







应用稳定性测试方法
开发和维护Android应用程序几乎不可能没有bug, 但要想尽可能发现程序中的bug,需要系列强有力的自动化测试工具:
- 随机事件测试: Monkey
- 固定时间测试
- MonkeyRunner
- uiautomator
- MTBF(运行商认证使用此工具)
- 固定功能测试:基于JUnit的TestCase
- Java语法检查:
- Coverity(付费,静态和动态检查)
- FindBugs(Eclipse插件,静态检查)
- Android语法检查:
- Lint(DDMS插件功能 + SDK命令行工具)
Monkey
Android自带的测试工具,能够长时间持续发送伪随机触屏和按键时间,是做压力测试最重要的自动化测试工具
使用方法
$ adb shell monkey [options] <event-count>MokeyRunner
使用Python编写的自动化测试脚本,可以指定一系列屏幕特定位置的点击事件,模拟手动测试,主要用来长时间循环进行功能测试
使用方法
$SDK/tools/monkeyrunner test.pyuiautomator
与MonkeyRunner功能类似,但不同的是提供了一套Java编写的封装了JUit的API,使用这套API可以开发出一系列更为强大的自动化功能测试用例
使用方法
adb shell uiautomator runtest <JARS> -c <CLASSES> [options]例如:
adb shell uiautomator runtest LaunchSettings.jar -c
com.uia.example.my.LaunchSettingsCoverity
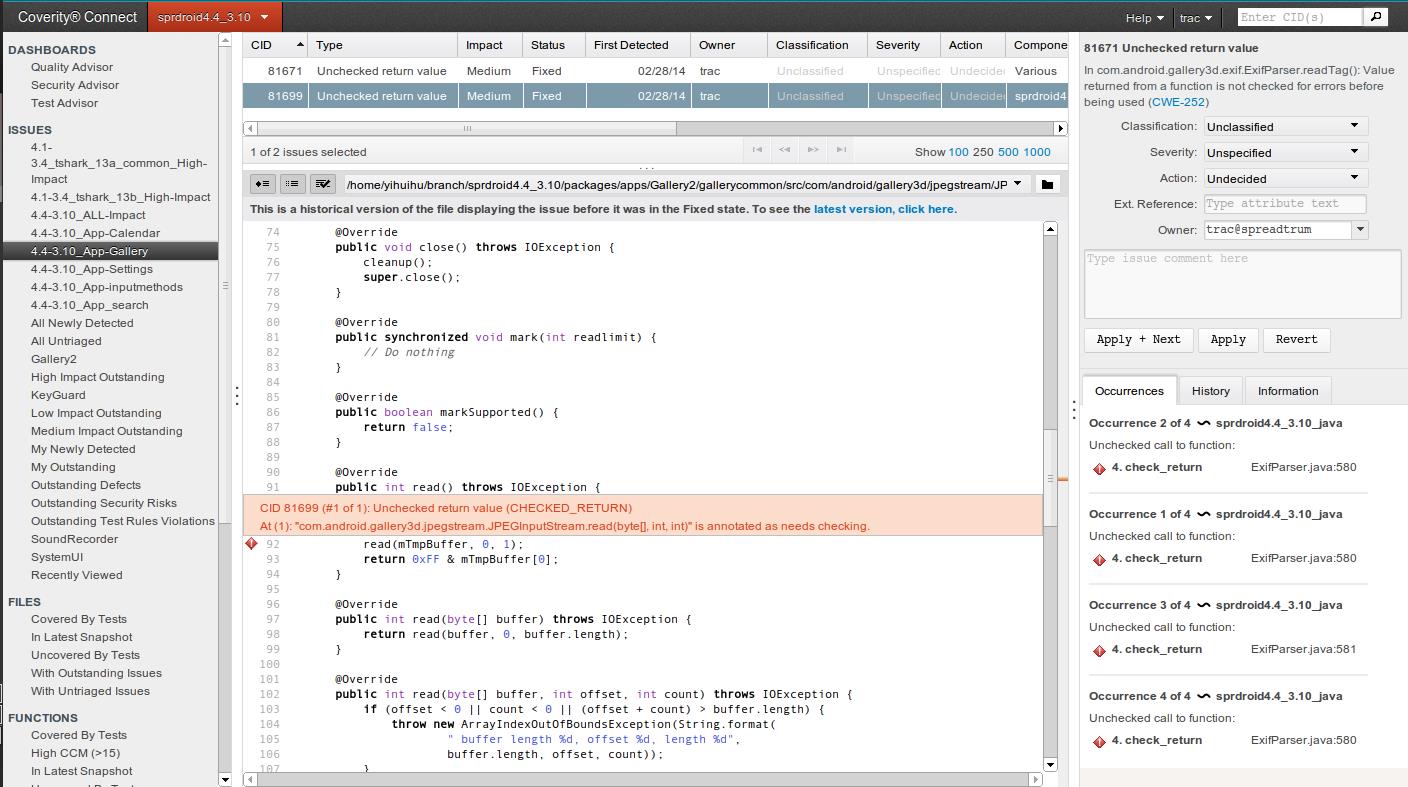
Lint
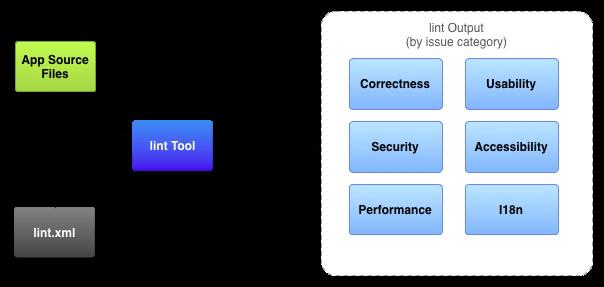
Android自带代码检查工具,可以实时对代码进行扫描,基于Android应用的各种特性给出以下六个方面的建议:
应用稳定性常见问题和分析方法
- 对于Android应用通常遇到的稳定性问题可以分为几个大类:
- ANR
- JavaCrash
- NativeCrash
ANR
- ANR问题类型
- 用户输入事件处理超时
- BroadcastReceiver执行超时
- Service各生命周期函数执行超时
- ContentProvider相关操作执行超时
用户输入事件处理超时
- 用户输入事件处理超时,主线程对输入事件在5秒内没有处理完毕
// How long we wait until we timeout on key dispatching.
static final int KEY_DISPATCHING_TIMEOUT = 5*1000;- 分析方法
- 首先查看logcat main log中发生ANR时间点的CPU使用信息,通过ago/after确认该时刻是哪个进程/线程占用CPU高
- 如果是发生ANR的进程,则继续查看相应的traces.txt确认该进程的主线程的调用栈阻塞原因
- 如果不是,则说明发生ANR进程没有抢占到CPU,需要分析占用CPU高的原因
- 主线程在处理Activity业务逻辑时需要避免耗时操作,例如启用子线程(Thread/AsyncTask等)、避免不必要的跨进程调用、避免不必要的内存申请、减少内存申请的大小。
BroadcastReceiver执行超时
- 主线程在执行BroadcastReceiver的onReceiver函数时10/60秒内没有执行完毕
// How long we allow a receiver to run before giving up on it.
static final int BROADCAST_FG_TIMEOUT = 10*1000;
static final int BROADCAST_BG_TIMEOUT = 60*1000;- 分析方法同上
- BR.onReceive()也是执行在主线程中的,不能执行太耗时的操作,可以考虑将耗时操作交给Service处理,或者启动子线程处理
Service各生命周期函数执行超时
- 主线程在执行Service的各生命周期函数时20秒内没有执行完毕
// How long we wait for a service to finish executing.
static final int SERVICE_TIMEOUT = 20*1000;- 分析方法同上
- Service可以用来执行较长时间的操作,但也只有20秒。例如一些扫描T卡之类的操作,仍然是采用启动子线程处理的方法较好
ContentProvider相关操作执行超时
- 主线程执行ContentProvider相关操作时没有在规定时间内执行完毕(应用程序自行设置是否启用以及超时时间)
这里写代码片ContentProviderClient.java →
beforeRemote() :例如query函数开始执行此方法
afterRemote :例如query函数结束时执行此方法
setDetectNotResponding():提供给应用自行设置是否启用此功能- 分析方法同上
- 源码中启用此功能的代码
DocumentsUI/src/com/android/documentsui/DocumentsApplication.java
client.setDetectNotResponding(PROVIDER_ANR_TIMEOUT); //20sJavaCrash
- 重点共通性
- OutOfMemory
- GREF has increased to 2001(or more)
OutOfMemory
- 获取hprof(heap profile)
- 应用可通过以下方法设置京城的默认异常处理器
Thead.setDefaultUncaughtExceptionHandler(...) - 在默认异常处理器的uncaughtException方法中判断如果是 OutOfMemoryError错误,则调用以下方法输出当前进程的hprof文件:
Debug.dumpHprofData(...) - 另外一种方法:可以将文件链接到DDMS,使用DDMS的“Dump HPROF File"按钮导出指定进程的hprof文件
- 分析方法
- 使用MAT(MemoryAnalyzerTool)导入hprof文件分析
- 详细说明可见:http://rayleeya.iteye.com/blog/1956059
GREF has increased to 2001(or more)
- 一个进程的DVM实例中全局引用计数超过警示上限,在非User版本中会主动abort,导致进程退出
- 分析方法
- 查看logcat main log,找到出错信息,一般都会有“Failed adding to JNI global ref table”或“GREF has increased to”字样,并且紧跟着后面一个NativeCrash的tombstone的信息
- 找到除了WeakReference外应用数量最多的类,此类90%就是出问题的类
- 分析此类所涉及的业务逻辑中,是否有IBinder.DeathRecipient未能正常调用的情况
NativeCrash
- Android应用中发生DVM环境下C/C++的异常时,DVM会主动调用dvmAbort函数退出进程, 此时会将出错信息输出到logcat中,同事也会在/data/tombstones/目录下保留一份拷贝
- 分析方法
- 需要将tombstone中的异常信息反汇编成可读的函数调用栈信息,找到具体出错的原因
- 源码中编译的addr2line一次只能反汇编一行,可以使用stack_trace.py脚本批量反汇编并格式化
健壮的代码编写技巧
- 防御式编程
- 主要思想:子程序不应该因传入错误数据而被破坏,哪怕是由其他子程序产生的错误数据
- 例子:
- 在函数开始处对输入的实参进行检查
- 使用断言(assert)
- 异常处理时如何判断终止/继续程序运行
- Cursor对象不再使用时需要关闭
- 不要声明static的视图控件变量
- 不要忘记注销监听器
- 通常在成对的Activity生命周期函数中分别调用注册和注销方法
- 适当的使用SoftReference/WeakReference
- 在创建图片缓存的时候考虑使用软引用
- Adapter的getView方法中使用convertView而不是每次都new一个视图对象
- 耗时操作(查询DB)不要放在主线程中
- 善用Android/Java的标准类,安全又高效
- HandlerThread、AsynckTask、ArrayMap、ArraySet、AndroidHttpClient、FileUtils、AtomicFile、LruCache
- 在程序中操作大尺寸图片时,为避免内存溢出,可以先获取图片的尺寸,在根据实际需要显示的区域的大小,在加载图片的时候进行适当的压缩
- 通过Binder传递消息时不要在消息中放置太大的对象
- 不要在intent中放一张较大的图片
- Toast.makeText方法中使用ApplicationContext而不是Activity的Context
- 避免在压力测试时出现Activity销毁但Toast仍然在显示,频繁操作导致内存快速上涨

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









