






今天分享的是一套基于SSM技术+spark技术的电影推荐系统
包含了爬虫、电影网站(前端和后端)、后台管理系统以及推荐系统(Spark)。
基于 Spark 的电影推荐系统
本次项目是基于大数据过滤引擎的电影推荐系统–“懂你”电影网站,包含了爬虫、电影网站(前端和后端)、后台管理系统以及推荐系统(Spark)。

一、爬虫
开发环境: pycharm + python3.6
软件架构: MySQL + scrapy
运行环境: 本次爬取的内容在外网,所以需先翻墙后才能成功运行。
项目架构:

二、电影网站
开发环境: IntelliJ IDEA + maven + Git + Linux + powerdesigner
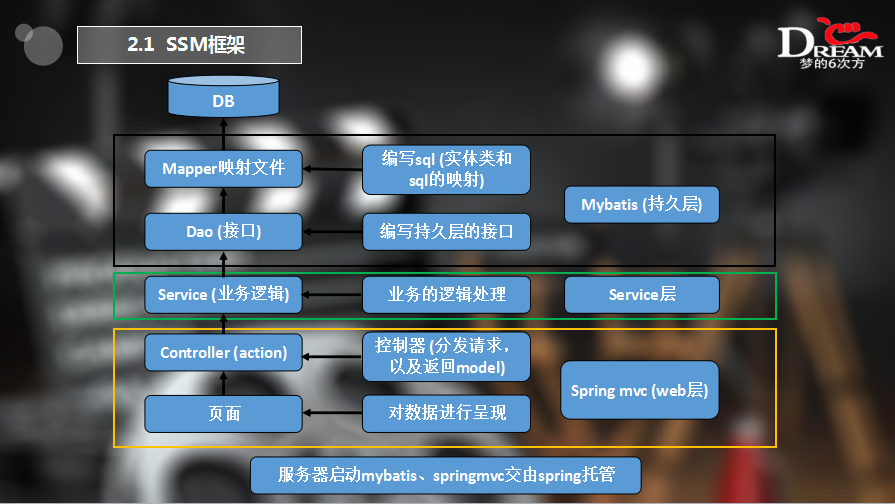
软件架构: MySQL + MyBatis + Spring + SpringMVC
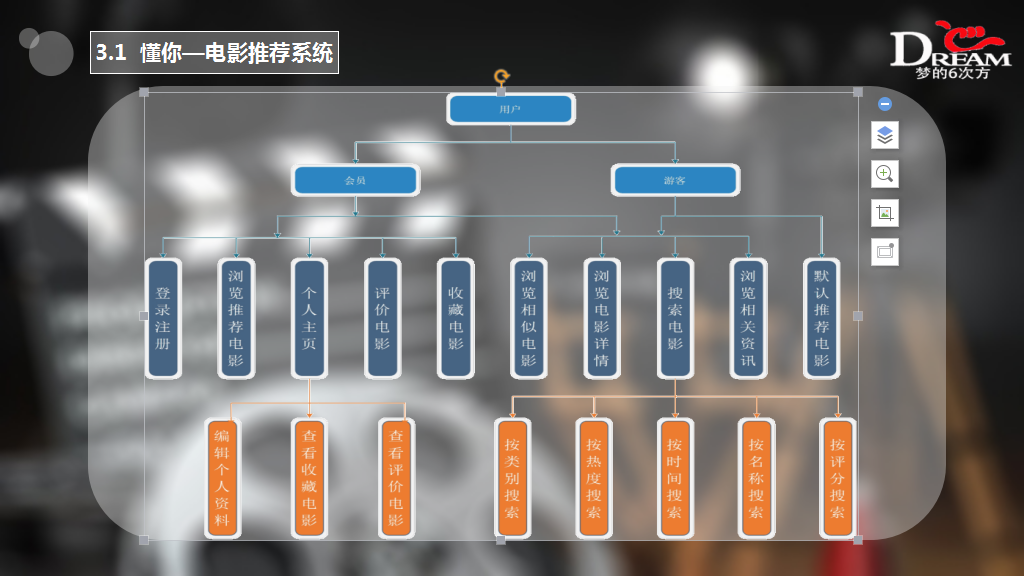
项目描述: 懂你电影推荐网站是一个基于 SSM 框架的 Web 项目,类似当前比较流行的豆瓣。用户可以在网站上浏览电影信息和查询电影,并且网站会根据用户的浏览记录给用户进行实时的电影推荐。现已将网站部署在 http://115.159.204.68 网站上,感兴趣的朋友可以自行查看。Git 的安装与 IDEA 和 GitHub 的集成可以参考博客。
项目架构:
三、后台管理系统
开发环境: IntelliJ IDEA + maven + Git + Linux + powerdesigner
软件架构: MySQL + MyBatis + Spring + SpringMVC + easyui
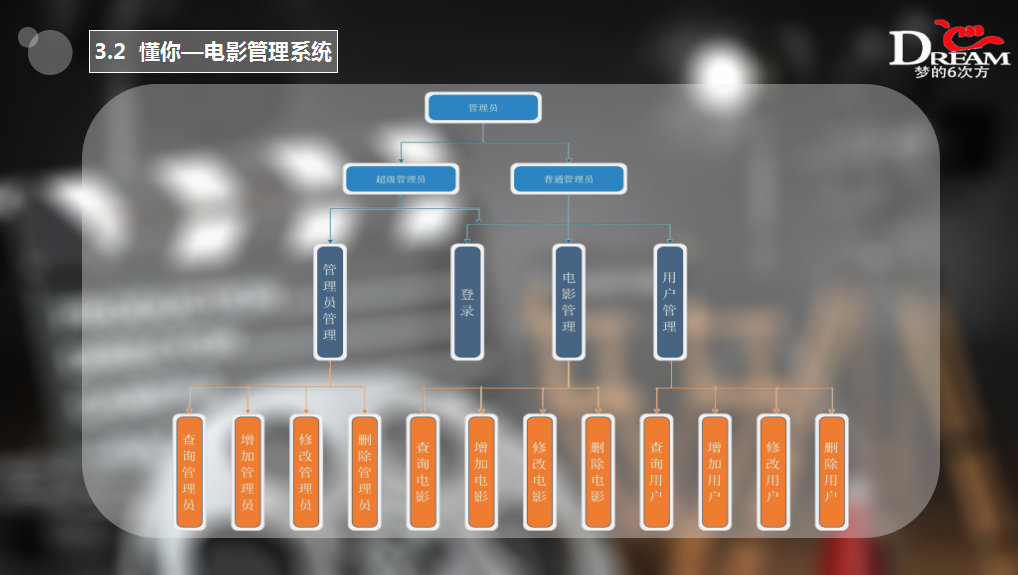
项目描述: 后台管理系统主要对用户信息和电影信息进行管理,如添加删除电影信息和完成用户信息的完善。其中为了更好地保存电影的图片信息,搭建了图片服务器,关于图片服务器 FastDFS 的搭建可参考博客。后台系统也布置在服务器上,感兴趣的朋友可以通过地址 http://115.159.204.68/ 访问,为大家提供的测试账号为 test,密码为 88888888。
项目架构:
四、推荐系统(Spark)
开发环境: IntelliJ IDEA + maven + Git + Linux
软件架构: hadoop + zookeeper + flume + kafka + nginx + spark + hive + MySQL
项目描述: 通过在电影网站系统埋点,获取到用户的点击事件(如用户喜欢哪部电影或对某部电影的评分)并将信息传至推荐系统,推荐系统根据该信息做出相应的处理,将推荐结果存入到 MySQL 数据库中,Web 前端通过查询数据库将推荐的电影展示给用户。推荐流程如下:
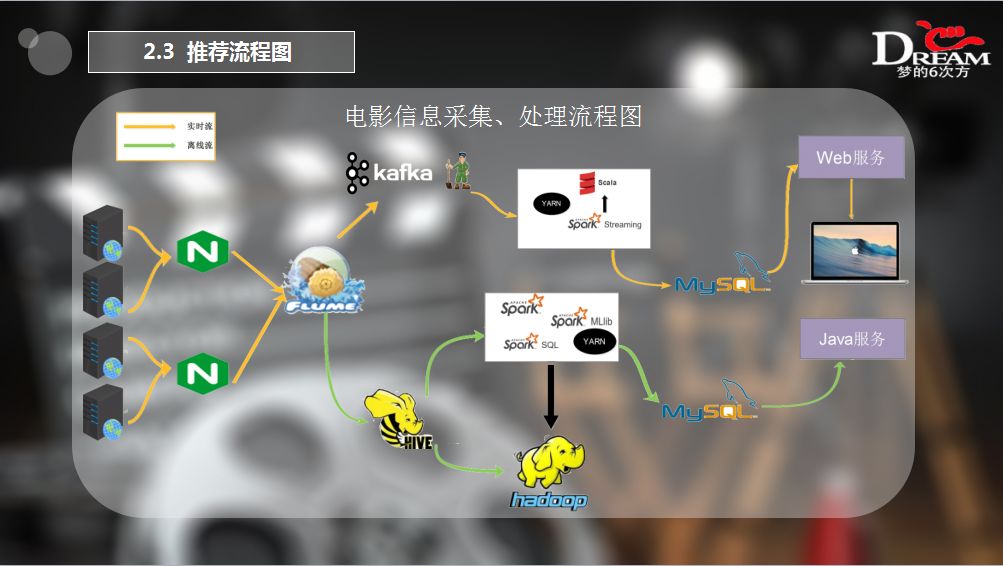
项目架构:

具体步骤:
1.服务器规划(Linux 镜像为 centos6):
- spark1(ip 192.168.13.134),分配 8G 内存,4 核
- spark2(ip 192.168.13.135),分配 6G 内存,4 核
- spark3(ip 192.168.13.136),分配 6G 内存,4 核
2.电影数据集,地址: 本次下载的为 1m 大小的数据集
3.环境的搭建:
1)hdfs 搭建
- spark1 上搭建 namenode,secondary namenode,datanode
- spark2 上搭建 datanode
- spark3 上搭建 datanode
2)yarn 搭建
- spark1 上搭建 resourcemanager,nodemanager
- spark2 上搭建 nodemanager
- spark3 上搭建 nodemanager
3)mysql 搭建
4)hive 搭建
5)spark 集群搭建,搭建 standalone 模式,spark1 为 master,其他为 worker
4.数据的清洗:
1)启动 hdfs: [root@spark1 ~]# start-dfs.sh
2)启动 yarn: [root@spark1 ~]# start-yarn.sh
3)启动 MySQL: [root@spark2 ~]# service mysqld start
4)启动 hive: [root@spark1 ~]# hive --service metastore
5)启动 spark 集群: [root@spark1 spark-1.6.1]# ./sbin/start-all.sh
6)代码(com.zxl.datacleaner.ETL)打包上传(spark-sql 与 hive 集成)
- 代码位于 package com.zxl.datacleaner.ETL,打包为 ETL.jar
- 运行代码 spark-submit --class com.zxl.datacleaner.ETL --total-executor-cores 2 --executor-memory 2g lib/ETL.jar
- 成功于 hive 中建表
5.数据的加工, 根据 ALS 算法对数据建立模型(ALS 论文)
1)启动 hdfs: [root@spark1 ~]# start-dfs.sh
2)启动 yarn: [root@spark1 ~]# start-yarn.sh
3)启动 MySQL: [root@spark2 ~]# service mysqld start
4)启动 hive: [root@spark1 ~]# hive --service metastore
5)启动 spark 集群: [root@spark1 spark-1.6.1]# ./sbin/start-all.sh
6)代码(com.zxl.datacleaner.RatingData)打包上传,测试建立模型
6.建立模型, 根据 RMSE(均方根误差)选取较好的模型
1)启动上述的服务
2)代码(com.zxl.ml.ModelTraining)打包上传,建立模型
注:com.zxl.ml.ModelTraining2 中代码训练单个模型,其中参数 rank=50, iteration = 10, lambda = 0.01
- 代码位于 package com.zxl.ml.ModelTraining,打包为 Spark_Movie.jar
- 运行代码 spark-submit --class com.zxl.ml.ModelTraining lib/Spark_Movie.jar
7.产生推荐结果
1)启动上述的服务
2)代码(com.zxl.ml.Recommender)打包上传,产生推荐结果
8.数据入库, 存储为所有用户推荐的电影结果,MySQL 中存入的格式为(userid, movieid,rating)
1)启动上述的服务
2)代码(com.zxl.ml.RecommendForAllUsers)打包上传,数据入库
- 运行代码 spark-submit --class com.zxl.ml.RecommendForAllUsers --jars lib/mysql-connector-java-5.1.35-bin.jar lib/Spark_Movie.jar
9.实时数据的发送
1)安装 nginx,用来接收电影网站上用户的点击信息,写入本地文件
2)安装 flume,实时监控本地文件,将数据发送至 kafka 消息队列中
10.实时数据的接收处理 ,如果打包到服务器运行错误,也可在本地 IDEA 上运行
2)安装 kafka,用来接收发送数据
3)启动上述的服务
4)启动 zookeeper: [root@spark1 soft]# zkServer.sh start
4)启动 flume:[root@spark1 flume]# bin/flume-ng agent -c ./conf/ -f conf/flume-conf.properties -Dflume.root.logger=DEBUG,console -n a1
5)启动 kafka: [root@spark1 kafka_2.11-0.10.1.0]# bin/kafka-server-start.sh config/server.properties
6)代码(com.zxl.datacleaner.PopularMovies2)运行,用于为没有登录或新用户推荐,默认推荐观看最多的 5 部电影
7)代码运行(需指定 jar 包 kafka-clients-0.10.1.0.jar)
- spark-submit --class com.zxl.streaming.SparkDrStreamALS --total-executor-cores 2 --executor-memory 1g --jars lib/kafka-clients-0.10.1.0.jar lib/Spark_Movie.jar















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









