







*二分搜索被定义为一种在排序数组中使用的搜索算法,通过重复将搜索间隔一分为二。二分查找的思想是利用数组已排序的信息,将时间复杂度降
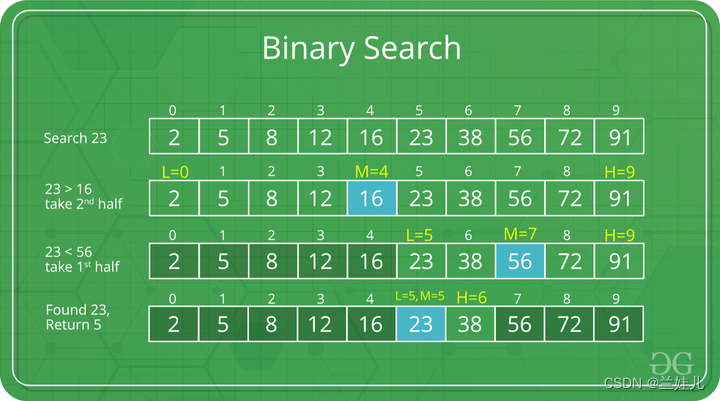
何时在数据结构中应用二分查找的条件:
-
数据结构必须是有序的。
-
访问数据结构的任何元素都需要恒定的时间.
二分查找算法 -
通过查找中间索引“mid”将搜索空间分为两半。
-
将搜索空间的中间元素与键进行比较。
-
如果在中间元素找到密钥,则过程终止。
-
如果在中间元素没有找到键,则选择哪一半将用 作下一个搜索空间。
如果键小于中间元素,则使用左侧进行下一步搜索。
如果键大于中间元素,则使用右侧进行下一步搜索。
这个过程一直持续到找到密钥或者总搜索空间耗尽为止。
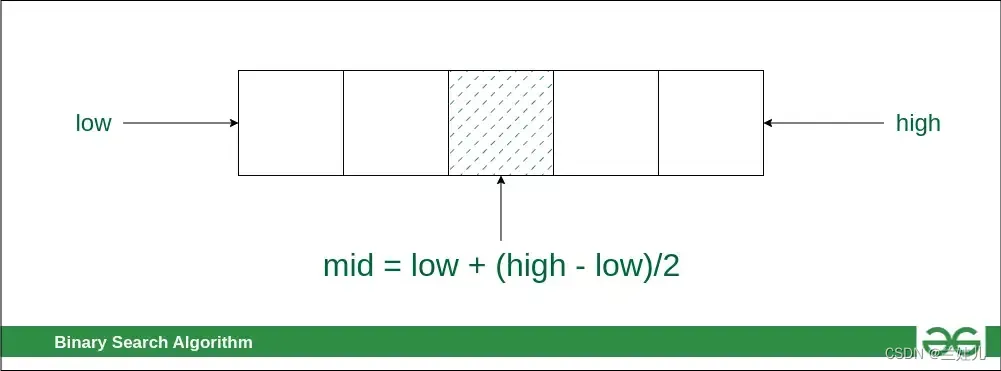
迭代二分算法
// C++ program to implement iterative Binary Search
#include <bits/stdc++.h>
using namespace std;
// An iterative binary search function.
int binarySearch(int arr[], int l, int r, int x)
{
while (l <= r) {
int m = l + (r - l) / 2;
// Check if x is present at mid
if (arr[m] == x)
return m;
// If x greater, ignore left half
if (arr[m] < x)
l = m + 1;
// If x is smaller, ignore right half
else
r = m - 1;
}
// If we reach here, then element was not present
return -1;
}
// Driver code
int main(void)
{
int arr[] = { 2, 3, 4, 10, 40 };
int x = 10;
int n = sizeof(arr) / sizeof(arr[0]);
int result = binarySearch(arr, 0, n - 1, x);
(result == -1)
? cout << "Element is not present in array"
: cout << "Element is present at index " << result;
return 0;
}
这段代码实现了迭代版本的二分查找算法(Iterative Binary Search)。
二分查找算法适用于已排序的数组。它通过不断将查找范围缩小一半来快速找到目标元素。在迭代版本的二分查找中,使用了一个 while 循环来反复进行查找。
以下是对代码的分析:
-
binarySearch函数:这是实现二分查找的主要函数。它接收一个已排序的整数数组arr、查找范围的左边界l、查找范围的右边界r、和目标元素x作为输入。在函数中,使用 while 循环来不断缩小查找范围。 -
while 循环:在每次循环中,通过计算中间元素的索引
m来找到查找范围的中间位置。然后,将目标元素x与中间元素arr[m]进行比较。 -
比较目标元素和中间元素:
- 如果目标元素
x等于中间元素arr[m],说明找到了目标元素,直接返回m作为目标元素的索引位置。 - 如果目标元素
x大于中间元素arr[m],说明目标元素在右半部分,将查找范围的左边界l更新为m + 1,继续查找右半部分。 - 如果目标元素
x小于中间元素arr[m],说明目标元素在左半部分,将查找范围的右边界r更新为m - 1,继续查找左半部分。
- 如果目标元素
-
循环结束条件:在每次循环中,如果
l大于r,说明查找范围已经缩小为空,目标元素不在数组中,返回 -1 表示未找到。 -
主函数
main:这里创建一个已排序的数组arr,定义目标元素x为 10,并调用binarySearch函数进行查找。最后输出查找结果。
此算法的时间复杂度为 O(log n),其中 n 是数组的长度。由于每次循环都将查找范围缩小一半,因此算法的查找速度非常快。二分查找算法在已排序的数组中进行查找时非常高效,特别适用于大规模数据的快速检索。
递归二分查找算法
// C++ program to implement recursive Binary Search
#include <bits/stdc++.h>
using namespace std;
// A recursive binary search function. It returns
// location of x in given array arr[l..r] is present,
// otherwise -1
int binarySearch(int arr[], int l, int r, int x)
{
if (r >= l) {
int mid = l + (r - l) / 2;
// If the element is present at the middle
// itself
if (arr[mid] == x)
return mid;
// If element is smaller than mid, then
// it can only be present in left subarray
if (arr[mid] > x)
return binarySearch(arr, l, mid - 1, x);
// Else the element can only be present
// in right subarray
return binarySearch(arr, mid + 1, r, x);
}
// We reach here when element is not
// present in array
return -1;
}
// Driver code
int main()
{
int arr[] = { 2, 3, 4, 10, 40 };
int x = 10;
int n = sizeof(arr) / sizeof(arr[0]);
int result = binarySearch(arr, 0, n - 1, x);
(result == -1)
? cout << "Element is not present in array"
: cout << "Element is present at index " << result;
return 0;
}
这段代码实现了递归版本的二分查找算法(Recursive Binary Search)。
递归版本的二分查找与迭代版本的实现逻辑是一样的,只不过是通过递归的方式来进行查找。递归版本的二分查找会将查找过程分解为多个子问题,然后递归地解决这些子问题,直到找到目标元素或查找范围为空。
以下是对代码的分析:
-
binarySearch函数:这是实现递归二分查找的主要函数。它接收一个已排序的整数数组arr、查找范围的左边界l、查找范围的右边界r、和目标元素x作为输入。 -
终止条件:在每次递归调用中,首先检查
r是否大于等于l,如果不满足,说明查找范围为空,返回 -1 表示未找到。 -
中间元素和目标元素的比较:在每次递归调用中,计算中间元素的索引
mid,然后将目标元素x与中间元素arr[mid]进行比较。 -
递归调用:如果目标元素
x等于中间元素arr[mid],说明找到了目标元素,直接返回mid作为目标元素的索引位置。否则,如果目标元素x小于中间元素arr[mid],说明目标元素在左半部分,递归地调用binarySearch在左半部分继续查找。如果目标元素x大于中间元素arr[mid],说明目标元素在右半部分,递归地调用binarySearch在右半部分继续查找。 -
主函数
main:这里创建一个已排序的数组arr,定义目标元素x为 10,并调用binarySearch函数进行查找。最后输出查找结果。
此算法的时间复杂度与迭代版本的二分查找一样,为 O(log n),其中 n 是数组的长度。递归版本的二分查找可以实现相同的功能,但可能需要更多的栈空间,因为每次递归调用都会在栈上创建新的函数调用帧。如果数组较大,递归版本的二分查找可能会导致栈溢出。一般情况下,建议使用迭代版本的二分查找来避免栈溢出的问题。
二分查找是一种高效的查找算法,但它也有自己的优点和缺点。
优点:
-
时间复杂度低:二分查找的时间复杂度为 O(log n),其中 n 是数组的长度。由于每次查找都将查找范围缩小一半,因此它比顺序查找的时间复杂度 O(n) 要低得多。对于大规模的数据集,二分查找能够快速定位目标元素。
-
适用于有序数组:二分查找要求数组是有序的,但一旦数组有序,它就能够发挥高效的搜索能力。在已排序的数据结构中,二分查找是一种非常有效的查找方法。
-
算法简单:二分查找的实现相对简单,只需要几行代码就可以实现。
缺点:
-
仅适用于有序数组:二分查找要求数组是有序的,如果数组是无序的,需要先进行排序操作,这将增加时间复杂度。
-
需要额外的空间:虽然二分查找的本身不需要额外的空间,但如果使用递归版本的二分查找,会在栈上创建多个函数调用帧,可能导致栈溢出,因此需要考虑递归深度。
-
更新操作不方便:二分查找适用于静态数据集。如果数据集经常发生更新,例如插入、删除等操作,维持数组有序性将变得复杂,并且可能导致频繁的排序操作。
-
不适用于链表等非连续存储结构:二分查找要求随机访问,对于链表等非连续存储结构,随机访问时间复杂度较高,因此不适合使用二分查找。
综上所述,二分查找是一种高效的查找算法,特别适用于静态的、有序的连续存储结构。如果数据集频繁更新或不具备随机访问性质,可能需要考虑其他查找算法。















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









