







背景:
已经存在如下环境:
Ambari 2.7.5
HDFS 3.2.1
YARN 3.2.1
HIVE 3.1.1 ON MapReduce2 3.2.2
新安装了 Spark2 2.4.8
提交spark任务到yarn集群,不能成功执行
Spark2.4.8遇到的问题与处理方式
错误:java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因:spark自带的guava库版本比较低
处理方法:去除spark自带的旧版的guava库,使用hadoop自带的guava库,重启Spark2
su spark
cd /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars
rm -f guava-14.0.1.jar
ln -s /opt/redoop/apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar guava-27.0-jre.jar
ll guava-27.0-jre.jar
错误:java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.2.2
原因:spark自带的hive库版本比较低
处理方法:去除spark自带的旧版的hive库,使用hive的自己的库,重启Spark2
mkdir -p /root/zsp/spark-2.4.8-bin-hadoop2.7/jars
mv /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/hive*.jar /root/zsp/spark-2.4.8-bin-hadoop2.7/jars
su spark
cd /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-beeline-3.1.1.jar hive-beeline-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-cli-3.1.1.jar hive-cli-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-exec-3.1.1.jar hive-exec-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-jdbc-3.1.1.jar hive-jdbc-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-metastore-3.1.1.jar hive-metastore-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-shims-3.1.1.jar hive-shims-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-shims-common-3.1.1.jar hive-shims-common-3.1.1.jar
ln -s /opt/redoop/apps/apache-hive-3.1.1-bin/lib/hive-shims-scheduler-3.1.1.jar hive-shims-scheduler-3.1.1.jar
ll hive*
错误:java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
原因:spark-hive基于旧版的hive代码,在新版hive中已经不存在对应的字段
处理方法:重新编译Spark之后,拿编译后的spark-hive_2.11-2.4.8.jar替换原来的jar,重启Spark2
cd /usr/local/src
tar -xvf spark-2.4.8.tgz
cd /usr/local/src/spark-2.4.8
修改 /usr/local/src/spark-2.4.8/sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
注释掉 HIVE_STATS_JDBC_TIMEOUT 和 HIVE_STATS_RETRIES_WAIT 所在行
修改 /usr/local/src/spark-2.4.8/pom.xml
加入依赖
<dependency>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</dependency>
./build/mvn -Pyarn -Phadoop-2.7 -Phive -Phive-thriftserver -Dhadoop.version=2.7.3 -DskipTests clean package
su spark
cp -f /usr/local/src/spark-2.4.8/sql/hive/target/spark-hive_2.11-2.4.8.jar /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/
ll /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/spark-hive*
其他机器:
scp root@master:/opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/spark-hive_2.11-2.4.8.jar /tmp/
su spark
cp -f /tmp/spark-hive_2.11-2.4.8.jar /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/
ll /opt/redoop/apps/spark-2.4.8-bin-hadoop2.7/jars/spark-hive*
错误:org.apache.hadoop.hive.ql.metadata.HiveException: InvalidObjectException(message:No such catalog spark)
处理方法:spark配置目录里的hive-site.xml问题,使用hive的配置文件,重启Spark2
su spark
mv /etc/spark/hive-site.xml /etc/spark/hive-site.xml_bak
cp -p /etc/hive/hive-site.xml /etc/spark/
ll /etc/spark/
错误:NoSuchMethodError: org.apache.hadoop.hive.ql.exec.Utilities.copyTableJobPropertiesToConf(Lorg/apache/hadoop/hive/ql/plan/TableDesc;Lorg/apache/hadoop/conf/Configuration;)V
原因:spark jar包与低版本hive一起编译,导致编译的class文件入参类型JobConf转为父类了
处理方法:重新编译Spark之后,拿编译后的spark-hive_2.11-2.4.8.jar替换原来的jar,重启Spark2
此处问题没能解决,最终走向了升级spark
升级到spark3.1.3
spark文件升级
cd /opt/redoop/apps
wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.1.3/spark-3.1.3-bin-hadoop3.2.tgz
tar -xvf spark-3.1.3-bin-hadoop3.2.tgz
mv spark-3.1.3-bin-hadoop3.2/conf spark-3.1.3-bin-hadoop3.2/conf_bak
ln -s /etc/spark spark-3.1.3-bin-hadoop3.2/conf
chown -R spark:hadoop spark-3.1.3-bin-hadoop3.2
rm spark
ln -s spark-3.1.3-bin-hadoop3.2 spark
su spark
cd /opt/redoop/apps/spark/jars
rm -f guava-14.0.1.jar
ln -s /opt/redoop/apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar guava-27.0-jre.jar
ll guava-27.0-jre.jar
Ambari页面上修改spark的配置文件
spark2-hive-site-override
metastore.catalog.default:spark->hive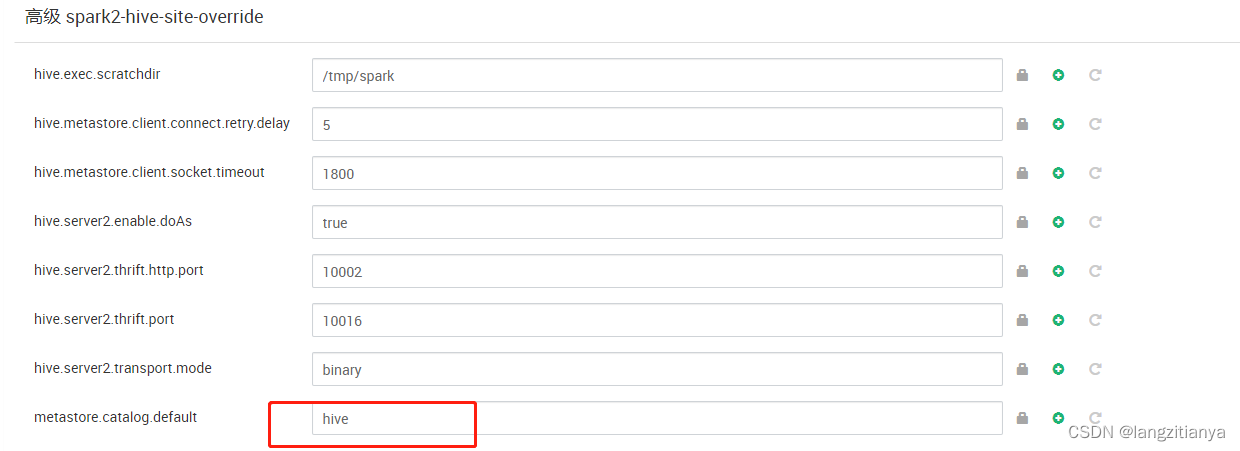
spark2-env content 追加
#spark3 needs
export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)
错误:java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path
原因:spark sql输出时使用了LZO压缩,没有找到对应的库
处理方法:安装LZO,重启HDFS
1. 安装lzop
sudo yum -y install lzop
2. 安装lzo
下载
cd /usr/local/src
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
编译
tar -zxvf lzo-2.10.tar.gz
cd lzo-2.10
export CFLAGS=-m64
./configure -enable-shared
make
sudo make install
编辑 lzo.conf 文件
sudo vi /etc/ld.so.conf.d/lzo.conf
在里面写入 /usr/local/lib
sudo /sbin/ldconfig -v
rm -rf lzo-2.10
3. 安装Hadoop-LZO
先下载 https://github.com/twitter/hadoop-lzo
编译
cd /usr/local/src/hadoop-lzo-master
export CFLAGS=-m64
export CXXFLAGS=-m64
export C_INCLUDE_PATH=/usr/local/include/lzo
export LIBRARY_PATH=/usr/local/lib
sudo yum install maven
mvn clean package -Dmaven.test.skip=true
复制文件
cp target/native/Linux-amd64-64/lib/* /opt/redoop/apps/hadoop/lib/native/
cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar /opt/redoop/apps/hadoop/share/hadoop/common/lib/
cp target/hadoop-lzo-0.4.21-SNAPSHOT-javadoc.jar /opt/redoop/apps/hadoop/share/hadoop/common/lib/
cp target/hadoop-lzo-0.4.21-SNAPSHOT-sources.jar /opt/redoop/apps/hadoop/share/hadoop/common/lib/
错误:WARN HdfsUtils: Unable to inherit permissions for file
处理方法:代码中设置hive参数 hive.warehouse.subdir.inherit.perms:false,关闭hive的文件权限继承来规避该问题
错误:java.lang.IllegalStateException: User did not initialize spark context
处理方法:打包前注释掉代码中的.master("local[*]")
错误:Class path contains multiple SLF4J bindings.
处理方法:把spark下的slf4j-log4j12包重命名,重启spark
mv /opt/redoop/apps/spark/jars/slf4j-log4j12-1.7.30.jar /opt/redoop/apps/spark/jars/slf4j-log4j12-1.7.30.jar_bak
Ambari页面上显示组件心跳丢失
集群节点中重启ambari-agent
service ambari-agent status
service ambari-agent restart














 2674
2674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









