







需求
将以下表格内容由1:n,拆分为1:1:
原始:

处理后:

一 Mysql方法:
注:
部分信息参考博客:https://blog.csdn.net/johnricgtsd8br/article/details/97927842
先贴代码:
SELECT DISTINCT cid, SUBSTRING_INDEX(
SUBSTRING_INDEX( t1.content, ',',b.help_topic_id + 1),',',-1) as title
FROM t1
JOIN
mysql.help_topic as b
on b.help_topic_id < (char_length(t1.content) - char_length(replace(t1.content,',',''))+1)
解析:
SUBSTRING_INDEX(str,delim,count):根据delim定位来切分字符串,count可以是正(从左往右数),可以实负(从右往左数)
逗号个数=char_length(字符串)-char_length(replace(字符串,’,’,’’))
逗号位置=mysql.help_topic.id < 逗号个数[+1]
mysql.help_topic表的自增id是从0开始,所以在进行截取时要对id进行+1。见:
substring_index(t1.content,’,’,b.help_topic_id+1)
title列最后一个字符不是逗号时:逗号个数+1是为了截取时不漏掉最后一个逗号后的值,即:
char_length(t1.content) - char_length(replace(t1.content,’,’,’’))+1;
title 列最后一个字符是逗号时:逗号个数就不需要+1了,直接:
char_length(t1.content) - char_length(replace(t1.content,’,’,’’))
二 pandas 方法
df = pd.DataFrame({
'cid':[1,2,3,4,5],
'title':['汽车,火车,轮船','人才','数据,分析','测试数据',''],
},index=[1,2,3,4,5])
df_new = df.drop(columns='title')
df_new = df_new.join(df['title'].str.split(',',expand=True).stack().reset_index(level=1, drop=True).rename('title'))
df_new.reset_index(drop='True')
解析:
stack():从列到索引堆叠指定级别,实现多重索引
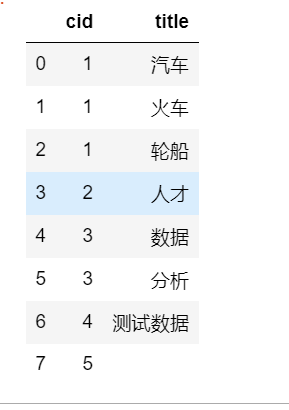
另外一个官网离例子,直接使用explode函数:
df. explode('title')















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









