






基于深度学习的语音情感识别算法,在研究之前采集相关公共语音数据集,首先通过传统语音特征提取算法,提取多种声学特征信息,然后搭建深度学习神经网络,将多种声学特征送入到网络中进行情感分类判断(至少5类以上情感),训练完成后对结果进行验证。要求深度学习或语音特征提取算法上的改进,使语音情感识别和分类效果更好,识别时间更短,准确率、召回率和综合评价函数值更高。
用到的技术:卷积神经网络(CNN)、(GUI设计)pyqt
系统结构框图: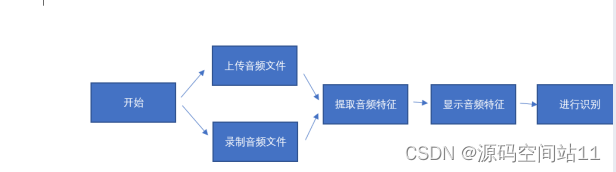
深度学习模型,搭建的卷积神经网络
input_shape = x_train[0].shape
model = Sequential()
model.add(Conv2D(8, (13, 13),input_shape=(input_shape[0], input_shape[1], 1)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(Conv2D(8, (13, 13)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 1)))
model.add(Conv2D(8, (13, 13)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(Conv2D(8, (2, 2)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 1)))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
模型训练配置
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=1)
history = model.fit(x_train,
y_train,
batch_size=64,
epochs=50,
validation_data=(x_test, y_test))
model.save('model_1.h5')
评价指标:
(1)Precision(精度)
被正确检索的样本数与被检索到样本总数之比。即:TP / (TP + FP);
(2)Recall(召回率)
被正确检索的样本数与被检索到的样本总数之比。即:TP / (TP + FN);
(3)F1 score(F1分数)
F1分数是将精度和召回率组合而成的新的单一指标,用来综合考虑精度和召回率,只有当精度和召回率都很高时,才能得到较高的F1分数。
模型文件
Test目录下model.h5文件
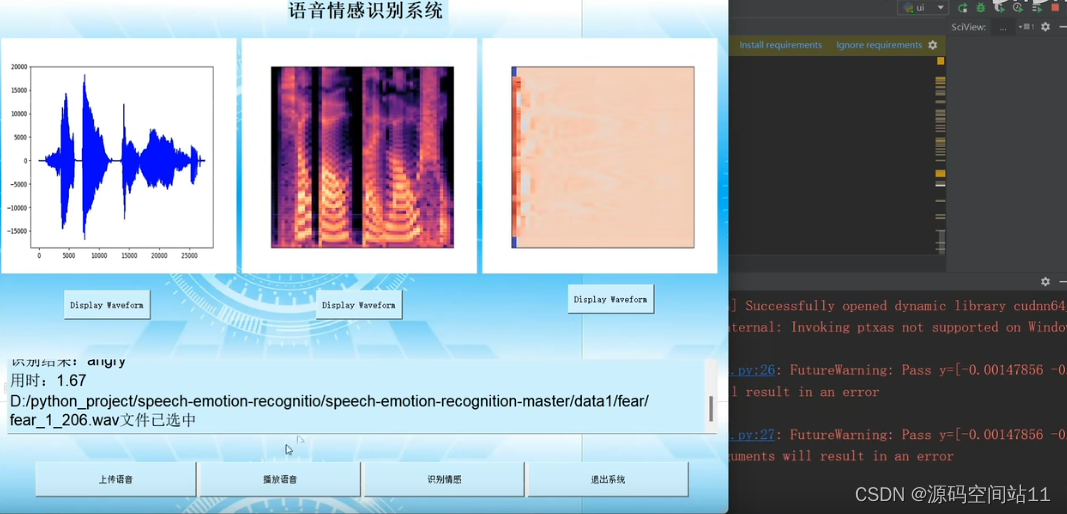
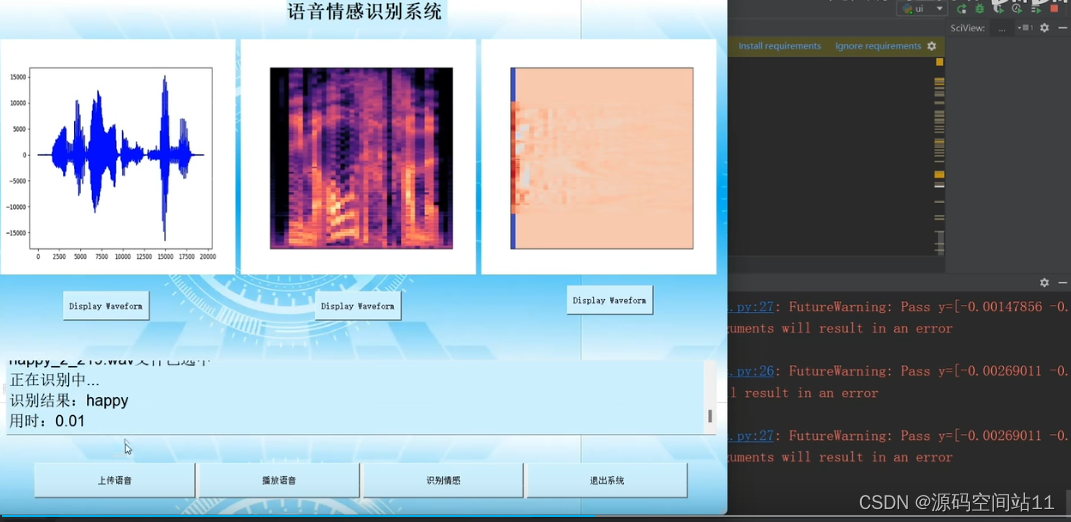
【人工智能毕设之基于深度学习+pyqt的语音情感识别系统】 https://www.bilibili.com/video/BV1HY4y1h71i/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
















 5247
5247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











