







个性化视频推荐系统的设计与实现
摘 要
各种视频网站以及小视频的出现,自然的会产生大量的视频数据,产生的问题的是:用户怎么从这么多的视频数据里面选择自己喜欢的视频?我们用推荐系统来解决此问题。
本论文研究的是个性化视频推荐系统,主要是收集用户的爱好,以及 Web 的操作日志,例如用户的观看记录,观看后对视频的评分等信息。然后通过基于用户的协同过滤算法给用户推荐出符合用户的视频。
系统分为以下几个模块,用户模块:用户的相关操作,日志模块:收集用户在界面的操作日志,推荐模块:按照一定的算法给用户推荐视频,管理模块:对视频和用户的管理,例如添加新视频,修改视频相关操作,定时任务模块:计算推荐数据和执行相关的定时任务。各个模块通过共享数据库来衔接。系统前台使用 Bootstrap,jQuery,后台使用 Python 语言,Django Web 框架,采用 Oracle 数据库来开发。
关键词: 视频 协同过滤 模块 Django 推荐系统
Personalized video recommendation system design and implementation
ABSTRACT
The emergence of various video websites and small videos naturally generates a large amount of video data. The question arises:
How do users choose their favorite videos from so many video data? We use a recommendation system to solve this problem.
This dissertation studies the personalized video recommendation system, which mainly collects the user’s hobby and the web’s operation log, such as the user’s viewing record, the rating of the video after watching, and other information. Then the user is recommended to match the user’s video through a user-based collaborative filtering algorithm.
The system is divided into the following modules: user module: user-related operations, log module: collecting user’s operation logs in the interface, recommendation module: recommending videos to users according to certain algorithm, management module: managing videos and users, for example add new video, modify video-related operations, timing task module: calculate recommended data and perform related timing tasks. Each module connects through a shared database. The system front-end uses Bootstrap, jQuery, back-end Python language, Django web framework, and development using Oracle database.
Key Words: Video Collaborative filtering Module Django Recommendation system.
一、绪论
1.1 研究背景和意义
如今我们生活在一个大数据的时代,智能时代。网络的应用使得资源的产生和分享很容易。互联网用户不断的在增加,这些用户每天会产生大量的博客、视频、图片以及与个人兴趣爱好相关的数据。我们从原来的信息缺乏进入到信息过载[1]时代。对于产生这些信息的人来说,怎么让自己的信息更快的传播,对于消费这些信息的人,怎么找到符合自己的信息都是极大的挑战。
在人们面对海量的数据无法筛选出自己有用的信息时,出现了搜索引擎[2],从以前的文字搜索转变为如今的语音搜索,这都给用户带来了很多的便利。但是,搜索引擎是建立在用户的需求已知情况下,并且搜索结果很多是相近的,需要用户通过自己的主观意识去判断,那个是自己需要的。如果用户的需求不明确,就是为了放松或娱乐,主要得符合自己的兴趣爱好,那么有什么好的办法吗?
推荐引擎[3]就可以弥补搜索查找的这种不足。它知道你的爱好,知道你喜欢什么,因此可以快速的推荐出与你兴趣爱好对应的信息,方便了用户的筛选,减少用户看到重复的信息和厌烦的广告甚至不健康的信息,增加了体验效果。
推荐引擎还可以处理的一个问题是信息过多。我们都生活在互联网时代,网络的应用与生活息息相关。去超市不用带现金,坐公交可以不带公交卡,吃饭可以不去饭店等等,这么多的应用因此会产生大量的数据。推荐引擎能从这么多的数据中筛选自己有用的信息。
过去的视频网站例如优酷,腾讯视频,爱奇艺,搜狐等,主要是根据视频的分类和搜索引擎来搭建,随着推荐系统的发展,逐渐的在原来的基础之上都添加了推荐功能。还有很热的小视频抖音,快手,火山等,用户随手一拍就可以产生一个。它们主要以推荐为主,抓住了用户的兴趣。
每个人所属的行业不同,因此关注的领域不一样,不论推荐系统是推荐什么,主要的问题是把用户关注的领域各方面都能推荐给用户,如果是以领域划分的推荐系统,那么应该把这一领域的历史,相关的资料文章,以及涉及到人物等等都可以推荐给用户。这样对信息的传播也是很有价值,当然这些在技术实现上也需要很大的研究和发展。如果我们是推荐物品,那么抓住用户的兴趣是非常重要,达到个性化的推荐,有些系统的推荐是针对所有的用户,与用户的兴趣爱好并不相符,进而不是个性化的。应该站在用户的角度多考虑问题,减少用户的输入,提高自动化推荐的功能。最后还要能建立在用户以前的会话基础上,这样才能达到个性化的推荐。
1.2 国内外发展状况
1.2.1 推荐系统国外研究现状
“个性化推荐系统”一词是在 1995 年 3 月[4],斯坦福大学的 MarkoBalabanovic 等人在美国人工智能协会上所提出的。从此开启了推荐系统在互联网方面的大门。学术界在这方面也投入了大量的资源,取得了不错的成果,尤其对推荐算法的研究。目前为止,数据库、数据挖掘、机器学习方面的重要国际会议都有大量与推荐系统相关的研究成果发表。
美国的 Amazon[5],不管是在过内还是国外,在推荐系统方面是起步比较早的公司,并且也做的比较成熟。在 1998 年运用基于物品的协同过滤算法搭建了推荐系统。由于电子商务推荐对实时性要求较高,Amazon 采用了一种称为商品到商品的协同过滤算法,此算法可以在海量的数据中实时计算出推荐数据。
年在 IEEE Internet Computing 上发表了基于物品的协同过滤算法[6],该算法逐渐被传开。YouTube 的人员将他们的用户归为三类,第一,用户只在网站上观看一些与某一特定话题相关的视频;第二,在别处看到某一视频的部分,去网站看完整视频;第三,没有明确目的,只是看可以使自己喜悦的视频。为了满足第三种类型的人,2010 年 YouTube 也使用协同过滤算法做他们的视频推荐[7]。
Netflix 也有他们的推荐系统,并且 Netflix 的人员声称他们的观看记录大多是来自他们的推荐系统推荐的电影[8],推荐系统给用户带来了极大的便利。
1.2.2 推荐系统国内研究现状
国内的互联网虽然没有国外的起步早,但是近几年发展非常迅速。推荐系统方面也不例外。比如在国内非常受关注的个性化推荐网站豆瓣[9]。在 2009 年 7 月,我国出现了在推荐系统方面的研究团队。2011 年 9 月,李彦宏将推荐引擎等划入未来发展的方向[10]。渐渐的国内在推荐系统应用方面也逐步扩大,表 1.1 展示了国内部分在推荐系统方面的应用。
表 1.1 国内推荐系统应用
| 领域 | 推荐系统 |
|---|---|
| 电子商务 | 淘宝网、京东商城、当当 |
| 新闻 | 今日头条 |
| 视频 | 爱奇艺、优酷、豆瓣、抖音 |
| 阅读 | 知乎、简书 |
| 音乐 | 网易云音乐、QQ 音乐 |
| 其他 | 社交软件推荐可能认识的人 |
在中国知网上,通过关键词“个性化推荐系统”去检索,会出现很多的相关文献,图 1.1 展示了 2001 年到 2018 年学术界在这方面发表的文献的数量,可以看出基本呈指数的形式在上升。体现了推荐系统应用的广泛性以及对推荐系统的关注度。
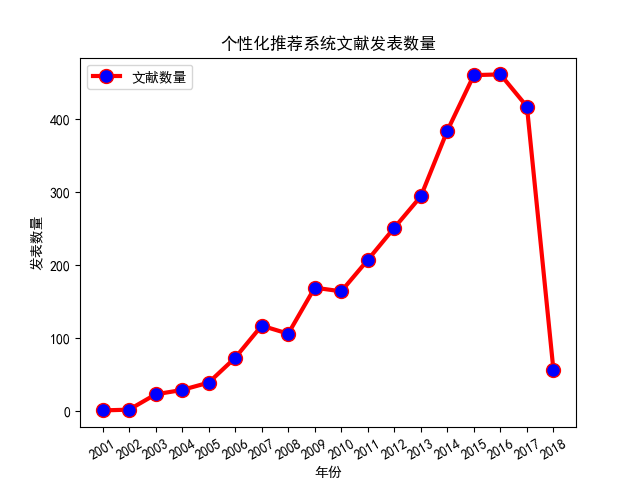
图 1.1 个性化推荐系统学术关注度
在国内,在推荐系统方面的研究主要集中在推荐算法和模型的构建[11],现在我们已经进入了大数据的时代,互联网上可以爬去大量的数据,通过机器学习然后训练构建切实际的模型。算法的研究主要是改进算法,例如范波[12]等人应用了一种基于用户间多相似度的协同过滤算法来改进单一的评分相似度的缺点。
1.3 论文内容结构
此论文的讲解由五部分构成,各部分的基本内容如下:
- 第一章,讲解研究推荐系统的原因,研究推荐系统有什么意义,以及国内外在推荐系统方面的研究状况进行概述。
- 第二章,讲解个性化视频推荐系统开发涉及到的技术,以及推荐系统普遍的框架构成,和推荐系统中常用的推荐算法。
- 第三章,从软件工程的角度考虑问题,讲解系统的需求分析,设计,数据库的设计。
- 第四章,从开发实现的角度讲解,给出具体的实现流程,落实于实现思路。
- 第五章,为了系统能够稳定安全的运行,进行系统测试。
1.4 本章小结
本章主要讲解研究个性化视频推荐系统有什么意义,为什么要研究,以及推荐系统在国内外的发展状况,第三小节对整个论文的结构内容进行了概括,以便读者能够提前了解论文的讲解思路。
二、个性化视频推荐系统相关技术
2.1 推荐系统开发环境及技术
个性化视频推荐系统用面向对象的解释性 Python 语言开发[13],在强大的 PyCharm 集成开发环境软件的支持下,利用开放源代码的 Django Web 框架[14]所开发,这样能够降低设计的成本,节省开发时间。系统开发和运行环境介绍如下:
- 硬件环境:CPU 类型为 i5,内存为 8G
- 数据库系统:Oracle 11.2.0
- 开发工具:HTML、JavaScript、CSS、Python3.6、PyCharm
- 项目框架:前台 BootStrap、后台使用 Django Web 框架
- 代码管理:GitHub
2.1.1 PyCharm 简介
PyCharm 是 JetBrains 公司开发的一款商业的 Python 集成开发环境,如图 2.1,编写代码会给出提示,不同的语法颜色不同,例如关键字,字符串等字体颜色不一样,并且集成版本控制管理工具,对开发人员的操作提供便利,最主要的是有调式功能,对每一个开发人员,调式是开发人员必备技能,很快能定位到错误的位置或者能深入的了解程序运行的过程。我们的系统是基于 Web 的,该编辑器还支持 Web 开发。
图 2.1 PyCharm 工作平台
2.1.2 Django 简介
基于 Python 的 Web 框架有 Django,Flask,Tornado,Bottle 等等,本系统采用 Django 框架,是一个开放源代码的 Web 型框架。使用了 MTV 的架构模式,即模型 M(model),模板 T(template)和视图 V(view)。提供了很多的模块,最主要的有 admin 模块,可以很好的管理后台,并且能方便的集成第三方的插件。还有它内置 Web 服务器,这样给开发测试带来了极大好处。如图 2.2 是 Django 的工作模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2140
2140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









