






1. 项目概述
本项目实现了一个基于协同过滤的小说推荐系统,采用了 用户-物品协同过滤 和 物品-物品协同过滤 两种推荐算法。系统通过分析用户与小说的互动数据(例如收藏、阅读和评论),计算用户之间或物品之间的相似度,最终为用户推荐个性化的小说。
2. 环境要求
- Python 版本:3.6
- 依赖库:
- Django 1.11.7:Web框架
- Pymysql:MySQL数据库连接
- Mysql:数据库管理系统
- pure_pagination:分页插件
- taggit:标签插件
- captcha:验证码插件
- xadmin:后台管理界面
3. 系统设计
该系统分为以下几个主要模块:
- 数据库管理模块:通过
connect_mysql.py实现与 MySQL 数据库的连接与操作。 - 推荐模块:
- 用户-物品协同过滤(User-Based Collaborative Filtering)通过计算用户之间的相似度,为用户推荐未读过的小说。
- 物品-物品协同过滤(Item-Based Collaborative Filtering)通过计算物品之间的相似度,为用户推荐与他们感兴趣的物品相似的其他物品。
- 数据处理模块:从数据库中提取用户的交互数据,如收藏、阅读和评论。
4. 主要模块与功能
4.1 数据库管理模块
该模块通过 connect_mysql.py 与 MySQL 数据库进行交互,提取用户与物品的互动数据。
- 数据库连接:使用
ConnectMysql类进行数据库连接,提供查询方法query()。 - 数据表:
Collections:存储用户的收藏信息。ReadNovel:存储用户的阅读历史。CommentModels:存储用户的评论数据。
4.2 协同过滤推荐模块
本系统实现了两种推荐算法:
- 物品-物品协同过滤(Item-Based Collaborative Filtering):
- 该算法通过计算物品(小说)之间的相似度,为用户推荐未阅读的、与其已读小说相似的小说。
- 相似度计算:使用 共现矩阵 和 余弦相似度 进行物品相似度计算。
- 该算法的主要步骤包括:
- 从数据库中提取用户的互动数据(如收藏、阅读和评论)。
- 计算物品之间的相似度矩阵。
- 为用户推荐与其已读物品相似的未读物品。
- 用户-物品协同过滤(User-Based Collaborative Filtering):
- 该算法通过计算用户之间的相似度,为目标用户推荐未读过的、其他相似用户喜欢的小说。
- 相似度计算:使用 皮尔逊相关系数 来衡量用户之间的相似度。
- 该算法的主要步骤包括:
- 为每个用户构建 用户-物品评分矩阵。
- 计算用户之间的皮尔逊相关系数。
- 根据最相似的用户的历史行为来为目标用户生成推荐。
4.3 推荐系统
推荐系统通过计算 用户之间的相似度 或 物品之间的相似度,基于用户的历史行为生成推荐结果。对于每个用户:
- 用户推荐:基于与目标用户相似的其他用户的历史行为生成推荐。
- 物品推荐:基于目标用户与物品的互动历史,推荐与用户感兴趣的物品相似的其他物品。
推荐算法的核心是:
- 皮尔逊相关系数:用于衡量两个用户或物品之间的相似度,公式如下:
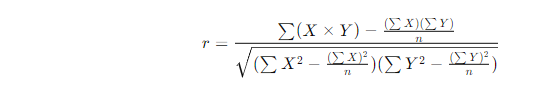
- 协同过滤算法:通过计算相似度矩阵,推荐与用户行为相似的物品或用户。
5. 主要代码解析
5.1 itemBasedCF.py 文件
该文件实现了物品-物品协同过滤算法:
readData()方法:从数据库中提取用户与物品的交互数据(收藏、阅读、评论),并构建 用户-物品评分矩阵。ItemSimilarity()方法:构建 物品-物品相似度矩阵,基于用户的交互数据计算物品之间的相似度。Recommend()方法:为目标用户生成推荐,基于物品相似度和用户历史行为。
5.2 userBasedCF.py 文件
该文件实现了用户-物品协同过滤算法:
pearson()方法:计算两位用户之间的皮尔逊相关系数,衡量他们的相似度。neighbors()方法:查找与目标用户最相似的K个用户。recommend_to_user()方法:基于目标用户的相似邻居,为用户推荐未互动过的物品。
6. 使用说明
- 安装依赖:
- 使用
requirements.txt安装项目依赖。
pip install -r requirements.txt
- 数据库配置:
- 修改
settings.py文件中的数据库连接信息,确保正确配置数据库。
- 运行项目:
- 执行以下命令启动 Django 项目:
python manage.py runserver
- 推荐使用:
- 通过系统界面,用户可以查看为其推荐的小说列表。
7. 总结
本系统通过 协同过滤算法 实现了个性化的小说推荐,主要使用 物品-物品协同过滤 和 用户-物品协同过滤 两种方法来计算用户或物品之间的相似度,并生成个性化的推荐结果。系统结构清晰,模块化设计,便于扩展和维护。
具体代码分析:
userBasedCF.py 概述:
- 导入库:
- 导入了
pdb(用于调试)、csv(用于文件处理)和sqrt(用于数学计算)等库。 - 数据库查询:
- 从
Collections、ReadNovel和CommentModels表中查询数据,主要用于获取用户与小说的交互数据。 - 用户-物品矩阵构建:
- 与
itemBasedCF.py类似,这部分代码创建了一个user_item字典,记录每个用户与其互动的物品(小说)及相应评分。
接下来,代码会继续计算用户之间的相似度,并基于这些相似度生成推荐。
在 userBasedCF.py 的这部分代码中,用户与物品(小说)之间的互动矩阵(user_item 字典)继续被构建:
- 收藏、阅读和评论数据:
- 收藏:为用户收藏的每本小说赋值 5。
- 阅读:为用户阅读的每本小说赋值 3。
- 评论:每本评论的小说赋值 1,可能多个评论会累积增加该评分。
通过这些步骤,代码正在逐步构建一个用户-物品的评分矩阵。
接下来,会开始计算用户之间的相似度,基于这些相似度来为用户推荐内容。
这部分代码继续处理 用户-物品评分矩阵,并开始实现 基于用户的协同过滤推荐系统。
代码分析:
- 用户评分构建:
- 对于用户的每一项收藏、阅读和评论,累加评分,最终为每个用户和他们交互的物品(小说)创建一个评分字典
user_item。 - 推荐类:
recommender类被定义来进行推荐。它的初始化方法接受两个参数:k:用于指定计算 K个最相似邻居 的数量。cnt:控制推荐的数量。
接下来,会根据用户之间的相似度来计算 K近邻,并为用户生成个性化推荐。
在这部分代码中,推荐系统实现了 皮尔逊相关系数(Pearson Correlation Coefficient),这是基于用户相似度计算的关键部分。
代码分析:
- Pearson相关系数:
pearson()方法计算两位用户之间的相似度,具体通过他们对共同物品的评分来评估。- 计算公式为:
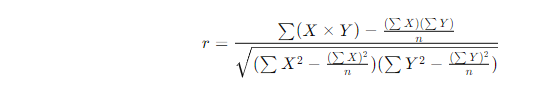
- 该方法通过对用户共同评分的物品进行遍历,计算出 X 和 Y(两个用户的评分)之间的相关性。
- 参数:
touser: 目标用户的评分数据。dataset: 完整的用户-物品评分数据。
通过这个方法,系统能够评估不同用户之间的相似性,进而为用户提供推荐。
接下来,看看如何根据相似度为用户生成具体的推荐。
这部分代码继续完成 用户相似度计算 和 邻居查找:
代码分析:
- 计算皮尔逊相关系数:
- 继续通过计算皮尔逊相关系数,来衡量两个用户的相似性。如果分母为零(即两位用户的评分变动非常小),返回 0,表示相似度为零。
- 邻居查找:
neighbors()方法用于查找与目标用户(username)最相似的用户。- 对于每个用户,计算目标用户与其他用户之间的 皮尔逊相关系数,并将计算结果存储在
distances列表中。 - 目标是找到与目标用户最相似的 K个用户,然后根据这些相似用户的评分推荐未互动过的物品。
接下来,看看如何生成推荐。
在这部分代码中,系统继续实现 基于用户的推荐 逻辑:
代码分析:
- 邻居排序:
neighbors()方法返回的 相似度(皮尔逊相关系数)被用于对所有用户进行排序,选择最相似的用户作为 邻居。distances.sort()按照相似度(距离)降序排列,从而确保最相似的用户排在前面。- 推荐生成:
recommend_to_user()方法根据目标用户的 邻居 来生成个性化推荐。recommendations字典用于存储推荐的小说(物品)和对应的权重(即推荐的强度)。- 系统根据目标用户的邻居和其相似度来计算推荐。较相似的邻居对推荐的贡献较大。
接下来,进一步理解推荐逻辑的实现。
在这部分代码中,推荐系统继续完成 基于用户的推荐生成:
代码分析:
- 邻居的权重计算:
- 每个邻居的贡献权重是根据其与目标用户的相似度计算的,权重越高,相似度越高的邻居对推荐的影响越大。
- 生成推荐:
- 系统遍历每个邻居的评分(
neighbor_books),为目标用户推荐其未读过的书籍(小说)。 - 对于每本书籍,计算它的推荐分数,并根据邻居的相似度加权。
- 只有目标用户未评分的书籍才会被推荐。
这部分代码完成了 推荐生成 的过程,基于用户相似度计算并给出推荐结果。
总结:
- 数据准备: 从数据库中获取用户与物品(小说)的互动数据。
- 用户-物品矩阵构建: 为每个用户构建与物品的评分矩阵。
- 相似度计算:
- 对于 物品推荐,计算物品之间的相似度。
- 对于 用户推荐,计算用户之间的相似度,使用皮尔逊相关系数。
- 推荐生成: 基于用户的邻居和相似度,为用户生成推荐的物品。
【基于Python协同过滤的小说推荐系统】 https://www.bilibili.com/video/BV1YK4y1d7qg/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











