






Learning Physics-guided Face Relighting under Directional Light
这项工作描述了一种神经结构,它结合了物理引导的再照明过程的优点和深层神经网络的表现形式。值得注意的是,该方法是端到端训练,同时学习图像去照明和重新照明。引入了一个新的人脸数据集,具有不同的照明条件和姿势,并证明该方法可以真实地重新照明复杂的非漫反射材料,如人脸。我们的定向照明表示不需要平滑照明环境的假设,并且允许我们将任意复杂的输出照明概括为点光源的简单和。
- 方法介绍
本文提出了一种图像形成过程:
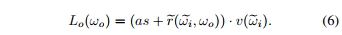
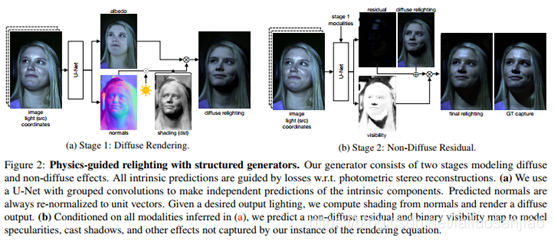
提出的物理指导解决重照明任务的方法包括一个从观察图像中推断内在成分的识别模型(去照明)和一个从内在成分中产生重照明图像的生成模型(重照明)。识别模型采用传统CNN的形式,生成模型遵循我们的图像形成过程(论文第3.1节),并由具有清晰物理意义的结构化层表示。根据(6),我们将后者实现为两个阶段的过程:(第1阶段)使用所需的目标照明,计算预测法线的着色,并将结果与反照率估计相乘,以获得漫反射渲染;(第2阶段)以第1阶段中预测的所有固有状态为条件,我们推断出一个残差图像和一个可见性贴图,我们将其与根据(6)的漫反射渲染相结合。该流程的一个例子如图2所示。由于它的所有操作都是可微的并且是直接叠加的,这使得我们能够从输入到relit结果以端到端的方式学习所提出的模型。
文章为所有内部预测引入损失,即反照率、法线、着色、漫反射渲染、可见性和残差。我们强调使用正确损失函数的重要性,在论文第5.1节进行全面研究。为了在训练过程中获得相应的引导,我们使用标准的光度立体重建。
- 数据集构建
该项目数据包括在不同光照条件下捕捉到的一系列不同的面部表情。
2.1 数据获取
通过一个校准的多视角光台(包括6个固定索尼PMW-F55摄像机和32个白色LED灯)记录数据。共记录了21名受试者,得到2961408个重照明对。每一对都是使用32个灯光中的任意一个作为输入,任何一个从相同的序列和相同的相机中获取作为输出。将其分为81%(17名受试者)进行训练,9.5%(2名受试者)进行验证,9.5%(2名受试者)进行测试。在提取原始数据之后,使用光度立体(PMS)重建将输入图像I分离为反照率A、具有相应法线的阴影S和每帧的非漫反射残差图像R=I – A ⊙ S。
2.2 数据增广
文章执行了一系列数据扩充步骤,试图在整个重照明参数空间中建立强相关性:
(1)我们沿着水平轴和垂直轴翻转所有训练图像,将有效数据集大小增加4倍
(2)我们对图像、阴影、残差和光照强度进行线性缩放。在实践中,我们没有观察到与无缩放增广相比有实质性益处
(3) 我们用高斯噪声随机扰动光校准,以提高泛化能力并使校准误差最小
(4) 对于定量结果,我们进行空间重缩放到原始图像分辨率(135 x256)的1/8,对大小为128x128的随机crops进行训练,并对具有相同分辨率的中心crops进行测试,以与SfSNet具有可比性。定性结果是通过重新缩放到原始分辨率(540 x 1024)的1/2生成的,在大小为512x768的随机crops上进行训练,并在该分辨率的中心crops上进行测试。 - 实验效果
本文模型是使用PyTorch实现的,带有U-Net生成器和PatchGAN鉴别器(用于最终的relit图像),基于pix2pix提供的实现。
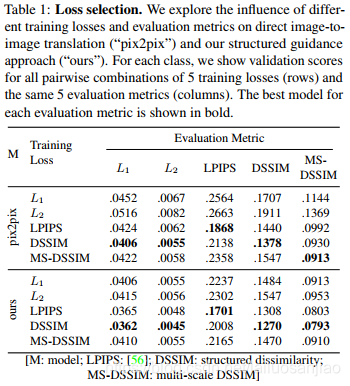
3.1 损失函数与评价指标
由于L1和L2范数度量图像重建误差不符合人类的感知反应,文章还考虑了“Learned Perceptual Image Patch Similarity”(LPIPS)损失。图像质量评估的另一个主要指标是结构相似性(SSIM)及其多尺度变体(MS-SSIM)[49]。在评估中,使用相应的相异性度量DSSIM=(1 – SSIM)/2,同样地,对于MS-SSIM,也使用相应的相异性度量来一致地记录errors。
使用DSSIM来处理训练损失始终会导致模型在使用大多数错误度量的验证集上得到更好的泛化。因此,文章选择在DSSIM上训练的模型来计算最终的测试结果。
3.2 性能评估






- 开源代码
项目网址:https://lvsn.github.io/face-relighting














 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









