







①什么是hive
为了让所有人想对hadoop的hdfs上面存储的大数据进行分析、统计和计算时,避免自己去手写mapreduce,好多数据分析师、数据统计师他们可能是只会sql,为了符合大众的需求,降低hadoop的使用门槛,诞生了hive。hive基于hadoop最核心的两个组件:存储(hdfs)和计算(mapreduce)。存储方面提供了数据仓库相关的 功能,相当于提供了数据仓库的模型,你可以用hive在hadoop里面建表,然后建立索引、视图等等内容。在计算方面,基于hive在hadoop搭建的数据仓库,可以对里面的表用sql语句进行统计分析。可以降低hadoop使用门槛。sql语句会被翻译成hadoop底层的mapreduce程序。
②拷贝
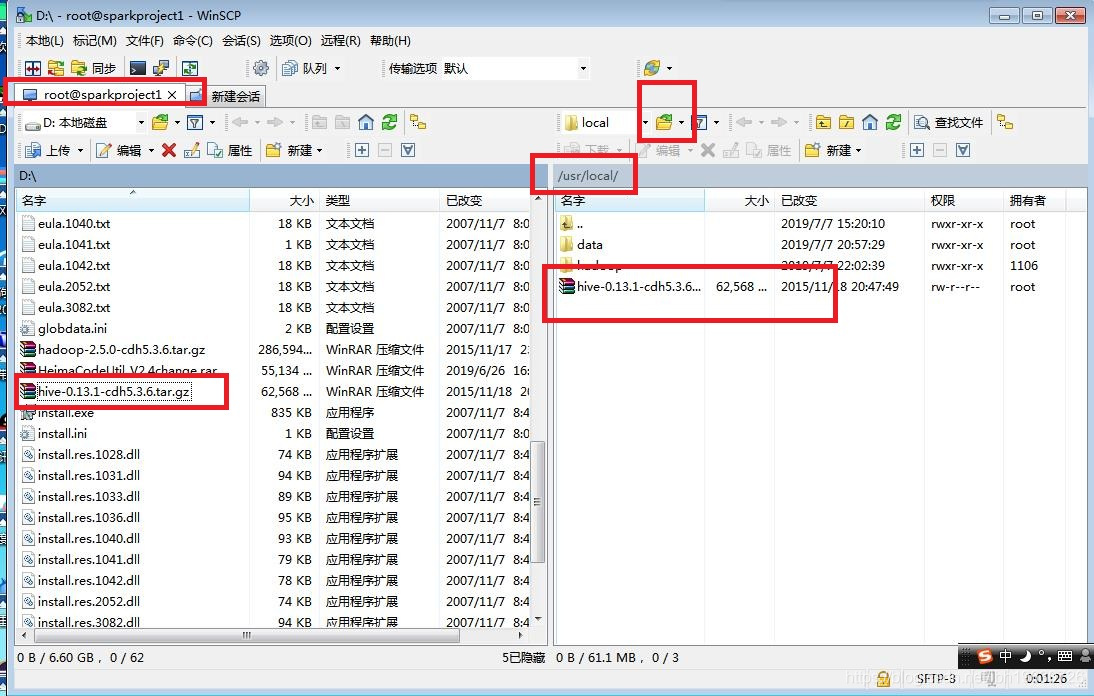
打开WinSCP软件,将hive-0.13.1-cdh5.3.6.tar.gz文件上传到sparkproject1虚拟机的/usr/local/目录下面。
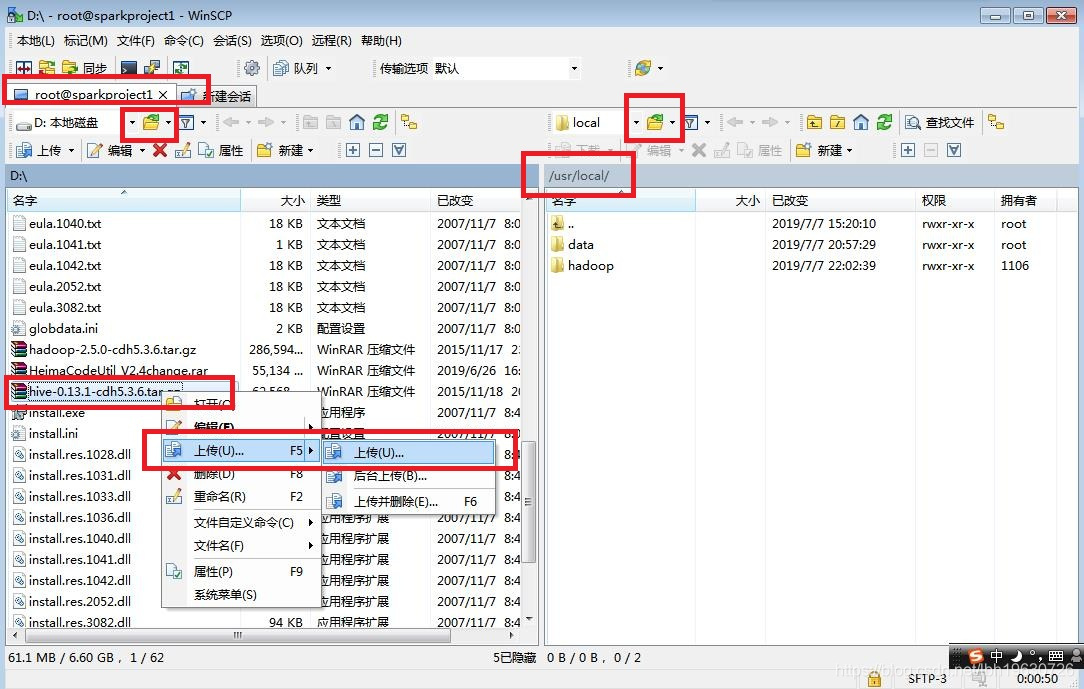
然后在sparkproject1中的/usr/local/目录下输入:ll
发现多了一个hello.txt文件,然后输入:rm -rf hello.txt将hello.txt文件删除。
然后再输入:ll,发现只有data文件夹、hadoop文件夹和刚刚上传的hive-0.13.1-cdh5.3.6.tar.gz文件。
然后对hive-0.13.1-cdh5.3.6.tar.gz文件进行解压缩,在/usr/local/目录下输入:tar -zxvf hive-0.13.1-cdh5.3.6.tar.gz
然后输入:ll
然后输入:rm hive-0.13.1-cdh5.3.6.tar.gz
再输入:y,将这个tar包删除。
再对hive-0.13.1-cdh5.3.6这个文件夹进行重命名成hive,让后面配置起来比较方便,输入:mv hive-0.13.1-cdh5.3.6 hive
③配置hive相关的环境变量
在sparkproject1的/usr/local/目录下输入:vi ~/.bashrc
然后输入 i 键,插入内容:export HIVE_HOME=/usr/local/hive
export PATH=........:$HIVE_HOME/bin
最后内容变为:export JAVA_HOME=/usr/java/latest
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
然后source一下环境变量,输入:source ~/.bashrc
在sparkproject1的/usr/local/目录下输入:cd hive/
再输入:ll,发现有bin文件夹
再输入:cd bin/
再输入:ll,有bin目录,而且bin目录里面有内容,则正确。
④安装mysql
安装mysql有两个用途:
用途一:用来作为hive的元数据
用途二:后面spark项目计算出来的数据存放到mysql中。能够让J2EE能从mysql中读取到这些数据,然后进行转视,或者进行业务逻辑上的功能。
在sparkproject1的/usr/local/目录下输入:free,查看可用内存
看Mem这一行,free下面这一列,有:123576即123M左右
1、然后用yum安装mysql,先安装mysql的server,输入:yum install -y mysql-server,大概一两分钟可以装好。
然后用service命令启动mysql服务,输入:service mysqld start,启动完成。
然后配置mysql,让机器已启动,这个mysql进程就启动,输入:chkconfig mysqld on
2、再来用yum安装mysql的connector,输入:yum install -y mysql-connector-java
然后:将mysql的connector(即mysql连接的驱动包)拷贝到hive的lib包中,输入命令:
cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/local/hive/lib
3、在mysql上创建hive元数据库,然后创建hive账号,并进行授权。
首先:在sparkproject1的/usr/local/目录下输入:mysql,进入mysql的客户端。
然后在mysql>后面输入:create database if not exists hive_metadata;
再在mysql>后面输入:grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
再在mysql>后面输入:grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
再在mysql>后面输入:grant all privileges on hive_metadata.* to 'hive'@'sparkproject1' identified by 'hive' ;
再在mysql>后面输入:flush privileges;
再在mysql>后面输入:use hive_metadata;
⑤配置hive-site.xml
先在mysql>后面输入:exit,退出mysql
回到sparkproject1的/usr/local/目录下,然后输入:ll,查看到有hive文件夹
然后输入:cd hive/
再输入:ll,查看到conf文件夹
然后输入:cd conf/
再输入:ll,查看到hive-default.xml.template
然后将这个文件重命名成hive-site.xml文件,输入:mv hive-default.xml.default hive-site.xml
然后再输入:ll,查看到hive-site.xml文件
再输入:vi hive-site.xml
输入键盘的 i 键,插入内容,但是这里是更改内容,所以就不这样做
用WinSCP文件将sparkproject1中的hive-site.xml文件传输到Windows系统主机下,然后用nodepad++打开,ctrl+f 打开查找器
首先查找:javax.jdo.option.ConnectionURL
然后将对应的<value>里面的值修改为:
jdbc:mysql://sparkproject1:3306/hive_metadata?createDatabaseIfNotExist=true
然后要将<name>值为:javax.jdo.option.ConnectionDriverName,对应的<value>值修改为:
com.mysql.jdbc.Driver
然后要将<name>值为:javax.jdo.option.ConnectionUserName,对应的<value>值修改为:
hive
然后要将<name>值为:javax.jdo.option.ConnectionPassword,对应的<value>值修改为:
hive
然后ctrl+f 搜索<name>值为:hive.metastore.warehouse.dir,修改对应的<value>值为:
/user/hive/warehouse
然后再在WinSCP软件中把Windows系统主机上面的hive-site.xml文件覆盖sparkproject1虚拟机上的hive-site.xml
⑥配置hive-env.sh和hive-config.sh
在sparkproject1的/usr/local/hive/conf/目录下,输入:ll,会发现文件hive-env.sh.template,将这个文件改名为:hive-env.sh
在conf目录下输入:mv hive-env.sh.template hive-env.sh
然后在conf目录下输入:cd ..
在hive目录下输入:cd bin/
再输入:ll,发现hive-config.sh文件
即在sparkproject1的/usr/local/hive/bin/目录下,修改hive-config.sh,输入:vi hive-config.sh
然后输入键盘 i 键,插入内容:
export JAVA_HOME=/usr/java/latest
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
把上面这三段放在#processes --config option from command line上面,但前面都不要加井号。
⑦最后测试一下
首先:在sparkproject1虚拟机的/usr/local/目录直接输入hive,可以进入hive命令行即hive>
然后在hive>,输入:exit;先退出
再在Windows系统主机下新建文件users.txt
内容为:
1 leo
2 jack
3 jen
4 marry
5 tom
再通过WinSCP软件将这个users.txt文件上传到sparkproject1虚拟机的/usr/local/文件目录下
然后再在/usr/local/目录下输入:hive
然后在hive>下输入:create table users(id int,name string) ;
(题外话:如果要删除这张表用命令:drop table users;)
然后在hive>下输入:load data local inpath '/usr/local/users.txt' into table users;
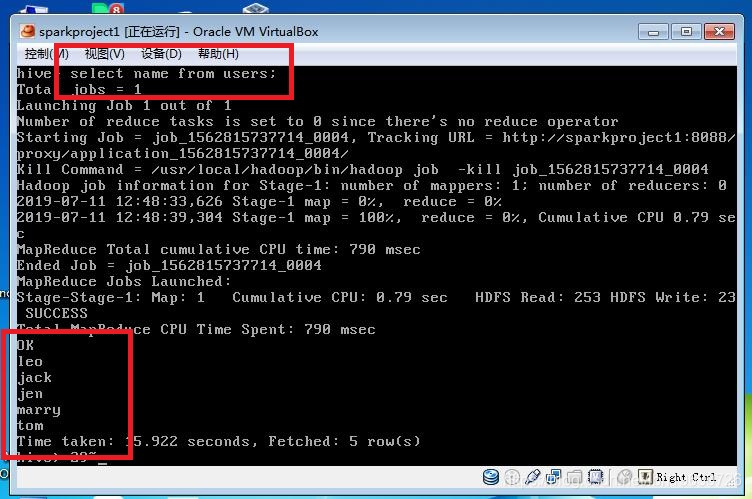
在hive>输入:select * from users;
都查出来,但可能显示都是null
再在hive>输入:select name from users;会发现机器把sql语句翻译成了mapreduce程序。也查出来了,也可能显示都是null。
在hive>下输入:exit;退出hive>
此时:在/usr/local/目录下:输入ll,有一个users.txt文件
输入键盘 i 键,插入数据
1 leo
2 jack
3 jen
4 marry
5 tom
注意:让id和name之间保持一个tab的距离
然后按Esc键,输入:wq保存并退出。
然后在local目录下输入:hive,进入hive>
再在hive>下输入:drop table users;
在hive>下输入:create table users(id int ,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
(表示:row即列之间用\t即tab键分开,而lines即行之间用回车即\n分开)


⑧重启三台虚拟机后,要重新执行二、hadoop-2.5.0-cdh5.3.6集群搭建的后面的启动步骤,才能启动hive命令
但是发现start-dfs.sh报错

fatal:错误
...... yarn.xml ...... [xX][mM][lL] is not allowed
打开yarn.xml发现第一行为空白行,则不对,删除第一行的空白行,不让第一行有空白。
再执行start-dfs.sh可成功。
这个问题处理以后:start-yarn.sh也可以用了。不用再在sbin目录下./start-yarn.sh了。














 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









