







在服务与服务的通信过程中,除了基本的http接口调用,还可以使用消息队列,比如RabbitMQ、RocketMQ及Kafka。今天介绍一下Kafa的搭建,依然还是使用docker-compose进行部署。

说到Kafka,就不得不提到ZooKeeper,两者在很长一段时间都是配合使用,但随着kafka3.0的诞生,Kafka可以脱离ZooKeeper独自使用,那我们就从这两种方式进行分析。
第一种方式Kafka3.0之前的版本+ZooKeeper配合使用
1、单节点的zookeeper和kafka
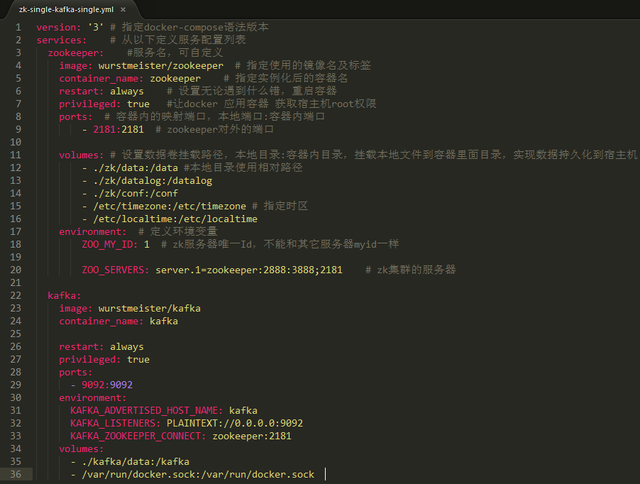
(1)编写docker-compose.yml文件,内容如下:
注意这里面我在volumes里面指定了时区,在执行之前,我通过命令:
echo "Asia/shanghai" > /etc/timezone
设置了时区,然后我就可以执行下面两条命令:
- /etc/timezone:/etc/timezone # 指定时区
- /etc/localtime:/etc/localtime
(2)操作命令(操作基于docker-compose.yml同级目录)
启动kafka服务:docker-compose up -d
关闭kafka服务:docker-compose down
启动之后,会在docker-compose.yml文件下生成zk和kafka两个文件夹,文件夹下是映射的内容。



有人可能会问,上面部署的kafka也没标记版本,怎么知道是3.0之前的版本,我们可以使用命令来查询。先使用 docker ps 查询服务,然后进入 kafka 容器内【可以使用容器名称也可以使用容器id】,命令为:
docker exec -it kafka /bin/bash
最后使用以下命令查询版本,注意前面为scala版本,后面为kafka版本。
find / -name *kafka_* | head -1 | grep -o '\kafka[^\n]*'

可以看出我部署的kafka的版本号为2.8.1【前面为scala版本,后面为kafka版本】。
2、集群zookeeper和kafka(单服务器)
编写docker-compose.yml文件,内容如下(内容较多):

使用docker-compose up -d 启动容器,启动之后查看结构如下【文件夹不需要手动创建,系统会自动创建】:
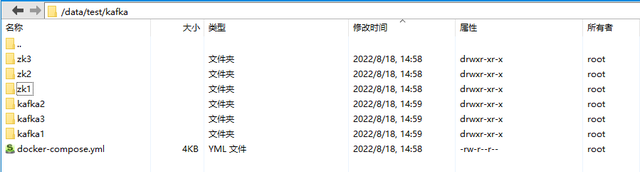
在zk1、zk2、zk3这三个文件目录的conf目录下会自动生成zoo.cfg配置文件,在data目录下会生成myid文件,里面存放的是对应zk的ZOO_MY_ID的值,即zk1下面的myid里面放的是1,zk2下面的myid里面放的是2,zk3下面的myid里面放的是,3.

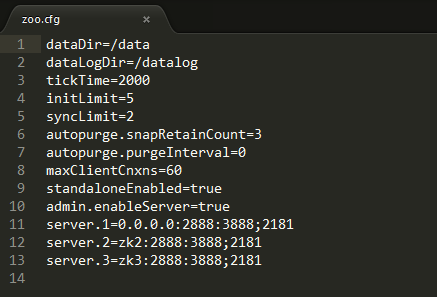
zoo.cfg文件内容如下:
此时我们还需要验证一下zookeeper集群和kafka集群
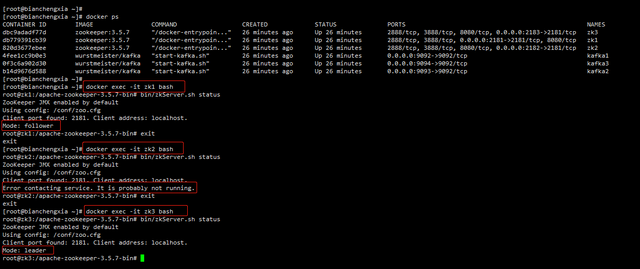
(1)验证zookeeper集群,使用命令docker exec -it 容器名称/容器id bash,进入容器,然后使用 bin/zkServer.sh status 命令查询状态,mode 为leader或follower正常。小编第一次就遇到有两个zk正常,一个不正常,提示:
Error contacting service. It is probably not running
排查这个问题,先检查你的防火墙状态,一般要是关闭状态,以下是防火墙操作的相关命令:
(a)查看防火墙状态:firewall-cmd --state 或者查看firewall服务状态:systemctl status firewalld
(b)关闭firewall:systemctl stop firewalld.service
(c)重启firewall:systemctl restart firewalld.service
(d)启动firewall:systemctl start firewalld.service
若防火墙已关闭,再检查你是否安装了jdk,因为zookeeper的运行需要JVM环境,使用java -version 查询版本即可。小编都不是这些原因,然后通过docker-compose logs -f 查看日志,发现有报错,定位问题,修改,将KAFKA_ZOOKEEPER_CONNECT 里面的配置改成宿主机IP,不要使用zk1:2181,zk2:2182,zk3:2183。重启就可以了。
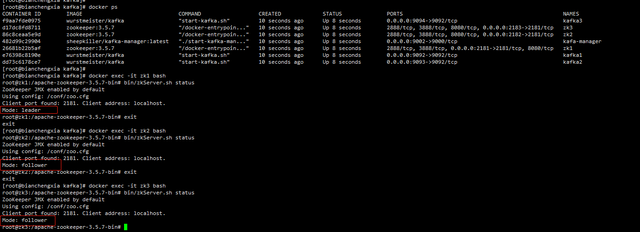
(2)验证kafka集群
在docker-compose.yml中配置过了kafka-manager,他是Kafka基于web的可视化管理工具。访问平台,ip:9002,注意9002是我在yml映射的端口,9002映射到9000。
(a)登录系统,输入账号密码,然后创建cluster:
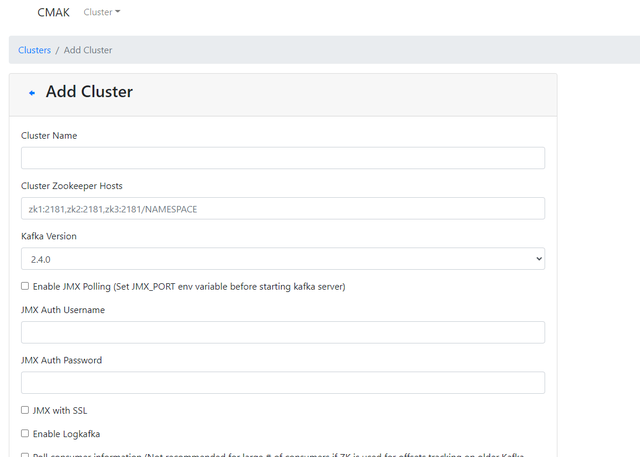
添加成功:

(b)查看kafka集群节点:

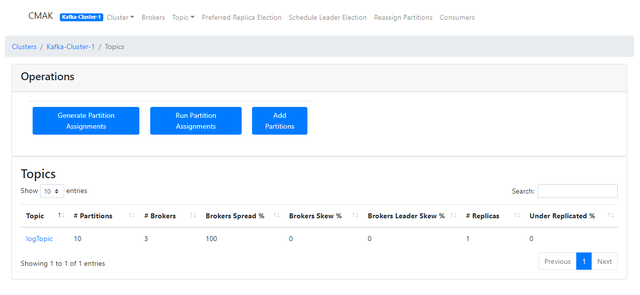
(c)创建Topic

主题(Topic)是kafka消息的逻辑划分,可以理解为是一个类别的名称;kafka通过topic将消息进行分类,不同的topic会被订阅该topic的消费者消费。
当某个topic中的消息非常多时,需要足够大的空间存储,产生的文件也比较大,为了解决文件过大的问题,kafka提出了Partition分区的概念。划分了多个分区(Partition),进行分区存储,达到分段存储kafka中的消息,同时生产者可以并行的写。
问题:kafka分区数Partitions设置多少个比较合适?
虽然分区数设置不受上限,但并不是越多越好,越多的partition意味着需要更多的内存,分配多少个Partitions没有一个严格的标准,更没有一个统一的标准答案,可以参考系统的并发数。我这里设置的日志生产消费的topic,就设置了10个Partition。

第二种方式,Kafka3.0不使用ZooKeeper
在kafka3.0中已经可以将zookeeper去掉,使用kraft机制实现controller主控制器的选举。
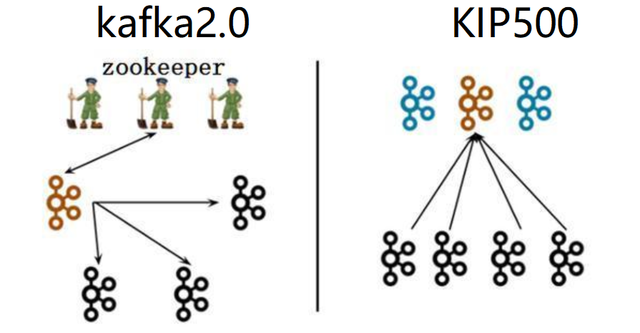
-
左图(kafka2.0):一个集群所有节点都是Broker角色,利用zookeeper的选举能力从三个Broker中选举出来一个Controller控制器,同时控制器将集群元数据信息(比如主题分类、消费进度等)保存到zookeeper,用于集群各节点之间分布式交互。
-
右图(kafka3.0):假设一个集群有四个Broker,配置指定其中三个作为Conreoller角色(蓝色)。使用kraft机制实现controller主控制器的选举,从三个Controller中选举出来一个Controller作为主控制器(褐色),其他的2个备用。zookeeper不再被需要。相关的集群元数据信息以kafka日志的形式存在(即:以消息队列消息的形式存在)
换句话说,就是以前的kafka元数据保存在zk上,运行动态选举controller,由controller进行对kafka的集群管理。kraft模式,不再依赖zk集群,而是用三台controller节点代替zk,元数据保存在controller中,由controller直接对kafka集群进行管理。注意kafka3.0不再支持JDK8,建议安装JDK11。
目前使用kafka3.x系统的很少,相关资料也比较少,建议搭建前期拿来练手可以。
















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











