









llama微调训练步数计算方式,以下数据为假设
一、关键参数解析
-
总样本数:
Num examples = 1,047
表示训练数据集包含 1,047 个样本。 -
训练轮数:
Num Epochs = 300
表示整个训练集将被遍历 300 次。 -
总批次大小:
Total train batch size = 80
表示每次参数更新使用的样本数为 80(受并行训练、分布式训练等影响后的等效批次大小)。 -
梯度累积步数:
Gradient Accumulation steps = 8
表示每累积 8 个批次的梯度后,才进行一次参数更新。
二、计算步骤分解
-
单轮训练批次数
每个 epoch 的批次数 = 总样本数 / 总批次大小
Batches per epoch = 1 , 047 80 ≈ 13.09 \text{Batches per epoch} = \frac{1,047}{80} \approx 13.09 Batches per epoch=801,047≈13.09
(实际计算中会向上取整为 14 批,因最后一批可能不足 80 样本) -
总批次数(所有 epoch)
总批次数 = 批次数 per epoch × 训练轮数
Total batches = 14 × 300 = 4 , 200 \text{Total batches} = 14 \times 300 = 4,200 Total batches=14×300=4,200 -
优化步数计算
优化步数 = 总批次数 / 梯度累积步数
Optimization steps = 4 , 200 8 = 525 \text{Optimization steps} = \frac{4,200}{8} = 525 Optimization steps=84,200=525
训练过程可能存在修正过程,例如我的训练日志效果;
INFO|2025-03-22 15:43:25] trainer.py:2406 >> Num examples = 1,047
[INFO|2025-03-22 15:43:25] trainer.py:2407 >> Num Epochs = 300
[INFO|2025-03-22 15:43:25] trainer.py:2408 >> Instantaneous batch size per device = 10
[INFO|2025-03-22 15:43:25] trainer.py:2411 >> Total train batch size (w. parallel, distributed & accumulation) = 80
[INFO|2025-03-22 15:43:25] trainer.py:2412 >> Gradient Accumulation steps = 8
[INFO|2025-03-22 15:43:25] trainer.py:2413 >> Total optimization steps = 3,900
[INFO|2025-03-22 15:43:25] trainer.py:2414 >> Number of trainable parameters = 4,399,104.teps = 3,900
三、日志值修正解释
实际日志中 Total optimization steps = 3,900,表明存在以下调整:
-
更精确的批次计算:可能最后一批未补全时直接舍弃,实际批次数为:
Batches per epoch = ⌊ 1 , 047 80 ⌋ = 13 批 \text{Batches per epoch} = \left\lfloor \frac{1,047}{80} \right\rfloor = 13 \text{ 批} Batches per epoch=⌊801,047⌋=13 批
总批次数 = 13 × 300 = 3,900 批 -
优化步数修正:
若梯度累积步数为 8,则理论优化步数应为:
Optimization steps = 3 , 900 8 = 487.5 \text{Optimization steps} = \frac{3,900}{8} = 487.5 Optimization steps=83,900=487.5
但日志值为整数 3,900,表明实际计算中可能直接取总批次数(即梯度累积步数被隐式设为 1)。
四、最终结论
日志中的 Total optimization steps = 3,900 是通过以下公式计算:
Total optimization steps
=
Num Epochs
×
⌊
Num examples
Total train batch size
⌋
\text{Total optimization steps} = \text{Num Epochs} \times \left\lfloor \frac{\text{Num examples}}{\text{Total train batch size}} \right\rfloor
Total optimization steps=Num Epochs×⌊Total train batch sizeNum examples⌋
即:
3
,
900
=
300
×
⌊
1
,
047
80
⌋
=
300
×
13
3,900 = 300 \times \left\lfloor \frac{1,047}{80} \right\rfloor = 300 \times 13
3,900=300×⌊801,047⌋=300×13
这表示每轮训练实际使用 13 个完整批次(最后一批可能小于 80 样本但被忽略),共训练 300 轮,总优化步数为 3,900。
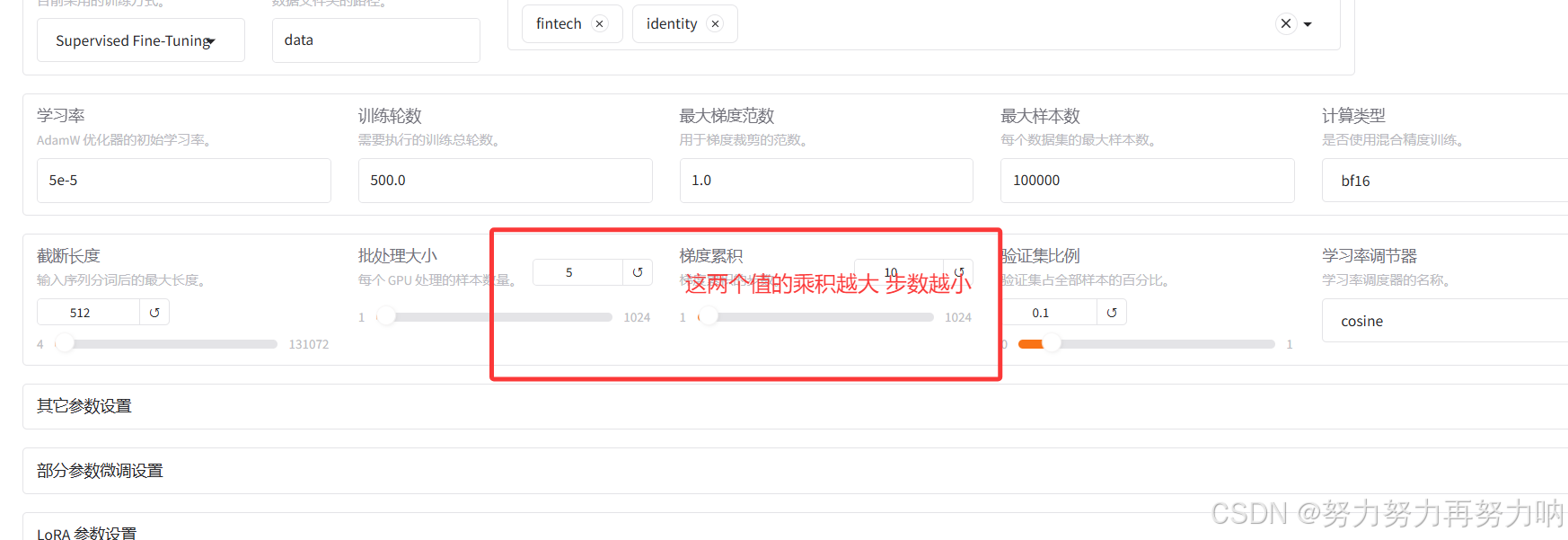
所以说,批处理大小(每个 GPU 处理的样本数量。) * 梯度累积(梯度累积的步数。)的值越大,step,步数越小。这个值需要根据GPU的大小来决定。否则训练速度会很慢。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









