







作者:Han Zhu, Mingsheng Long, Jianmin Wang and Yue Cao
论文地址:https://pdfs.semanticscholar.org/eb0c/64244dcf238a2cbf479ab2fdc9047fc80bc5.pdf
What:
1.特征没有和量化一起优化,所以特征不一定兼容后续的量化操作。
量化损失也没有统计上的最小。
2.提出了Deep Hashing Network (DHN) 由四个成分组成:
a. CNN来提取图像特征
b. 一个全链接层来产生binary的哈希编码
c. pair-wise 的 cross-entropy loss 来保证相似度
d. quantization loss 来控制哈希质量
3.测试数据集为NUS-WIDE (195,834 21类 256*256),
CIFAR-10 (60,000 10类 32*32),
Flickr (25,000 38类 256*256)
How:
1. 加了一个fch层来做量化, 实质是 先用了 tanh 做一个粗的量化。
2. 然后给了一个量化 loss(公式6) 主要是取绝对值以后 要和1接近。因为量化目标本来就是得到一个 h属于{-1,1}的。
3. 由于公式6 non-smooth 所以将 1范数 改成了 log cosh(x)
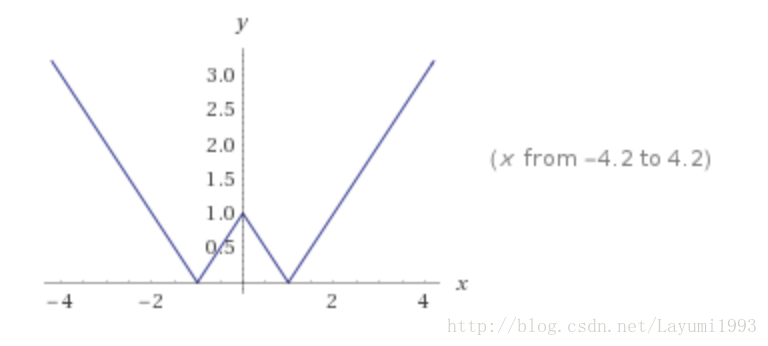
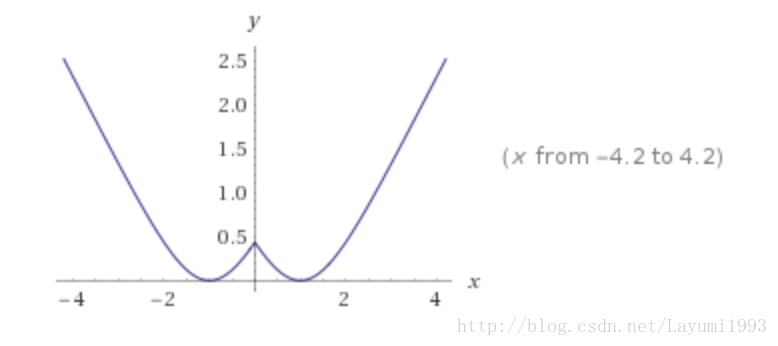
4. cross-entropy loss 而不是 contrast loss
5. Table2可以看出两点: CIFAR10还是不稳定,3%其实差不多。square loss确实可能不好,需要调。
6. DHN-Q是没有量化loss,但是最后也加了量化sgn。所以效果差了。 一般来说直接来学,用float 是不会差的。应该好于DHN-B .















 4462
4462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











