脑”,也是客户端连接以提交语句执行的节点。每个Trino安装必须有一个Trino协调器和一个或多个Trino工作者。出于开发或测试的目的,Trino的一个实例可以被配置为执行这两个角色。
协调器跟踪每个工作机的活动,并协调查询的执行。协调器创建一个涉及一系列阶段的查询逻辑模型,然后将其转化为一系列在Trino工作机集群上运行的连接任务。
协调器使用REST API与工作机和客户进行沟通。
Worker 工作机
Trino工作机是Trino安装中的一个服务器,它负责执行任务(executing tasks)和处理数据(processing data)。工作节点从连接器获取数据,并相互交换中间数据。协调器负责从工作机那里获取结果,并将最终结果返回给客户端。
当一个Trino工作进程启动时,它向协调器中的发现服务广播自己,这使得它可以被Trino协调器用于任务执行。
工作机使用REST API与其他工作者和Trino协调者进行通信。
Data sources 数据源
数据源概念模型中包含了连接器、目录、schema、table。
Connector 连接器
连接器使Trino适配一个数据源,如Hive或关系型数据库。你可以像看待数据库的驱动程序一样看待连接器。它是Trino的SPI的一个实现,它允许Trino使用标准的API与资源进行交互。
Trino包含几个内置的连接器:
- 一个用于JMX的JMX connector,
- 一个提供访问内置系统表的System connector,
- 一个Hive connector,
- 以及一个用于提供TPC-H基准数据的TPCH connector。
许多第三方开发者提供了连接器,使Trino可以访问各种数据源的数据。
每个目录都与一个特定的连接器相关联。如果你检查一个目录配置文件,你会看到每个目录都包含一个强制性的属性connector.name,它被目录管理器用来为一个特定的目录创建一个连接器。有可能让一个以上的目录使用同一个连接器来访问一个类似数据库的两个不同实例。例如,如果你有两个Hive集群,你可以在一个Trino集群中配置两个目录,都使用Hive连接器,允许你从两个Hive集群中查询数据,甚至在同一个SQL查询中。
Catalog 目录
一个Trino目录包含schema,并通过连接器引用一个数据源。例如,你可以配置一个JMX目录,通过JMX连接器提供对JMX信息的访问。当你在Trino中运行SQL语句时,你是在针对一个或多个目录运行它们。目录的其他例子包括Hive目录,以连接到Hive数据源。
当在Trino中寻址一个表时,全限定的表名总是基于一个目录中。例如,全称表名hive.test_data.test指的是hive目录中test_data模式中的test表。
目录是在存储在Trino配置目录下的属性文件中定义的
Schema 模式
模式是组织表的一种方式。目录和模式共同定义了一组可以被查询的表。当使用Trino访问Hive或关系型数据库(如MySQL)时,模式会在目标数据库中转化为相同的概念。其他类型的连接器可以选择以对底层数据源有意义的方式将表组织成模式。
Table 表
表是一组无序的行,它们被组织成带有类型的命名列。这与任何关系型数据库中的情况相同。从源数据到表的映射是由连接器定义的。
查询执行模型
Trino执行SQL语句,并将这些语句变成查询,在协调器和工作者的分布式集群中执行。
Statement 语句
Trino执行的是与ANSI兼容的SQL语句。当Trino文档中提到语句时,它指的是ANSI SQL标准中定义的语句,它由子句、表达式和谓词组成。==>SQL文本
这一节列出了语句和查询的不同概念。这是必要的,因为在Trino中,语句只是指用SQL编写的语句的文本表示。当一个语句被执行时,Trino会创建一个查询和一个查询计划,然后分布在一系列的Trino工作机中。
Query 查询
当Trino解析一个语句时,它将其转换为一个查询,并创建一个分布式查询计划,然后将其实现为一系列在Trino工作机上运行的相互连接的阶段。当你在Trino中检索关于一个查询的信息时,你会收到一个参与产生响应语句的结果集的每个组件的快照。
语句和查询之间的区别很简单。语句可以被认为是传递给Trino的SQL文本,而查询是指为执行该语句而实例化的配置和组件。一个查询包括阶段、任务、分片、连接器和其他组件和数据源,它们协同工作以产生一个结果。
Stage 阶段
当Trino执行一个查询时,它是通过将执行分成一个层次的阶段来进行的。例如,如果Trino需要汇总存储在Hive中的10亿行的数据,它通过创建一个root阶段来汇总其他几个阶段的输出,所有这些阶段都被设计用来实现分布式查询计划的不同部分。
组成一个查询的阶段的层次结构类似于一棵树。每个查询都有一个root阶段,它负责汇总其他阶段的输出。阶段是协调器用来模拟分布式查询计划的东西,但阶段本身并不在Trino工作机上运行。
Task 任务
任务是Trino架构中的 “工作骡子”,因为分布式查询计划被分解成一系列的阶段,然后被转化为任务,然后对分片进行操作或处理。一个Trino任务有输入和输出,就像一个阶段可以由一系列的任务并行执行一样,一个任务也在与一系列的驱动器并行执行。
Split 分片
任务对分片进行操作,分片是一个更大的数据集的一部分。分布式查询计划中最底层的阶段通过连接器的分片检索数据,而分布式查询计划中较高层次的中间阶段则从其他阶段检索数据。
当Trino调度一个查询时,协调器会查询一个连接器,以获得一个表的所有分片的列表。协调器跟踪哪些机器正在运行哪些任务,以及哪些分片正在被哪些任务处理。
Driver 驱动
任务包含一个或多个并行驱动。驱动程序作用于数据,并结合运算符产生输出,然后由任务汇总,再交付给另一个阶段的另一个任务。驱动程序是一个运算器实例的序列,或者你可以把驱动程序看成是内存中运算器的物理集合。它是Trino架构中最低级别的并行性。一个驱动器有一个输入和一个输出。
Operator 操作
一个运算符消耗、转换和产生数据。例如,表扫描从连接器中获取数据,并产生可被其他运算符消耗的数据,而过滤器运算符通过对输入数据应用一个谓词来消耗数据并产生一个子集。
Exchange 交换
交换器在Trino节点之间传输数据,用于查询的不同阶段。任务产生数据到输出缓冲区,并使用交换客户端从其他任务中消费数据。
延伸的具象化
- Trino的启动
- 查询的提交
- 处理的最小数据单元Page
- 执行计划的构建
- sql语法树的解析
- 逻辑计划的调度
- Task的具体执行
二、Trino的部署说明
CentOS7 部署Trino 集成Hive
前提条件
-
下载Trino的安装包(https://trino.io/download.html)
-
server: trino-server-418.tar.gz
-
client: trino-cli-418-executable.jar
-
-
64位Linux操作系统
-
调整用户的文件描述符的大小。官网推荐以下限制,通常可以在
/etc/security/limits.conf中设置:trino soft nofile 131072 trino hard nofile 131072 -
64位JDK17.0.3+
-
建议在操作系统层面禁用交换空间
操作步骤
部署结构
| IP | Coordinator&Worker | Coordinator | Worker |
|---|---|---|---|
| 192.168.1.11 | yes | ||
| 192.168.1.10 | yes | ||
采用单个节点即是协调器又是Worker的部署方式。
部署服务端
#### 新建用户组与用户
groupadd trino -g 1000;
useradd -g trino -u 1000 trino;
#### 创建对应的文件夹
mkdir -p /home/trino/software;
mkdir -p /opt/software/trino;
mkdir -p /opt/software/trino/logs;
mkdir -p /data01/trino_demo1;
mkdir -p /data01/trino_demo1/hive-cache;
#### 将安装包解压出来与创建软链接
tar -zxvf /opt/software_package/jdk-17_linux-x64_bin.tar.gz -C /opt/software/trino/;
tar -zxvf /opt/software_package/trino-server-418.tar.gz -C /opt/software/trino/;
ln -nsf /opt/software/trino/jdk-17.0.7 /home/trino/software/java;
ln -nsf /opt/software/trino/trino-server-418 /home/trino/software/trino-server;
ln -nsf /opt/software/trino/logs /home/trino/logs;
#### 配置trino用户JDK
vim /home/trino/.bashrc
export JAVA_HOME=/home/trino/software/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
source /home/trino/.bashrc
#### 配置trino--文件的填充内容见下文配置说明章节
mkdir -p /opt/software/trino/trino-server-418/etc;
mkdir -p /opt/software/trino/trino-server-418/etc/catalog;
mkdir -p /home/trino/software/trino-server/etc/hadoop;
vim /opt/software/trino/trino-server-418/etc/node.properties
vim /opt/software/trino/trino-server-418/etc/jvm.config
vim /opt/software/trino/trino-server-418/etc/config.properties
vim /opt/software/trino/trino-server-418/etc/log.properties
vim /opt/software/trino/trino-server-418/etc/catalog/hive.properties
chown -R trino:trino /home/trino;
chown -R trino:trino /opt/software/trino;
chown -R trino:trino /data01/trino_demo1;
# 启动TrinoServer
su - trino
sh software/trino-server/bin/launcher start
# 检查启动日志
less /data01/trino_demo1/var/log/launcher.log
less /data01/trino_demo1/var/log/server.log
部署Cli客户端
su - trino
# 为Cli客户端jar增加执行权限
chmod +x /opt/software/trino/trino-cli-418-executable.jar
# 创建软链接执行
ln -nsf /opt/software/trino/trino-cli-418-executable.jar /home/trino/software/trino-cli
cd /home/trino/software/
# 启动客户端 --server是coordinator的地址
./trino-cli --server http://10.244.68.11:9999 --user bigdata
# 查询连接器目录 catalogs
show catalogs;
# 指定连接器启动
./trino-cli --server http://190.168.1.1:9999 --catalog hive
./trino-cli --server http://190.168.1.1:9999 --catalog hive --schema testdb
# 查询 catalog(hive)下的schemas
show schemas from hive;
配置说明
配置trino服务端
在安装目录内创建一个etc目录。这里面有以下配置:
-
node.properties:节点的环境配置node.environment=trino_demo1 node.id=ffffffff-ffff-ffff-ffff-ffffffffffff # 不支持多目录 node.data-dir=/data01/trino_demo1上述属性描述如下:
node.environment: 环境的名称。一个集群中的所有Trino节点必须有相同的环境名称。该名称必须以小写字母、数字字符开始,并且只包含小写字母、数字或下划线(_)字符。node.id: 这个Trino安装的唯一标识符。这对每个节点都必须是唯一的。这个标识符在Trino的重启或升级中应保持一致。如果在一台机器上运行多个Trino安装(即同一台机器上的多个节点),每个安装必须有一个唯一的标识符。该标识符必须以字母、数字字符开始,并且只包含字母数字、-或_字符。node.data-dir: 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。日志路径默认在node.data-dir配置的目录下的var/log,子目录中。
-
jvm.config:Java虚拟机的命令行选项,官网推荐配置:# 开启debug模式 端口号8787 -agentlib:jdwp=transport=dt_socket,address=*:8787,server=y,suspend=n # 指明用户 -DHADOOP_USER_NAME=bigdata -server -Xmx16G -XX:InitialRAMPercentage=80 -XX:MaxRAMPercentage=80 -XX:G1HeapRegionSize=32M -XX:+ExplicitGCInvokesConcurrent -XX:+ExitOnOutOfMemoryError -XX:+HeapDumpOnOutOfMemoryError -XX:-OmitStackTraceInFastThrow -XX:ReservedCodeCacheSize=512M -XX:PerMethodRecompilationCutoff=10000 -XX:PerBytecodeRecompilationCutoff=10000 -Djdk.attach.allowAttachSelf=true -Djdk.nio.maxCachedBufferSize=2000000 -XX:+UnlockDiagnosticVMOptions -XX:+UseAESCTRIntrinsics # Disable Preventive GC for performance reasons (JDK-8293861) -XX:-G1UsePreventiveGCXmx的大小建议使用占总可用内存的70%到85%的数值- 建议在生产集群中使用超过32GB的大内存分配。
-
config.properties:Trino服务配置文件。# 即是协调器 又是工作机的配置 coordinator=true node-scheduler.include-coordinator=true http-server.http.port=9999 discovery.uri=http://192.168.1.1:9999# 纯工作机配置 coordinator=false http-server.http.port=9999 # 协调器的服务发现地址 discovery.uri=http://192.168.1.11:9999# 纯协调器配置 coordinator=true node-scheduler.include-coordinator=false http-server.http.port=9999 discovery.uri=http://192.168.1.1:9999每台Trino服务器都可以作为coordinator和worker。
一个集群需要包括一个coordinator,将一台机器专门用于只执行协调工作,在更大的集群上提供最佳性能。并行化是通过使用许多worker来实现的。
属性说明
coordinator: 允许这个Trino实例作为一个coordinator,所以要接受客户的查询并管理查询的执行。node-scheduler.include-coordinator: 允许在coordinator上进行工作调度。对于较大的集群,在coordinator上处理工作会影响查询性能,因为机器的资源无法用于调度、管理和监控查询执行的关键任务。http-server.http.port: 指定HTTP服务器的端口。Trino使用HTTP进行所有通信,包括内部和外部。discovery.uri: Trino coordinator有一个发现服务,所有节点都用它来寻找对方。每个Trino实例在启动时向发现服务注册,并不断地心跳以保持其注册的有效性。发现服务与Trino共享HTTP服务器,因此使用相同的端口。替换example.net:8080以匹配Trinocoordinator的主机和端口。如果你在coordinator上禁用了HTTP,URI方案必须是https,而不是http。
-
log.properties:日志配置文件io.trino=INFO io.trino.server.PluginManager=DEBUG com.ning.http.client=WARN允许为命名的日志记录器层次设置最小日志级别。每个日志记录器都有一个名字,通常是使用该日志记录器的类的完全合格名称。记录仪有一个基于名称中的点的层次结构,就像Java包。
这将为
io.trino.server和io.trino.plugin.hive设置最小级别为INFO。默认的最小级别是INFO。有四个级别:DEBUG、INFO、WARN和ERROR。 -
catalog:连接器目录,连接器的配置文件存放地址 -
hadoop:hadoop配置文件的存放目录
[trino@trino-server11 software]$ ll trino-server/etc/
total 24
drwxrwxr-x 2 trino trino 4096 Jun 2 14:05 catalog
-rw-r--r-- 1 trino trino 123 May 18 17:00 config.properties
drwxrwxr-x 2 trino trino 4096 May 18 20:05 hadoop
-rw-r--r-- 1 trino trino 637 Jun 2 20:00 jvm.config
-rw-r--r-- 1 trino trino 77 May 19 13:52 log.properties
-rw-r--r-- 1 trino trino 108 May 19 14:35 node.properties
Hive连接器
- Hive连接器需要一个Hive元存储服务(HMS),或者Hive元存储的兼容实现。
- 支持Apache Hadoop HDFS 2.x和3.x。
- 协调者和所有工作机都必须有对Hive元存储(HMS)和存储系统(如HDFS)的网络访问。
- 使用Thrift协议访问Hive元存储。
- 集成架设在实现了HA的HDFS集群的Hive时,Trino需要拥有hdfs集群的配置文件
core-site.xml,hdfs-site.xml。通过hive.config.resources属性来设置HDFS配置文件
hive.properties配置文件:
connector.name=hive
hive.metastore.uri=thrift://190.168.1.1:9083,thrift://190.168.1.2:9083
hive.config.resources=/home/trino/software/trino-server/etc/hadoop/core-site.xml,/home/trino/software/trino-server/etc/hadoop/hdfs-site.xml
# 可选
hive.allow-add-column=true
hive.allow-drop-column=true
hive.allow-drop-table=true
hive.allow-rename-table=true
hive.allow-comment-table=true
hive.allow-comment-column=true
hive.allow-rename-column=true
# 缓存
hive.cache.enabled=true
hive.cache.start-server-on-coordinator=true
hive.cache.location=/data01/trino_demo1/hive-cache
# 对于即是协调器又是Work机的节点需要开启一下配置,才能开启缓存
hive.cache.start-server-on-coordinator=true
小结
Trino使用了主从式的架构,但是对于协调器没有实现HA,这样会形成单点问题。协调器不可用后,整个集群就不可用了。
插件的更新和数据源的变更需要重启整个集群,不支持热更新。
三、Windows下 IDEA编译与远程调试 Trino
环境
- IDEA 2021.2
- JDK17(不能低于17.0.4)
- MAVEN 3.9.1
- git
- Cygwin
- 418版本的Trino源码
源码编译
解压出源码包trino-418
-
修改
.mvn\wrapper\maven-wrapper.properties,配置本地distributionUrl。distributionUrl=file:///D:/backup/maven/apache-maven-3.9.2-bin.zip -
修改root模块的pom文件
<!-- properties标签下中增加跳过checkstyle --> <air.check.fail-checkstyle>false</air.check.fail-checkstyle> <air.check.skip-checkstyle>true</air.check.skip-checkstyle> <!-- git-commit相关的plugin 跳过git目录要求,插件的<configuration>下增加 --> <configuration> <failOnNoGitDirectory>false</failOnNoGitDirectory> <runOnlyOnce>true</runOnlyOnce> <injectAllReactorProjects>true</injectAllReactorProjects> <offline>true</offline> <!-- A workaround to make build work in a Git worktree, see https://github.com/git-commit-id/git-commit-id-maven-plugin/issues/215 --> <useNativeGit>true</useNativeGit> </configuration>
在Git Bash中执行编译命令,hive2版本的编译命令 mvn -pl '!docs' clean install -DskipTests。跳过docs模块。
导入IDEA
第一次构建Trino后,可以将项目加载到IDEA中并运行服务器。在IntelliJ中,从快速启动框中选择打开项目,或从文件菜单中选择打开,选择根pom.xml文件。
在IntelliJ中打开项目后,仔细检查是否为该项目正确配置了Java SDK:
- 打开文件菜单,选择项目结构
- 在SDK部分,确保选择了JDK 17(如果没有,则创建一个)。
- 在项目部分,确保项目语言级别被设置为17
启动前修改代码
// 1.注释类TrinoSystemRequirements的以下内容
failRequirement("Trino requires Linux or Mac OS X (found %s)", osName);
// 2.调整类TrinoSystemRequirements下的方法getMaxFileDescriptorCount
private static OptionalLong getMaxFileDescriptorCount()
{
// return Stream.of(ManagementFactory.getOperatingSystemMXBean())
// .filter(UnixOperatingSystemMXBean.class::isInstance)
// .map(UnixOperatingSystemMXBean.class::cast)
// .mapToLong(UnixOperatingSystemMXBean::getMaxFileDescriptorCount)
// .findFirst();
Object maxFileDescriptorCount = 10000;
return OptionalLong.of(((Number) maxFileDescriptorCount).longValue());
}
// 3.调整类DevelopmentLoaderConfig的仓库地址
private String mavenLocalRepository = "E:\\maven\\localRepository";
private List<String> mavenRemoteRepository = ImmutableList.of("https://maven.aliyun.com/repository/public");
修改根模块POM
<!--增加以下配置-->
<repositories>
<repository>
<id>aliyun-repos</id>
<name>aliyunrepository</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>aliyun-plugin-repos</id>
<name>aliyun Plugin Repositories</name>
<url>https://maven.aliyun.com/repository/central</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginReposit 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3002
3002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











