







 本文详细介绍了哈希表的概念,包括其定义、构造方法(如直接定址法、除留余数法)以及哈希冲突的原因与解决策略(如线性探测、二次探测和开链法)。此外,还探讨了负载因子的重要性,以及在哈希桶实现中使用红黑树提高效率的情况。最后,文章讨论了哈希表的实现细节,包括节点定义、插入、查找、扩容以及迭代器的实现策略。
本文详细介绍了哈希表的概念,包括其定义、构造方法(如直接定址法、除留余数法)以及哈希冲突的原因与解决策略(如线性探测、二次探测和开链法)。此外,还探讨了负载因子的重要性,以及在哈希桶实现中使用红黑树提高效率的情况。最后,文章讨论了哈希表的实现细节,包括节点定义、插入、查找、扩容以及迭代器的实现策略。
学习完二叉搜索树后,我们来学习一种新的结构,哈希表
【前言】:
二叉搜索树具有lgn的搜索时间复杂度,但是是建立在数据有足够的随机性
哈希表是也是具有对数时间复杂度的,但是它是以统计为基础的,并不在乎输入数据的随机性
【哈希表】:
1、定义:
*HashTable-散列表/哈希表,是根据关键字(key)而直接访问在内存存储位置的数据结构。
*它通过一个关键值的函数将所需的数据映射到表中的位置来访问数据,这个映射函数叫做散列函数,存放记录的数组叫做散列表。
*哈希表可以看作是字典结构,它操作的是有名项,提供常数时间的基本操作
2、构造哈希表的几种方法:
1)直接定址法: 该方法是取关键字的某个线性函数值为哈希地址
2)除留余数法: 它是用数据元素关键字除以某个常数所得的余数作为哈希地址。
3)折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。
4)随机数法::选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
5)*数学分析法:找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
一般常用的方法是直接定址法和除留余数法。
取关键字的某个线性函数为散列地址,Hash(Key)= Key 或 Hash(Key)= A*Key + B,A、B为常数。
3、哈希冲突:
1)出现的原因:
当我们通过散列函数进行映射的时候,不同的键值会映射到同一个位置
我用图示说明下:
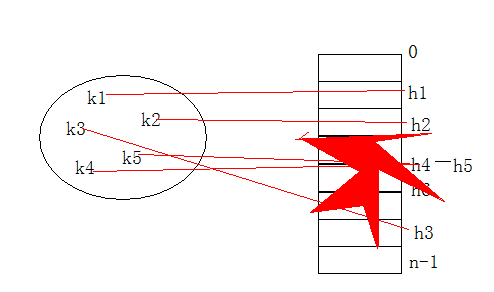
2)如何进行解决:
先介绍一个概念:负载因子
散列表的负载因子:x = 填入表中的元素的个数/散列表的长度
说明:
A:x是散列表装满程度的标志因子。由于表长是定值,x与“填入表中的元素个数”成正比,所以,x越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,x越小,标明填入表中的元素越少,产生冲突的可能型就越小。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3216
3216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









