









0、引言
在关系型数据库如Mysql中,设计库表需要注意的是:
1)需要几个表;
2)每个表有哪些字段;
3)表的主键及外键的设定——便于有效关联。
表的设计遵守范式约束,考虑表的可扩展性,避免开发后期对表做大的改动。
Mysql或者Oracle中,修改数据类型相对比较简单,通过命令行或者navicat、sqldeveloper等可视化工具直接修改。
即便千万级别数据量,多等点时间,也能修改好。
而在Elasticsearch非关系型数据存储的搜索引擎中,设计表对应的就是Mapping的设计。
且ES中一旦字段设定后,不能修改。
当然,这也不是绝对的,可以通过新建索引,然后reindex将原有数据迁移到新索引。
即便如此,还是建议:索引设计的前期,根据项目的需要设计好字段。如考虑如下的因素?
1)字段的大小,考虑最大、最小的情况,如某一个字段超过1MB甚至更多;
2)字段需不需要分词、全文检索、其他类型的检索;
3)时间字段类型的设置,时间戳、UTC类型或者字符串类型;
4) 字段需不需要聚合
…….
这就引申出本文的内容,Elasticearch到底支持哪些数据类型?Elasticsearch如何进行数据选型?
有没有直接拿来就用的Mapping万能模板。
以上问题,本文一一透彻解答。
1、Elasticsearch数据类型有哪些?
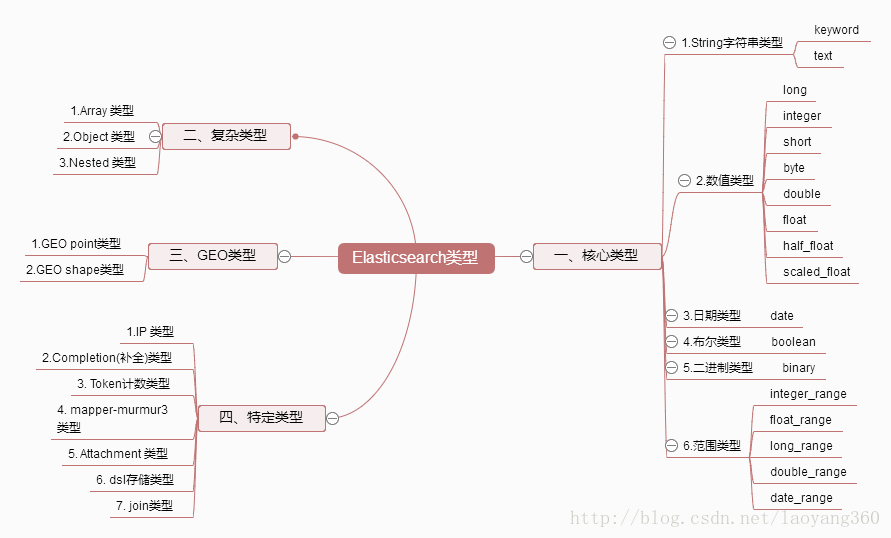
2、Elasticsearch数据如何选型?
2.1 字符串类型选型
text类型作用:分词,将大段的文字根据分词器切分成独立的词或者词组,以便全文检索。
适用:email内容、某产品的描述等需要分词全文检索的字段;
不适用:排序或聚合(Significant Terms 聚合例外)
keyword类型:无需分词、整段完整精确匹配。
适用于:email地址、住址、状态码、分类tags。
2.2 数值类型选型
long长整型:一个带符号的64位整数,最小值为 -263 ,最大值为 263 -1。
integer 整数:一个带符号的32位整数,最小值为 -231 ,最大值为 231 -1。
short 短整形:一个带符号的16位整数,最小值为-32,768,最大值为32,767。
byte 字节型:一个带符号的8位整数,最小值为-128,最大值为127。
double 双精度浮点型:双精度64位IEEE 754浮点数。
float 单精度浮点型:单精度32位IEEE 754浮点数。
half_float半精度浮点型:半精度16位IEEE 754浮点数。
scaled_float:由长度固定的缩放因子支持的浮点数。
以上,根据长度选型即可。
2.3 日期类型选型
{ “date”: “2015-01-01” }
{ “date”: “2015-01-01T12:10:30Z” }
{ “date”: 1420070400001 }
如上,日期类型或者时间戳类型。
参考模板:
“date”: {
“type”: “date”,
“format”: “yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”
}
2.4 布尔类型选型
布尔字段接受JSON true和false值,但也可以接受被解释为true或false的字符串和数字:
false值举例:
false,“false”,“off”,“no”,“0”,“”(空字符串),0,0.0
true值举例:
以上false示例的反面,一切非假值。
2.5 二进制类型选型
二进制类型接受二进制值作为Base64编码字符串。 该字段默认情况下不存储,不可搜索:
如: “blob”: “U29tZSBiaW5hcnkgYmxvYg==”
2.6 范围类型选型
integer_range :整型范围类型;
float_range :单精度浮点范围类型;
long_range :长整型范围类型;
double_range :双精度范围类型;
date_range :时间范围类型;
ip_range :IP范围类型。
以上,根据类型&范围需要选型即可。
2.7 数组类型选型
2.7.1 Array数组类型选型
在Elasticsearch中,没有专门的数组类型。
默认情况下,任何字段都可以包含零个或多个值,但是数组中的所有值必须是相同的数据类型。 例如:
字符串数组: [ “one”, “two”
整数数组:[1,2]
阵列数组:[1,[2,3]],相当于[1,2,3]
一系列对象数组:[{“name”:“Mary”,“age”:12},{“name”:“John”,“age”:10}]
可以理解为单类型扩展多个值的类型。
如果需要根据数组值进行查询操作,官网建议使用nested嵌套类型。
数组类型:没有明显的字段类型设置,任何一个字段的值,都可以被添加0个到多个,当类型一直含有多个值存储到ES中会自动转化成数组类型
对于数组类型的数据,是一个数组元素做一个数据单元,如果是分词的话也只是会依一个数组元素作为词源进行分词,不会是所有的数组元素整合到一起。
在查询的时候如果数组里面的元素有一个能够命中那么将视为命中,被召回。
2.7.2 Object对象类型
JSON文档本质上是分层的: 存储类似json具有层级的数据,文档可能包含内部对象,而内部对象又可能包含其他内部对象。
PUT my_index/my_type/1
{
"region": "US",
"manager": {
"age": 30,
"name": {
"first": "John",
"last": "Smith"
}
}
}这和Json类型的初衷是一致的。
访问方式举例: “manager.name.last”: “Smith”。
2.7.3 nested嵌套类型
nested 嵌套类型是Object数据类型的特定版本,允许对象数组彼此独立地进行索引和查询。
一个例子,自然就明白了:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"user": {
"type": "nested"
}
}
}
}
}
PUT my_index/my_type/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
GET my_index/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
}
}能完成嵌套查询&检索,对于非一对一关系的字段适用。
在ElasticSearch内部,嵌套的文档(Nested Documents)被索引为很多独立的隐藏文档(separate documents),这些隐藏文档只能通过嵌套查询(Nested Query)访问。每一个嵌套的文档都是嵌套字段(文档数组)的一个元素。
嵌套文档的内部字段之间的关联被ElasticSearch引擎保留,而嵌套文档之间是相互独立的。
默认情况下,每个索引最多创建50个嵌套文档,可以通过索引设置选项:index.mapping.nested_fields.limit 修改默认的限制。
2.8 IP类型
存储IPV4或IPV6地址。
如: “ip_addr”: “192.168.1.1”
2.9 completion suggester类型
suggester类型对应 suggester检索,完成自动补全。
2.10 令牌计数类型
类型为token_count的字段实际上是一个接受字符串值的整数字段,对它们进行分析,然后对字符串中的令牌数进行索引。
……..
3、Elasticsearch万能Mapping模板。
以下模板,已验证好用。
PUT testinfo_index
{
"mappings": {
"testinfo_type": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "keyword"
},
"content": {
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
},
"available": {
"type": "boolean"
},
"review": {
"type": "nested",
"properties": {
"nickname": {
"type": "text"
},
"text": {
"type": "text"
},
"stars": {
"type": "integer"
}
}
},
"publish_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"expected_attendees": {
"type": "integer_range"
},
"ip_addr": {
"type": "ip"
},
"suggest": {
"type": "completion"
}
}
}
}
}
}
}4、小结
看到这里,有人可能不服气的说,哎,又是官网都有的资料!
突然想起另一个问题,高考的时候的每一个得分点,课本上不都有吗?那为什么我们没有达到700分以上呢?
既然课本上都有,为什么还要那么多《黄冈XX冲刺》、《黄冈XX密卷》以及N多复习资料呢?
或许正如大神刘未鹏所说,“ 重要的事情要营造比较大的时间块来完成。比如读一本好书,或者掌握一个重要的知识点,最好不要切得太琐碎了看,否则看了后面忘了前面,不利于知识的组织和联系。 ”
以上,是说给我自己的,也与大家共勉!
参考:https://www.elastic.co/guide/en/elasticsearch/reference/5.6/mapping-types.html
——————————————————————————————————
更多ES相关实战干货经验分享,请扫描下方【铭毅天下】微信公众号二维码关注。
(每周至少更新一篇!)

和你一起,死磕Elasticsearch!
——————————————————————————————————
2017年10月30日 20:25 于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/78396928
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!
















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











