







前言
本文是我这一系列博客的最后一篇,也是我最终作为作业交给数据挖掘老师的。在写这结课设计的过程,看了很多的博客给我带来很大的帮助,也学习了很多,写这些博客也只是想把自己一点点的经验分享给大家。
选择数据集
种子数据集:https://archive.ics.uci.edu/ml/datasets/seeds
三种不同品种小麦籽粒几何性状的测定。用于软X射线技术和GRAINS构建七个实值属性,所有这些参数都是实值连续的。
1、面积A,
2、周长P,
3、紧凑度C = 4 * pi * A / P ^ 2,4
4、籽粒长度,
5、籽粒宽度,
6、不对称系数
7、核槽的长度。
下载数据的文件格式为.txt格式,将文件格式改为.csv或.xlsx格式。
数据预处理
打开orange软件,进行数据预处理
Rank控件可以根据数据特征的相关性对其进行排名和筛选,双击控件:
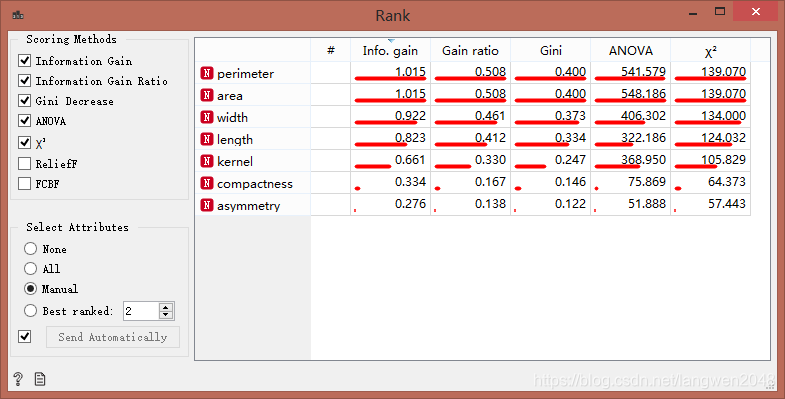
可以看出,compactness和asymmetry特征相关性很低,将其筛除。也可以用Distributions控件通过观察compactness和asymmetry特征值的分布,评价其相关性。
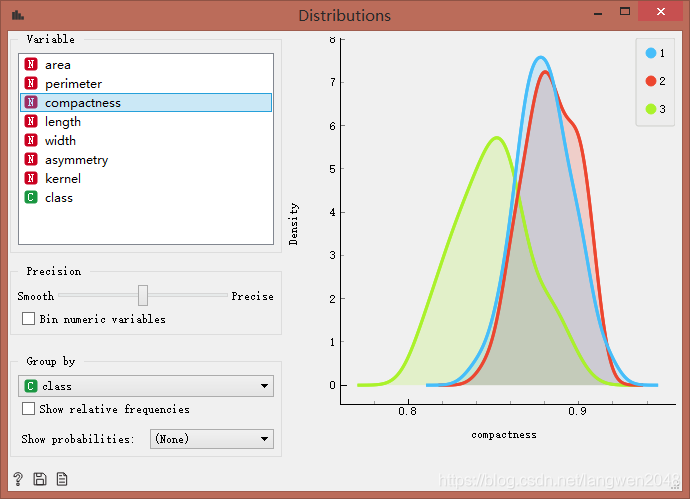
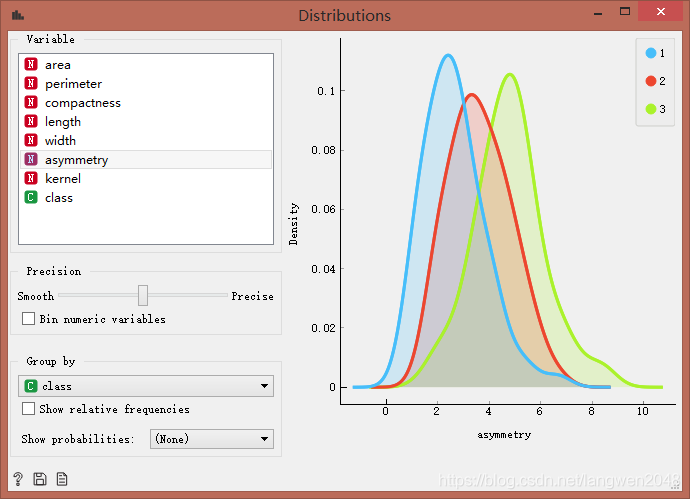
聚类
1、K-means算法
双击K-means控件,设置算法参数:
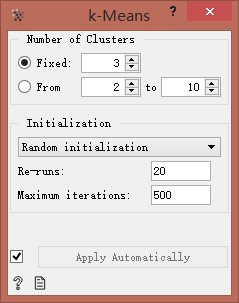
输入固定簇数3,运行结果:
2、K-means++算法
双击K-means控件,选择K-means++算法
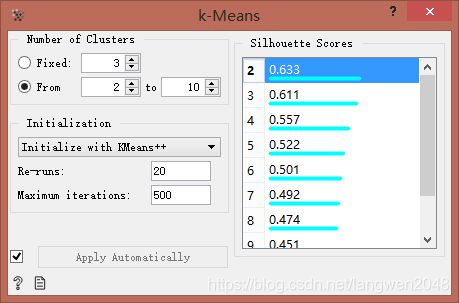
算法对2-10簇群进行打分个,2簇群轮廓分最高,结果为: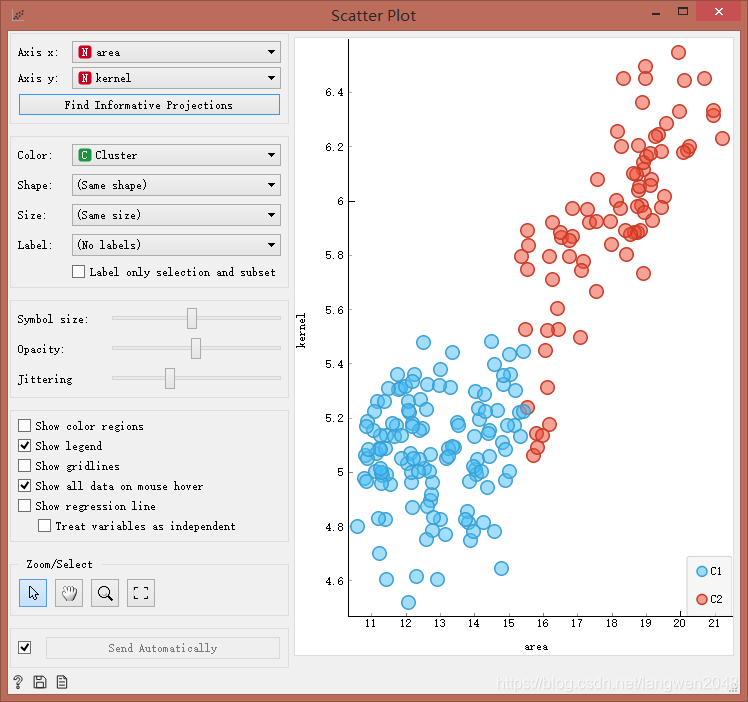
3、层次聚类
先用Distances控件计算成对距离的矩阵,然后用Hierarchical Clustering控件显示从输入距离矩阵构造的层次聚类的树形图
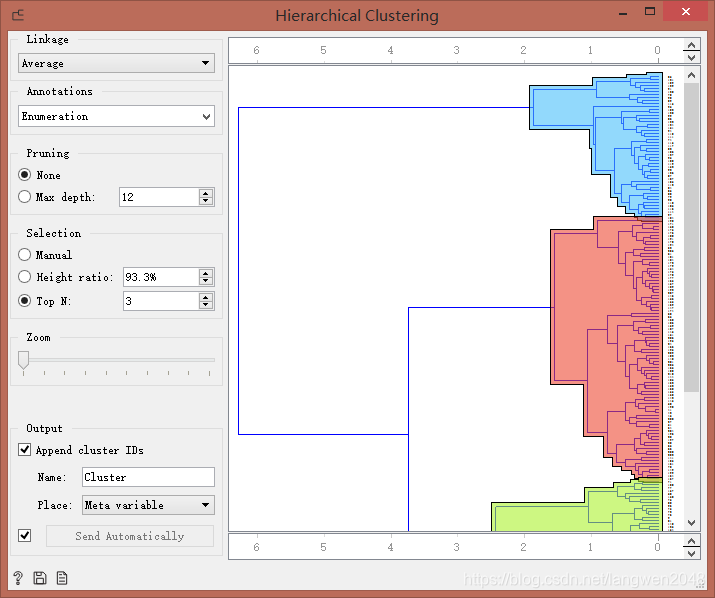
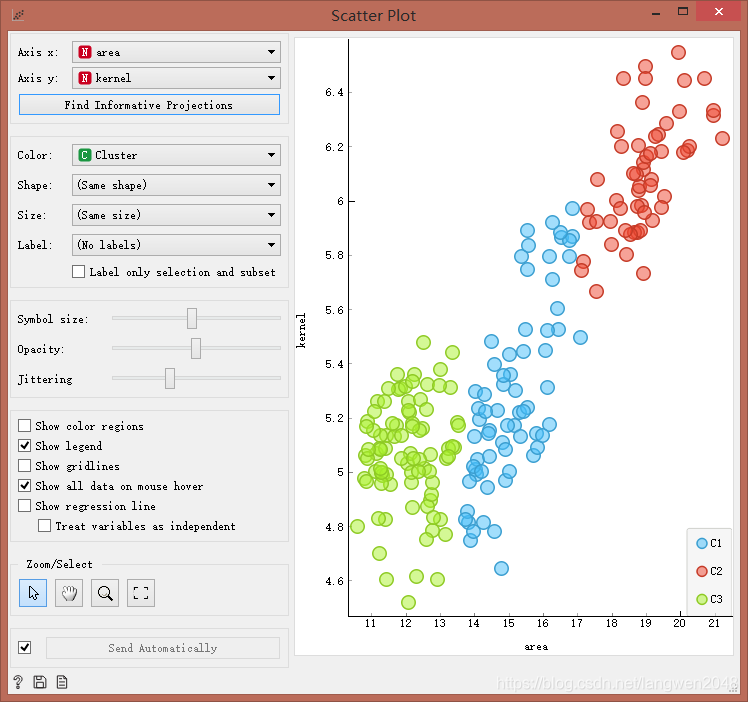
选择Top N = 3,传入数据流到Scatter Plot控件进行可视化: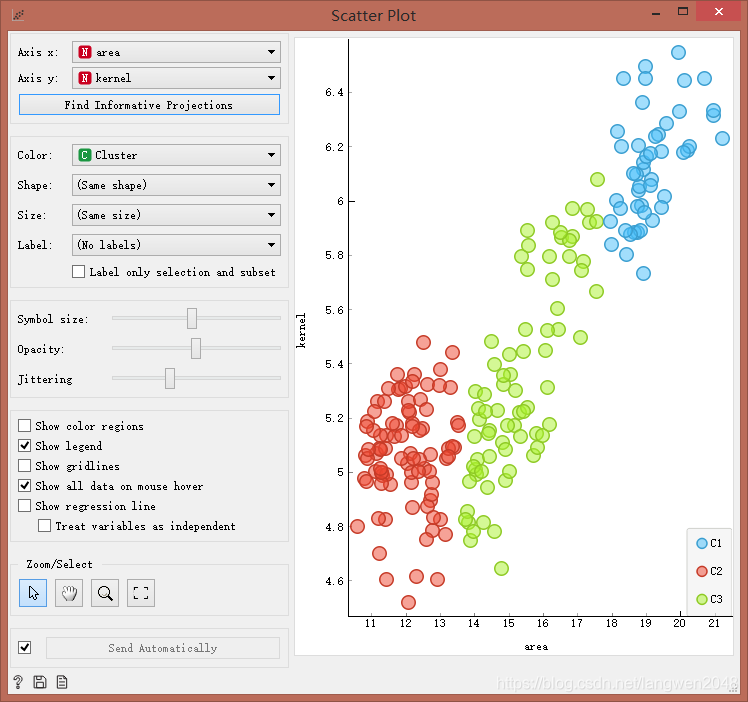
结果分析:
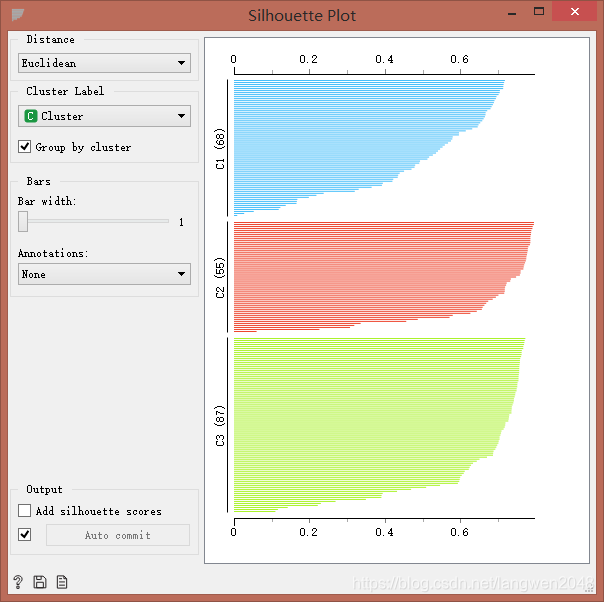
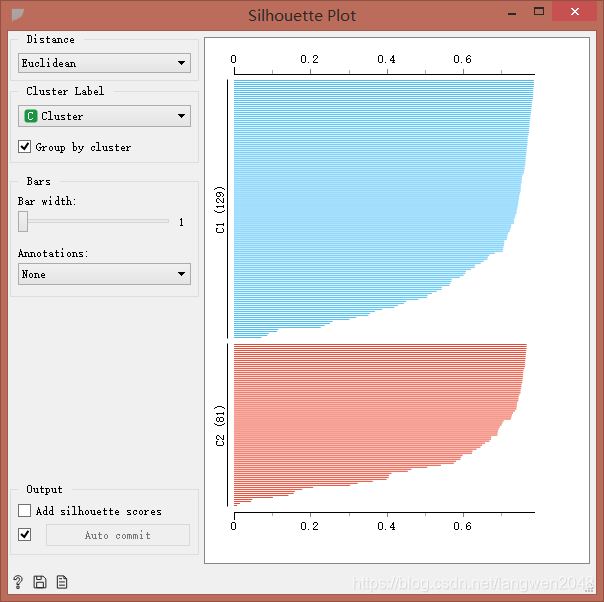
用Silhouette Plot轮廓组件评价聚类效果。数据越靠近数据簇中心,轮廓值越大;离簇中心越远,轮廓值越小:0为位于两簇之间的点,负数为错误划分到别的簇中。
K-means轮廓图:
K-means++轮廓图
层次轮廓图:
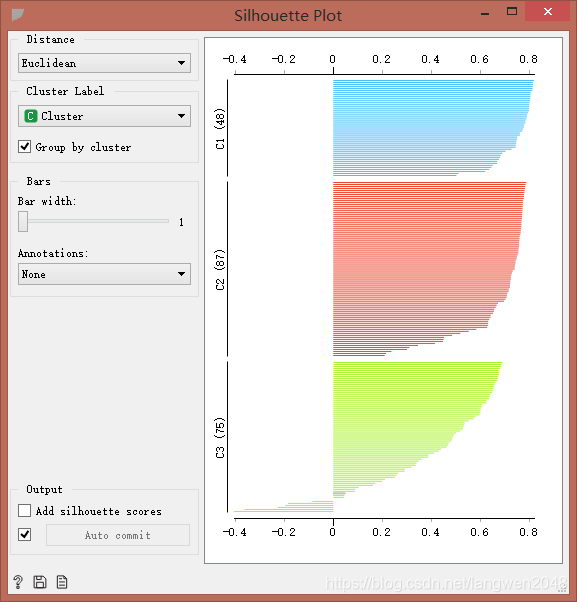
通过对比其轮廓图,我们发现:在对该数据进行聚类时,K-means算法要比层次聚类要好,层次聚类中有出现负值;而k-means++算法将数据聚成两簇,没有达到我预期得到的聚类结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









