







一:预备知识
1)条件概率:事件
A
发生的条件下,事件
2)全概率公式:设事件
B1,B2...Bn
为样本空间的一个划分,也就是事件
B1,B2...Bn
把样本空间不相交的给划分完全了。则事件
A
发生的概率是:
简单的理解:
A,B,C
把样本空间划分了,其中这些事件均有
D
发生的概率,求
3)贝叶斯公式:事件
A
在事件
按照上面全概率简单理解的思路:贝叶斯是求,
D
已经发生了,而
二:思想
1)输入空间:
X∈Rn
为
n
维向量空间的集合。输出空间为分类标记空间
训练集
也就是:
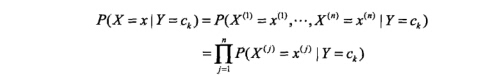
2)朴素贝叶斯法分类标记:对于待测试的输入
x
,计算其在不同的类别下发生的概率。也即是计算
也就是有如下公式:
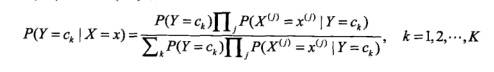
等式左边我们没法计算。朴素贝叶斯法就是计算等式右边的值。对于不同的类别 ck ,分子是 p(x) 的全概率公式,是一个常数。所以说,我们只计算分母的值就好了。
3)计算分母的值:其中, p(Y=ck) ,由训练数据的类别标签,可以直接计算。 p(xj|Y=ck)=p(xj,ck)p(Y=ck) ,利用条件概率进行计算。
三:算法

四:例题

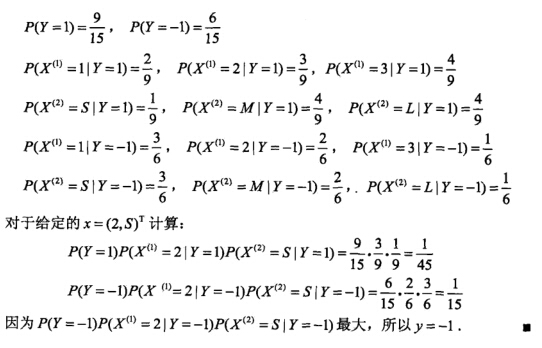
五:程序案例
维基百科的一个例子:
给出训练数据如下:
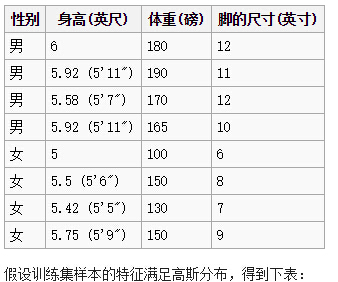
假设其每个特征{身高,体重,脚尺寸}都是满足高斯分布的。
判断一个身高6,体重130,脚尺寸8,是男是女。。。
function demoBeiyesi
Train=[ 1 6 180 12
1 5.92 190 11
1 5.58 170 12
1 5.92 165 10
0 5 100 6
0 5.5 150 8
0 5.42 130 7
0 5.75 150 9];
% 判断 x=[ 0/1 6 130 8];
%假设 男人 身高成正态分布 体重成正态分布 脚成正态分布
%假设 女人 身高成正态分布 体重成正态分布 脚成正态分布
% p(男|x)=p(x|男)*p(男)/P(x)=p(x1|男)*p(x2|男)*p(x3|男)*p(男)/P(x)
% 其中P(x)=sum(P(x|男)p(男)+p(x|女)*p(女))=常数
mUs=mean(Train(1:4,2));%男身高均值
mSigmals=std(Train(1:4,2));%男身高标准差
mUt=mean(Train(1:4,3)); %男体重均值
mSigmalt=std(Train(1:4,3));%男体重标准差
mUj=mean(Train(1:4,4));%男脚均值
mSigmalj=std(Train(1:4,4));%男脚标准差
fUs=mean(Train(5:8,2));
fSigmals=std(Train(5:8,2));
fUt=mean(Train(5:8,3));
fSigmalt=std(Train(5:8,3));
fUj=mean(Train(5:8,4));
fSigmalj=std(Train(5:8,4));
p1=cdftemp(6,mUs,mSigmals)*cdftemp(130,mUt,mSigmalt)*cdftemp(8,mUj,mSigmalj)*0.5
p2=cdftemp(6,fUs,fSigmals)*cdftemp(130,fUt,fSigmalt)*cdftemp(8,fUj,fSigmalj)*0.5
end
function value=cdftemp(temp,u,sigmal)
value=1/(sigmal*sqrt(2*pi))*exp(-(temp-u)^2/(2*sigmal^2));
end机器学习中代码:判断一个论坛是侮辱留言,还是非侮辱留言。
1:把训练集合的所有词条解析成一个不含重复字的字典,排成一行。
2:把训练集的所有文档,在上述字典下解析成{1,0}形式,1,表示这个 词条出现了,0表示没有出现。放到一个矩阵中,每行表示一个训练文档。
3:根据解析出来的矩阵,计算在不同类别下的每个词条出现的概率。其中,每个训练集中文档对应的类别是给出的。在概率计算中,利用了矩阵的有关知识。

第一行表示:创造的字典。由训练样本建立的不重复的字典。
第二行表示:训练文档1,在字典下的表示。第一个0,表示,文档1,不含词条A,第二个1,表示,文档1含有B。
第三行,表示训练文档3,在字典下的表示。标签是1 。因为文档2的标签也是1,所有
p1Denom=2;
2个文档标签是1 。
p1Num
为文档2 向量和文档3向量 相加。类别相同的所有词条个数放到一起,为了后续算概率。
# -*- coding: utf-8 -*-
##1:构造 训练样本 其特征是 w1 w2 ....wk 标签 c1 c2
##2: 计算 p(wi|c1) p(wi|c2)
from numpy import *
def loadDataSet (): #返回 切分后的文本 类别标签
postingList=[['my','Dog','has','flea','problem','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
classVec=[0,1,0,1,0,1]
return postingList,classVec
##创建vocabSet,包含所有文档的不重复的词,dataSet数据打乱返回字典
def createVocabList (dataSet):
vocabSet=set([])
for document in dataSet:
vocabSet=vocabSet | set(document)
return list(vocabSet)
##-----可以判断输入的词是不是在词汇表里-----------------------------
##vocabList字典(如果输入的词出现在字典里,则对应的值变成1)
def setOfWords2Vec(vocabList,inputSet):
returnVec=[0]*len(vocabList)
for word in inputSet : ## 对于inputSet出现的word
if word in vocabList:
##如果也出现在 vocabList上 则标记为1
#returnVec[vocabList.index(word)]=1
#词集模式 每个词只出现一次
returnVec[vocabList.index(word)]+=1 #词袋模式
else:print"the word:%s is not in my Vocabulay!" %word
return returnVec ##returnVec 文档向量
## 计算 p(wi|c1) p(wi|c2)
##不同的特征(词条)在相应类别(侮辱,不侮辱)下的概率
def trainNB0 (trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix) #文档数
numWords=len(trainMatrix[0]) #特征
pAbusive=sum(trainCategory)/float(numTrainDocs)
#p0Num=zeros(numWords);
#p1Num=zeros(numWords);
#p0Denom=0.0;
#p1Denom=0.0;
p0Num=ones(numWords);
p1Num=ones(numWords);
p0Denom=2.0;
p1Denom=2.0;
for i in range(numTrainDocs):
if trainCategory[i]==1:
p1Num+=trainMatrix[i]
p1Denom+=sum(trainMatrix[i])
else:
p0Num+=trainMatrix[i]
p0Denom+=sum(trainMatrix[i])
p1Vect=log(p1Num/p1Denom)
p0Vect=log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
##分类
def classifyNB (vec2Classify,p0Vec,p1Vec,pClass1):
p1=sum(vec2Classify*p1Vec)+log(pClass1)
p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
##函数封装起来,方便测试
def testingNB ():
listOPosts,listClasses=loadDataSet()
myVocabList=createVocabList(listOPosts)
trainMat=[]
for i in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,i))
p0V,p1V,pAb=trainNB0(array(trainMat),array(listClasses))
testEntry=['love','my','dalmation']
thisDoc=array(setOfWords2Vec(myVocabList,testEntry))
print testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry=['stupid','garbage']
thisDoc=array(setOfWords2Vec(myVocabList,testEntry))
print testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb)
参考文献:
统计学习方法,李航。
机器学习实战。














 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









