









你或许误以为下面的表格是excel格式的,但实际上,它是Access数据库,这是微软开发的一款曾在全球广受欢迎的数据库软件。
Microsoft Access自1992年问世至今已历经32载,你是否以为它早已被淘汰?事实恰恰相反,这款软件在竞争激烈的市场中依然稳占一隅,被誉为“不死之身”。

Access,僵尸一般的存在
尽管Access已显露出衰老之态,但它却像僵尸一般在数据库市场中顽强生存,这无疑违背了软件界的常规逻辑。
这种情况让微软感到困扰,因为它一直有意淘汰这个自己亲手打造的数据库产品。
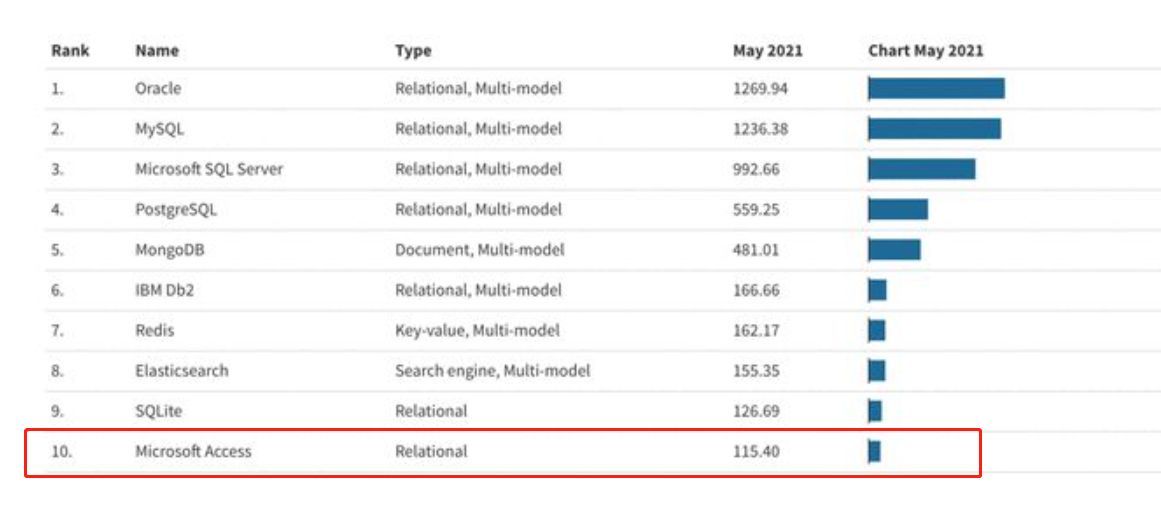
在2021年全球最受欢迎的十大数据库排名中,Oracle、MySql和SQL Server毫无悬念地占据了前三甲,但令人惊讶的是,Microsoft Access也跻身榜单,位列第十。
据某些研究机构调查显示,目前有超过10万家公司仍在使用Access,尽管这个数量不算庞大,但这些用户的忠诚度却极高,其中许多企业已经持续使用了20多年。

微软曾多次试图关闭Access数据库,但遭到了用户社区的强烈反对,尽管微软实力强大,采取了各种措施,但仍未能动摇Access在数据库市场的地位。
那么,究竟是哪款国内软件有如此实力,能够“助”微软一臂之力,甚至有潜力取代Access呢?
Access,让微软又爱又恨
“即使是Excel的高手,其能力也不及Access的初学者。”这句话在IT界广为传播。
确实,与其他复杂的数据库相比,Access在数据处理方面拥有许多优势,如用户友好的界面、易于操作、便捷的存取功能以及无需专用服务器等。
这些特点使其完全满足个人用户的需求,也因此当初受到了微软的青睐。

然而,当Access被应用于企业运营场景时,其局限性便显露无遗,网友们也纷纷指出了以下几个问题,这些问题同样是微软对Access感到不满的原因:
其一,Access的数据处理能力有限,随着并发用户的增多,数据处理需求也随之增加,这使得作为小型数据库的Access在运行性能上显得力不从心,甚至出现卡顿现象。
其二,Access缺乏完善的安全模型,当它被用作软件、网站等后台数据库时,几乎任何用户都能轻松访问,这无疑降低了其安全性。

其三,联网功能不足,Access主要在局域网环境中应用,对于非专业人员来说,实现联机功能相当困难。
其四,功能定位尴尬,对于一般用户,使用Access进行日常办公管理需要掌握VBA编程知识,这显然过于复杂;而对于专业开发者来说,Access的扩展性又显得不足,显得有些简陋。
Access用户迎来新选择
许多用户对Access的喜爱,源于其能够通过简单的代码赋予他们软件开发的能力,但现在,有一款国产软件实现了完全的“0”代码搭建方式,吸引了大量Access用户的转投。
这款名为“云表平台”的软件,以其纯中文的操作界面和无需编程的特点,让用户能够以拖拉拽的简单方式实现管理流程,即使是0编程基础的小白也能轻松上手。
企业员工能够迅速完成复杂的数据处理任务,该平台支持高并发用户,即使处理大量数据也毫无压力,操作流畅无卡顿。
更重要的是,云表平台不仅支持PC端,还兼容移动端,并能实现数据“上云”,这样企业员工就可以随时随地管理企业流程。
以其类似Excel的操作方式,让用户仅需简单绘制表格,即可轻松应对物资、财务、行政、项目管理等多样化日常数据需求,而且,它支持搭建诸如MES、WMS、SRM、ERP等复杂的工业级应用,满足企业高级管理的需求。
这款国产软件,秉持着“人人都是开发者”的初心,向大众提供了免费使用版,至今,它已在国内惠及超过30万家企业,其中不乏一些行业领军者,如华为、中冶、贝因美、燕京大学以及中国中铁等。
小结
被誉为“不死”的Access,如今迎来了真正的挑战者。国内研发的无代码开发技术,正在迅速迎头赶上,甚至在某些方面已经超越了微软。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









