







《MLAPP》读书笔记
1.1 机器学习:它是什么?为什么是它?
We are drowning in information and starving for knowledge.
——John Naisbitt
随着信息技术的发展,我们开始步入大数据时代,人类每天都在产生大量的、各种各样的数据。以往统计学家所用的方法已经不适合用于大规模的数据分析,于是,机器学习来了。
机器学习在此书的定义为:一个自动发现数据里的模式并利用这些未被发现过的模式去预测未来数据的方法集合。
机器学习被划分为两个主要大类:监督学习(supervised learning)和非监督学习(unsupervised learning)。
监督学习的目标是找出自变量X到因变量Y之间的映射。
非监督学习的目标是找出数据中“有趣的模式”,有些时候又被称为“知识发掘”。
第三种机器学习是强化学习(reinforcement learning),它并没有广泛在实际中应用,它用于学习在给定特定的奖惩信号下如何行动和表现。
1.2 监督学习
(1)分类
分类的目标是通过学习产生一个从输入x到输出y的一个映射,这里,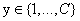
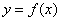
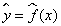
实在受不了用图片写公式了,又不能把文章直接转到Markdown里继续写,先写到这里,后面的内容,用Markdown写...















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









