






今天刷题的时候遇到了这样一道题~
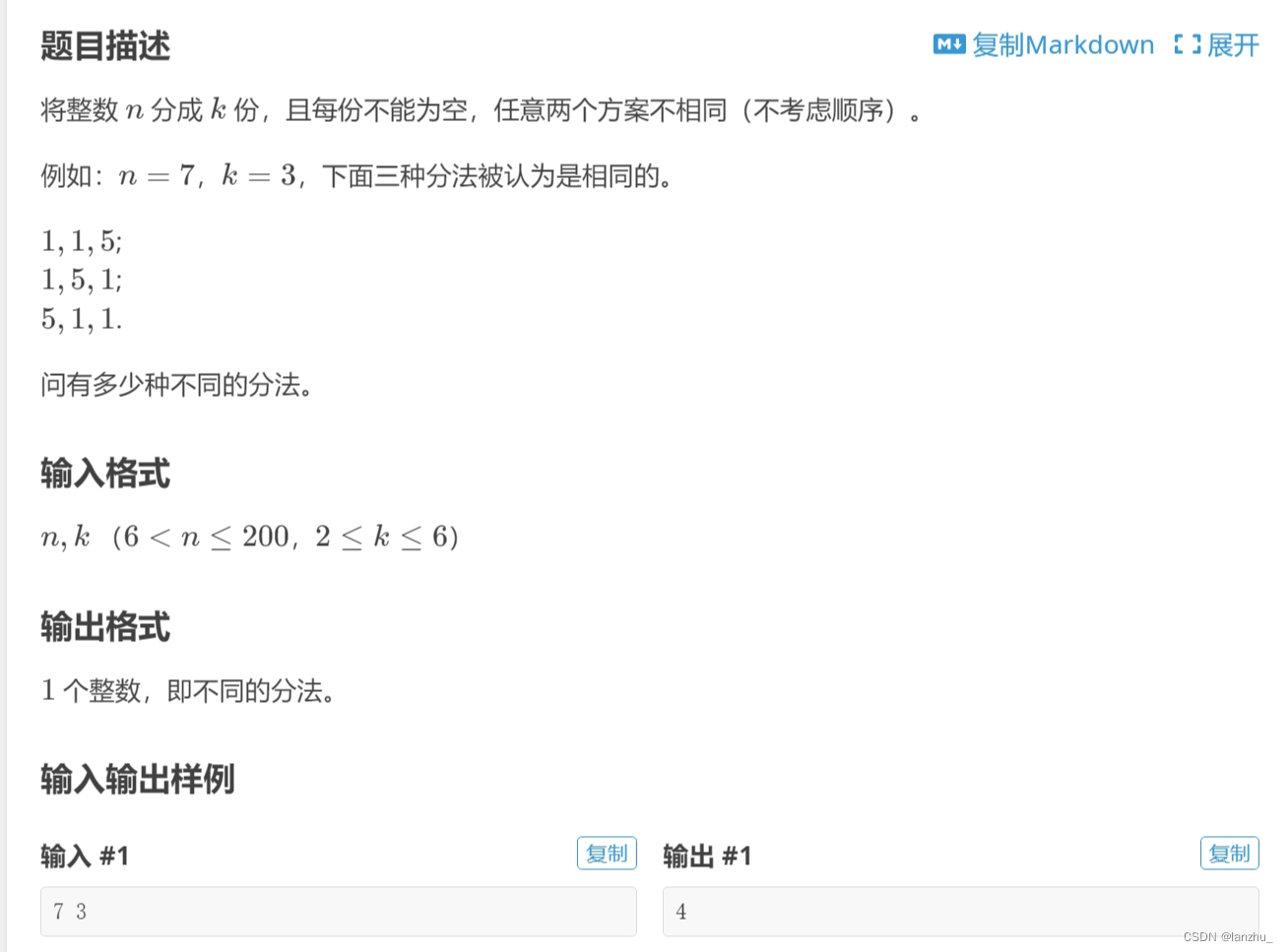
对于算法尚涉猎较浅的我自然被这题给难倒了,想构造一个dfs最后也不知道怎么使得方案不重复,于是打开了题解,看到了神犇的解答,当场自闭,不过痛定思痛,决定以博客形式来反思与归纳我想法上的不足。
首先我的思路上就出现了问题,我的想法是先分出k个1,之后对n-k进行一定的操作,即枚举所有不重复的排列,理论上这也是可行的思路,不过没有想到可以维护后面枚举的值一定不小于前面枚举的值来使得枚举方案不重复。并且本题还有一个关键的点,即只用深搜k-1次即可,因为第k项一定存在!(这里是可以优化的点!)
void dfs(int x,int s,int t)//x表示上一个出现的数,初始为1,让下个数从x开始循环,便可保证不重复
//s表示还需要多少次递归,初值为k,t表示到此还有多大的数可以分
{
if(s==1){//遍历k-1次就可以了,只要保证最后一个数存在
ans++;
return;
}
for(int i=x;i<=t/s;++i)//i*s<=t;保证后面有数可以取到
dfs(i,s-1,t-i);
}这里就是主要函数的代码了,对于for循环中的i<=t/s是为了保证i*s<=t,即最后一项一定存在!而对i从x开始枚举,则是确保枚举方案的数是不递减的!这样就可以保证唯一。
dfs(0,k,n-k);
dfs(1,k,n);至于dfs的使用既可以像我的思路那样将x初始设为0,t初始设为t,也可以直接对n进行拆分,x为1。我的做法就有点多此一举了。
以上就是对于本题的题解博客了!归纳一下新的知识点:在dfs中可以通过for(i=x)来维护某一种秩序。对i的范围限制可以顺便维护某一个东西的存在,或者进行剪枝操作。















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









