






目录
YOLOv5的结构如下:
Backbone:采用了Focus(特殊的下采样)结构, CSP结构(CSPNet的跨阶段局部融合网络),减少bp时梯度信息的重复, 降低计算量,提高CNN的学习能力。(CSP结构解释:将原输入分成两个分支,分 别进行卷积操作使得通道数减半,然后一个分支进行Bottleneck * N操作,然后 concat两个分支,使得BottlenneckCSP的输入与输出是一样的大小,这样是为 了让模型学习到更多的特)
Neck:模块采用PFN+PAN,融合不同维度的特征。
head:部分与YOLOv4相同,三个输出头,分别对应8,16,32stride,不 同stride的输出预测不同尺寸的目标。
Focus
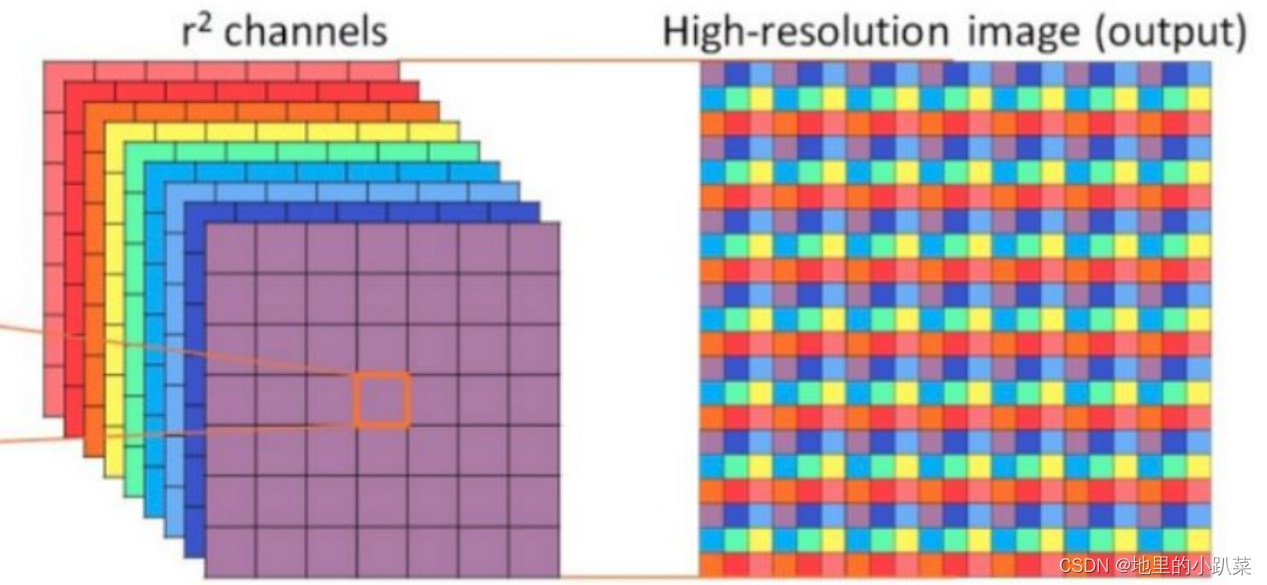
Focus是YOLOv5在网络结构中变化的地方,就是将特征切片成4份,每一 份将相当于下采样(stride=2)的特征,然后在channel维度进行concat。
Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在 Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其 他部分也进行了调整
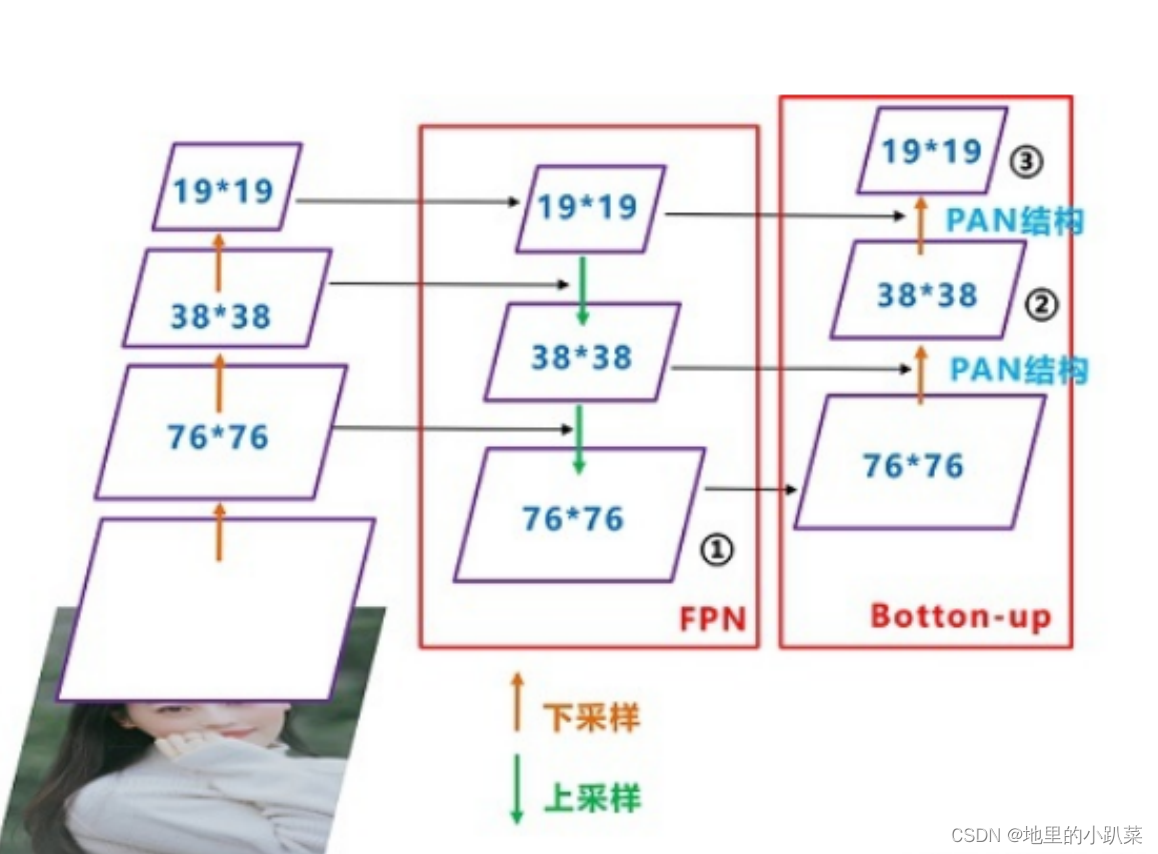
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构 中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
YOLOv5引入了depth_multiple和width_multiple系数来得到不同大小模 型:

depth_multiple表示channel的缩放系数,就是将配置里面的backbone和 head部分有关通道的设置,全部乘以该系数即可。而width_multiple表示 BottleneckCSP模块的层缩放系数,将所有的BottleneckCSP模块的number系 数乘上该参数就可以最终的层个数。
模型输入端
1.Mosaic数据增强
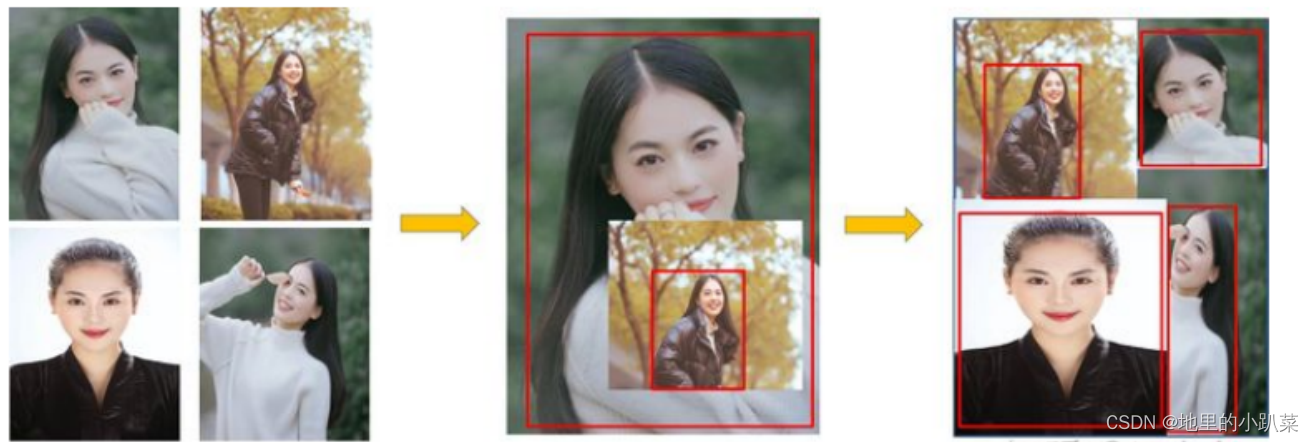
Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式 进行拼接。我们知道目标检测难点一直是对小目标的检测定位,主要原因是, 第一,coco数据集中大中小目标占比不均衡,小目标的数量很多,但出现的频 率却很低,这导致bp时对小目标的优化不足。第二,小目标本身检测难度就高 于大目标,容易出现误检与漏检。
作者提出Mosaic,随机使用4张图片,随机缩放,再随机分布进行拼接,大 大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更 好。与此同时,Mosaic可以减少GPU的投入,使得小的bachsize也能训练出好 的模型。
2.自适应anchor
check_anchors函数通过遗传算法与kmeans迭代算出最大可能召回率的 anchor组合,这样生成的自适应anchor能够更好的配合网络,提高模型精度, 减少对anchor的设计难度,非常实用。
3.自适应图片缩放(letterbox)
为了提高模型推理速度,yolov5提出自适应图片缩放,即根据长宽比对图 像进行缩放,并添加最少的黑边,减少计算量。
做法比较简单,用缩放后的长边减去短边,用此值去对32取余,就得到 padding。

LOSS
YOLOV5分类分支采用的loss是BCE,conf分支也是BCE,当然可以通过 h[‘fl_gamma’]参数开启focal Loss,默认配置没有采用focal los,而bbox分支采 用的是Giou loss。
YOLOv5中最有亮点的改变是对正样本的定义。在yolov3中,其正样本区域 也就是anchor匹配策略非常粗暴:保证每个gt bbox一定有一个唯一的anchor 进行对应,匹配规则就是IOU最大,并且某个gt一定不可能在三个预测层的某几 层上同时进行匹配。然而,我们从FCOS等论文中了解到,增加高质量的正样本 anchor能够加速模型收敛并提高召回。因此,YOLOv5对此做出了改进,提出 匹配规则:
(1) 采用shape匹配规则,分别将ground truth的宽高与anchor的宽高求比 值,如果宽高比例小于设定阈值,则说明该GT和anchor匹配,将该anchor认定 为正样本。否则,该anchor被滤掉,不参与bbox与分类计算。
(2) 将GT的中心最邻近网格也作为正样本anchor的参考点。因此,bbox的 xy回归分支的取值范围不再是0-1,而是-0.5-1.5(0.5是网格中心偏移),因为跨 网格预测了。
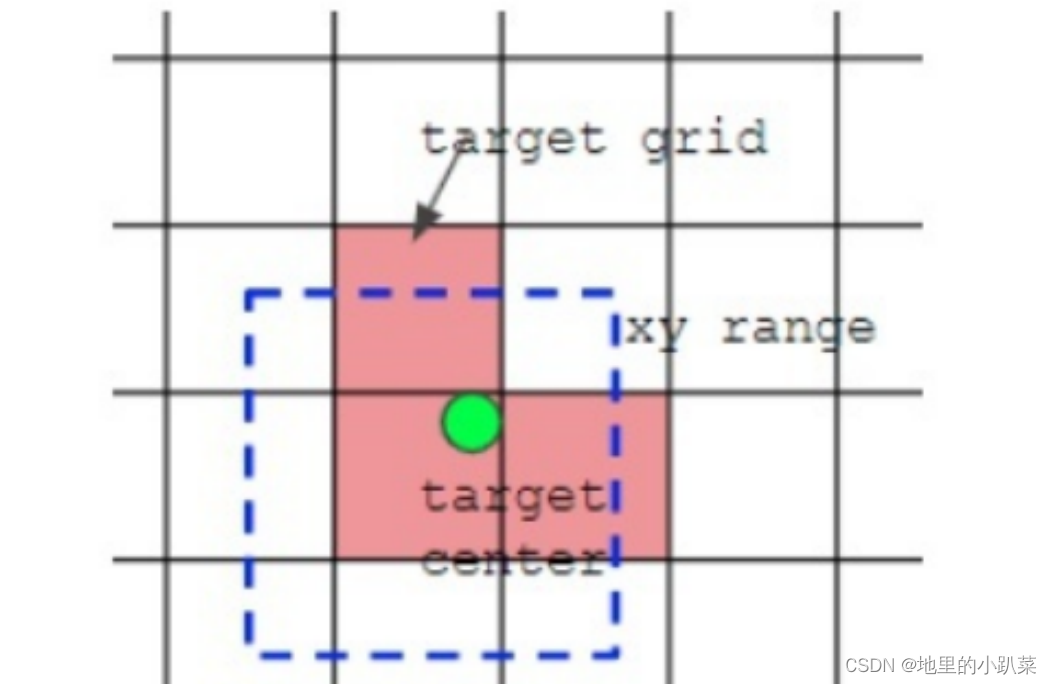
但是,在置信度方面,模型将与GT的iou过小的低质量anchor引入计算 BCE,因此,模型容易产生误检,即将非目标推测为目标物体。
代码分析
下面我们参考代码,具体看一下YOLOV5是如何改进的。
build_targets函数用于计算loss函数所需要的target(正样本anchor)。 其大概流程为:
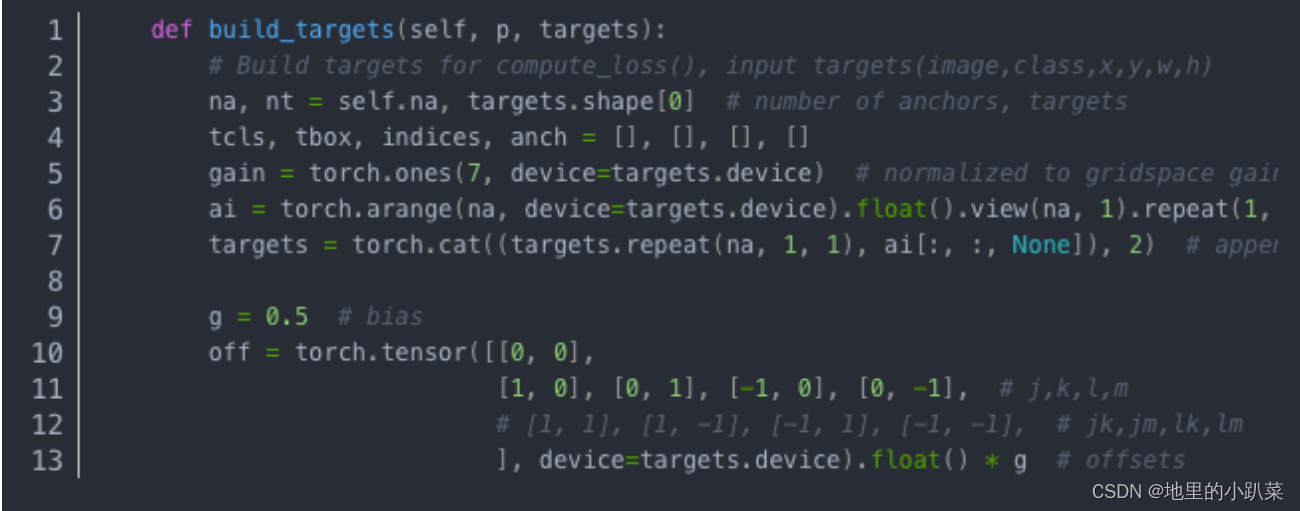
gain = torch.ones(7, device=targets.device),gain是输出的channel数, 包含image,class,x,y,w,h,conf。targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices 将target复制3编,即每层anchor个数为3,target可以与每一层的3个不同size的anchor进行匹配。off是坐标的偏移,中心点以及上下左右4个分支。
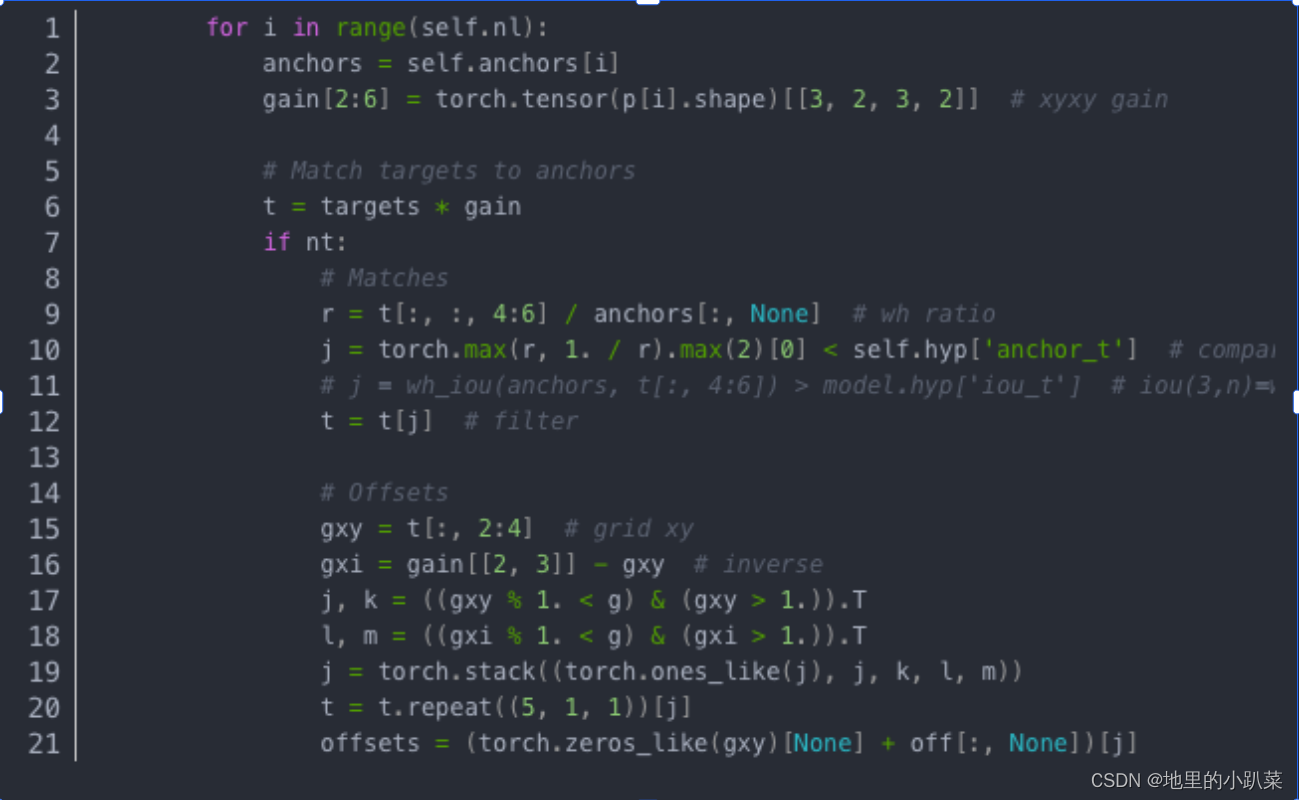
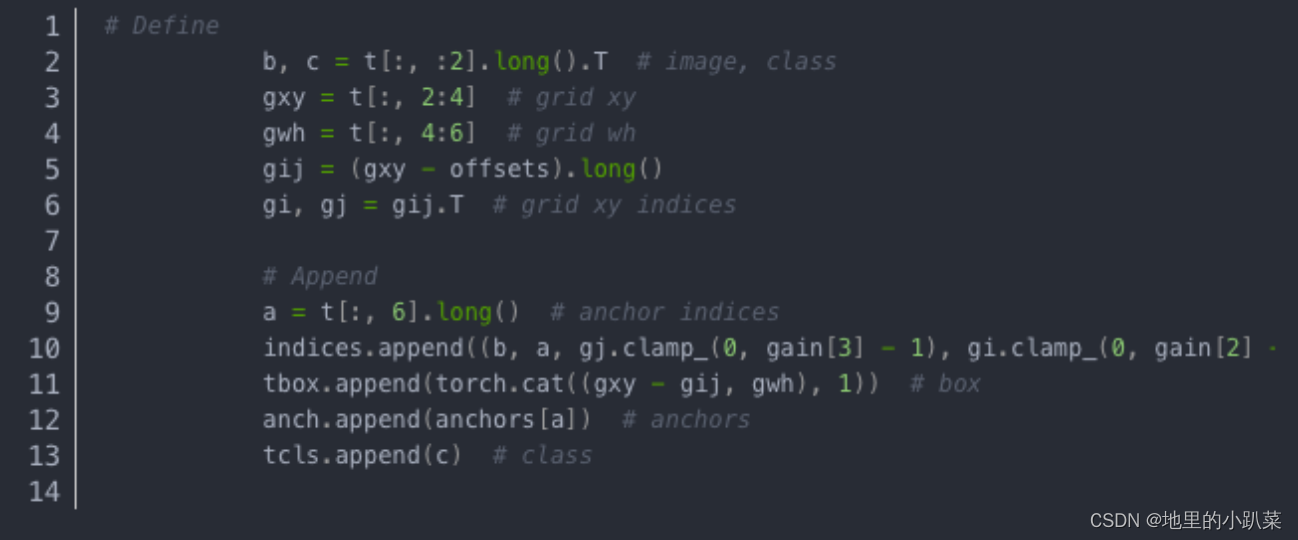
将targets归一化的xywh还原到特征图尺寸,方便与anchor(特征图尺 寸)进行比较,从而,将宽高比低于self.hyp[‘anchor_t’]=4的anchor滤出。j,k 与l,m选出最近的两个中心点。t = t.repeat((5, 1, 1))[j]在5个点中选择其中的3个 作为中心点。
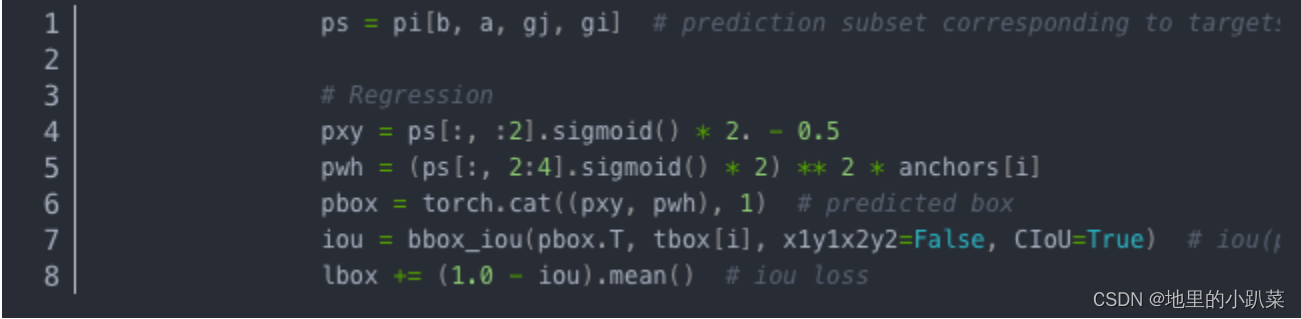
由于其采用了跨网格预测, pxy = ps[:, :2].sigmoid() * 2. - 0.5,故xy预测 输出不再是0-1,而是-1~1,加上offset偏移,则为-0.5-1.5;pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]由于shape过滤规则,wh预测输出也不再 是任意范围,而是0-4。
为了缓解低质量正样本对模型性能的影响,作者对置信度做出了改进。原 本正样本对用的conf label是1,但是低质量的正样本由于IOU小,不应该将其 置信度理解为1,他们应对应比1小的conf label。因此,作者将IOU作为系数与 gr相乘重新获取conf label。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









