






4种集合,分别为List、Queue、Set、Map
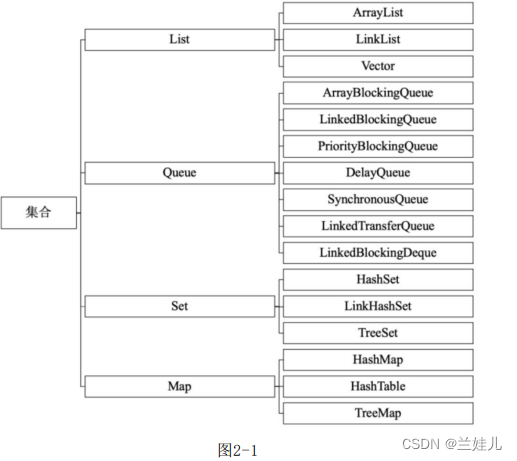
List:可重复
List是非常常用的数据类型,是有序的Collection,一共有三个实现类,分别是ArrayList、Vector和LinkedList。
1.ArrayList:基于数组实现,增删慢,查询快,线程不安全
ArrayList是使用最广泛的List实现类,其内部数据结构基于数组实现,提供了对List的增加(add)、删除(remove)、和访问(get)的功能。
ArrayList的缺点是对元素必须连续存储,当需要在ArrayList的中间位置插入或者删除元素时,需要将待插入或者删除的节点后的所有元素进行移动,其修改代价较高,因此,ArrayList不适合随机插入和删除的操作,更适合随机查找和遍历的操作。
ArrayList不需要再定义时指定数组的长度,在数组长度不能满足存储要求时,ArrayList会创建一个新的更大的数组并将数组中已有的数据复制到新的数组中。
2.Vector:基于数组实现,增删慢,查询快,线程安全
Vector的数据结构和ArrayList一样,都是基于数组实现的,不同的是Vector支持线程同步,即同一时刻只允许一个线程对Vector进行写操作(新增、删除、修改),以保证多线程环境下数据的一致性,但需要频繁地对verctor实列进行加锁和释放锁的操作,因此,Vector的读写效率在整体上比ArrayList低。
3.LinkedList:基于双向链表实现,增删快,查询慢,线程不安全。
LinkedList采用双向链表结构存储元素,在对LinkedList进行插入和删除操作时,只需在对应的节点上插入或者删除元素,并将上一个节点元素的下一个节点的指针指向该节点即可,数据改动较小,因此随机插入和删除效率很高。但在对LinkedList进行随机访问时,需要从链表头部一直遍历到该节点。随机访问速度慢。
Queue时队列结构。
Set:不可重复
特点:独一无二,适用存储无序且值不相等的元素。
java依据对象的内存地址计算出对象的hashcode值。如果想要比较两个对象是否相等,则必须同时覆盖对象的hashcode方法和equals方法,并且hashcode方法和equals方法的返回值必须相同。
####HashSet集合
java中的HashSet是一个基于哈希表实现的集合类,它是java集合框架的一部分。
- 无序性
HashSet中的元素没有特定的顺序,插入顺序不一定是迭代顺序。 - 唯一性
HashSet不允许包含重复的元素。如果添加重复元素,则会添加失败。 - 快速访问
由于底层使用哈希表,hashset提供了非常快速的基本操作,比如添加、删除、查找元素,时间复杂度通常为o(1).
-(非同步)线程不安全
TreeSet:二叉树实现
TreeSet基于二叉树的原理对新添加的对象按照指定顺序排序(升序、降序),每添加一个对象都会进行排序,并将对象插入二叉树的指定位置。
LinkHashSet:HashTable实现数据存储,双向链表记录顺序
LinkHashSet在底层使用LinkedHashMap存储元素
Map
1.HashMap:数组+链表存储数据,线程不安全
HashMap的数据结构如图2-2所示,其内部是一个数组,数组中的每个元素都是一个单向链表,链表中的每个元素都是嵌套Entry的实列,Entry实列包含四个属性:key、value、hash值用于指向单向链表下一个元素的Next。
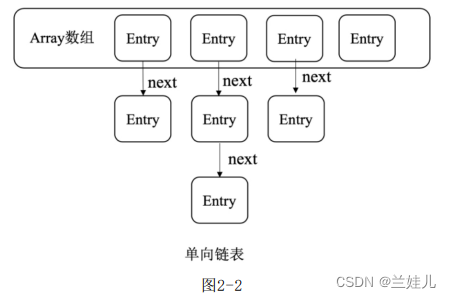
HashMap常用的参数:
-capacity: 当前数组的容量,默认为16,可以扩容,扩容后数组的大小为当前的两倍。因此该值始终为2^n。
- loadFactor: 负载因子,默认为0.75.
- threshold:扩容的阈值,其值等于capacityXloadFactor
HashMap在查找数据时,根据HashMap的Hash值可以快速定位到数组的具体下标,但是在找到数组下标后需要对链表进行顺序遍历直到找到需要的数据,时间复杂度为o(n).
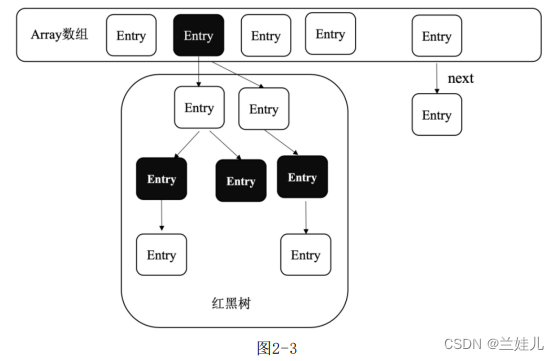
为了减少链表遍历的开销,java 8对HashMap进行了优化,将数据结构修改为数组+链表或红黑树。在链表中的元素超过8个以后,HashMap会将链表结构转换为红黑树结构以提高查询效率,因此其时间复杂度为O(logN)。java 8 HashMap的数据结构如图2-3所示。















 2696
2696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









