






失配树fail树
给定一个字符串,m组询问给定p,q,要求s[1~p]和s[1~q]的最长公共前缀。
首先要讲一个概念:Border:对于字符串S,用|S|表示其长度。那么S串的一个Border就是S的某个前缀(S串本身不算),这个前缀能和后缀匹配。举个例子,abcdabc的一个Border是abc。一个字符串的Border可能有多个。
性质1:对于任意一个字符串S,一个Border的长度就对应一个Border(比如abcdabc的长度为3的Border当然就只能是abc)。并且,假设S长度记为n,则S的所有Border的长度分别为:ne[n], ne[ne[n]], ne[ne[ne[n]]].......直到值为0的不算。并且这个序列的值从左往右递减(根据kmp的性质容易得出)
性质2:根据上面的结论,我们可以知道,对一个字符串S求解next数组之后,我们就知道了S所有前缀(包括S自身)的所有Border了。
Fail树是由所有 ne[i] -> i 的单向边构成的树。
性质:结合前面Border的结论,在fail树上,一个结点x不断向上寻找祖先的过程,就是遍历字符串S[1,x]的所有Border长度的过程,又因为Border的长度和Border一一对应,所以fail树上就记录着字符串S所有前缀的Border。
ac代码:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e6+100, M = 1000010;
ll n;
char p[N];
ll fa[N][23],dep[M];
int lca(int x,int y) {
if(dep[x]<dep[y])swap(x,y);
for(int j=20; j>=0; j--)if(dep[fa[x][j]]>=dep[y])x=fa[x][j];
if(x==y)return x;
for(int j=20; j>=0; j--) {
if(fa[x][j]!=fa[y][j]) {
x=fa[x][j],y=fa[y][j];
}
}
return fa[x][0];
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin >> p + 1;
n=strlen(p+1);
fa[0][0]=fa[1][0]=0;
dep[0]=0,dep[1]=1;
for (int i = 2, j = 0; i <= n; i ++ ) {
while (j && p[i] != p[j + 1]) j = fa[j][0];
if (p[i] == p[j + 1]) j ++ ;
fa[i][0]=j;
for (int k = 1; k <= 20; k++) fa[i][k] = fa[fa[i][k - 1]][k - 1];
dep[i] = dep[fa[i][0]] + 1;
}
for(int i=1; i<=21; i++) {
for(int j=1; j<=n; j++) {
fa[j][i]=fa[fa[j][i-1]][i-1];
}
}
int q;
cin>>q;
for(int i=1,x,y; i<=q; i++) {
cin>>x>>y;
int ans=lca(x,y);
if(ans==x||ans==y)ans=fa[ans][0];
cout<<ans<<'\n';
}
return 0;
}
manacher算法
给出一个只由小写英文字符 a,b,c,…y,z 组成的字符串 S ,求 S 中最长回文串的长度 。
字符串长度为 n。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 1e6+100, maxn = 1e7+1e6+1;
char s[maxn<<1],tmp[maxn<<1];
char a[maxn];
int hw[maxn];
int ans;
int n;
void manacher()
{
int maxright=0,mid;
for(int i=1;i<=n-1;i++)
{
if(i<maxright) hw[i]=min(hw[(mid<<1)-i],hw[mid]-(i-mid));
else hw[i]=1;
while(s[i+hw[i]]==s[i-hw[i]])hw[i]++;
if(i+hw[i]>maxright)
{
maxright=hw[i]+i-1;
mid=i;
}
}
//其实是利用回文串的对称性进行求回文串。
}//借助已经求出来的hw[i]来求新的位置的hw
void change()
{
s[0]=s[1]='|';
for(int i=1;i<=n;i++)
{
s[i*2]=a[i];
s[i*2+1]='|';
}
n=n*2+2;
s[n]=0;
}//在字符串中插入'|'来进行更好的一个统计(便于统计长度为偶数的回文串)
int main()
{
scanf("%s",a+1);
n=strlen(a+1);
change();
manacher();
ans=1;
for(int i=0;i<=n-1;i++)ans=max(ans,hw[i]);
cout<<ans-1<<"\n";
}
int manchar(char *s){
memset(hw,0,sizeof(hw));
tmp[0]=tmp[1]='|';
for(int i=1;i<=n;i++){
tmp[i*2]=s[i];
tmp[i*2+1]='|';
}
int l=n*2+2;
tmp[l]=0;
int maxright=0,mid,ans=1;
for(int i=1;i<=l-1;i++){
if(i<maxright) hw[i]=min(hw[(mid<<1)-i],maxright-i);
else hw[i]=1;
while(tmp[i+hw[i]]==tmp[i-hw[i]]) hw[i]++;
if(i+hw[i]>maxright){
maxright=hw[i]+i-1;
mid=i;
}
}
for(int i=0;i<l;i++)ans=max(ans,hw[i]);
return ans-1;
}ac自动机
首先构建一个字典树,加上fail指针

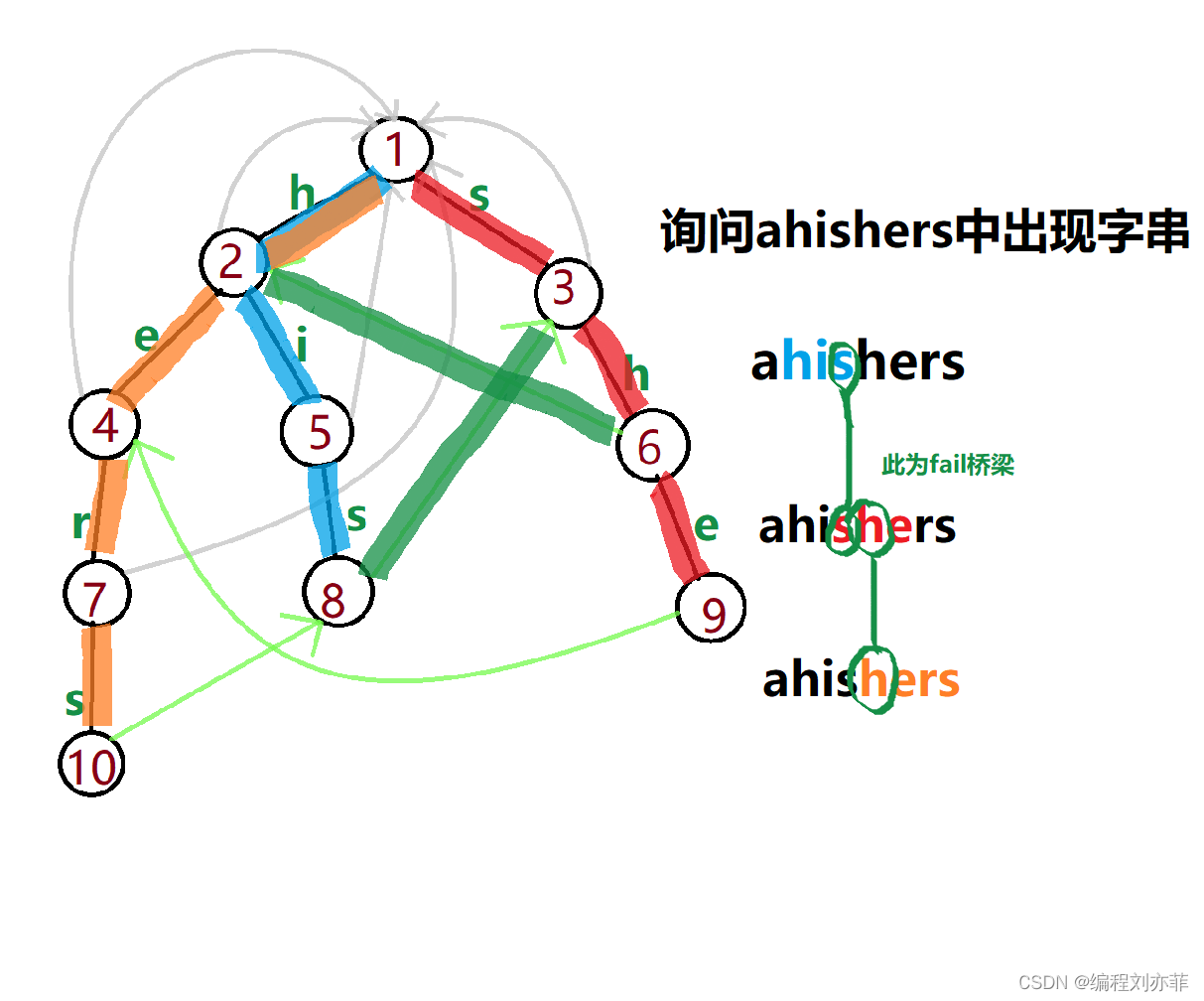
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn=1e6+10;
char str[maxn*10],buf[maxn];
int ans[maxn];
int ct[maxn];
struct AC {
int tot,pre[maxn][26],fail[maxn],pass[maxn];//pass用来表示这个点是单词的结尾,fail是失配指针,pre是儿子
int L,R,que[maxn];//队列部分的操作
vector<int>G[maxn];//x的失配指针到x是一条边,这样存一个图,从0结点就能一直跳了
int newnode() {
tot++;
for(int i=0; i<26; i++)pre[tot][i]=0;
fail[tot]=pass[tot]=ans[tot]=0;
return tot;
}//在给点赋值的同时进行初始化
void init() {
L=R=0;
tot=-1;
newnode();
}
void insert(int q) {
int len=strlen(buf);
int cur=0;
for(int i=0; i<len; i++) {
int t=buf[i]-'a';
if(!pre[cur][t])pre[cur][t]=newnode();
cur=pre[cur][t];
}
pass[cur]=1;
ct[q]=cur;
}
void build() {
for(int i=0; i<26; i++) {
if(pre[0][i])que[R++]=pre[0][i];
}
while(L<R) {
int cur=que[L++];
G[fail[cur]].push_back(cur);
for(int i=0; i<26; i++) {
if(!pre[cur][i])pre[cur][i]=pre[fail[cur]][i];//建立fail指针
else {
que[R++]=pre[cur][i];
fail[pre[cur][i]]=pre[fail[cur]][i];
}
}
}
}
void dfs(int x) {
for(int i=0; i<G[x].size(); i++) {
int y=G[x][i];
dfs(y);
ans[x]+=ans[y];
}
}
void find() {
int len=strlen(str);
int cur=0;
for(int i=0; i<len; i++) {
int t=str[i]-'a';
cur=pre[cur][t];
ans[cur]++;
}
dfs(0);
}
} AC;
int main() {
int n;
scanf("%d",&n);
AC.init();
for(int i=1; i<=n; i++) {
scanf("%s",buf);
AC.insert(i);
}
AC.build();
scanf("%s",str);
AC.find();
int Ans=0;
for(int i=1; i<=n; i++) {
// if(ans[ct[i]]!=0)Ans++;
printf("%d\n",ans[ct[i]]);
}
// printf("%d",Ans);
return 0;
}
/*
ABABABC
ABA
*/














 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









