



目录
5、Panoramic segmentation(全景分割)
一、概念与定义
下图展示了图像分类、语义分割、目标检测、实例分割四种任务(图片来 自【1】):
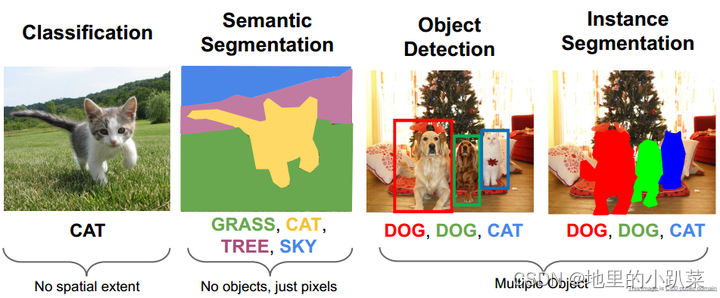
上图展示了四种任务的研究目标,具体如下:
图像分类:判别图中物体是什么,比如是猫还是狗;
语义分割:对图像进行像素级分类,预测每个像素属于的类别,不区分 个体;
目标检测:寻找图像中的物体并进行定位;
实例分割:定位图中每个物体,并进行像素级标注,区分不同个体;
1.1、图像分类
图像分类任务目的是判断图像中包含物体的类别,如果期望判别多种物体 则称为多目标分类。需要注意的是,基本的图像分类任务并不要求给出物体所 在位置,也不需要判断含有物体的数量。下图中含有多种物体,分类任务的目 标可以是判断图片中是否含有“狗”(图来自BigGAN):

1.2 、目标检测
如果项目的需求是精确的定位出图像中某一物体类别信息和所在位置,则 应该选择目标检测算法。基于深度学习的目标检测算法主要分为单阶段(onestage)和两阶段(two-stage)两种,单阶段算法的速度较快,两阶段算法的 精度较高(总体上)。下图(来自YOLOv1)展示了各种目标检测任务,比如左 边检测的目标是鹰,右边检测的目标是飞机,均精确的预测出了目标所在的位 置:

1.3 语义分割
语义分割任务需要对图像中所有像素点进行分类,将相同类别的像素归为相同的标签(常常采用相同的像素点表示)。需要特别注意的是,语义分割是在像素级别进行的。下图(来自FefineNet)中展示了街景分割,图中的街道、车辆、树木和行人等分别采用不同的颜色进行标注,即进行了语义级别的分割。

1.4 、实例分割
相比于语义分割,实例分割不仅需要将图像中所有像素进行分类,还需要区分相同类别中不同个体。比如,语义分割只需要将下图中的所有猫的像素进行归类,而实例分割需要将猫这一类中单独的个体进行像素分类。

二, 图像分类,目标检测,语义分割的区别
1、Imge Classification(图像分类)
图像分类(下图左)就是对图像判断出所属的分类,比如在学习分类中数据集有人(person)、羊(sheep)、狗(dog)和猫(cat)四种,图像分类要求给定一个图片输出图片里含有哪些分类,比如下图的例子是含有person、sheep和dog三种

2、Object detection(目标检测)
目标检测(上图右)简单来说就是图片里面有什么?分别在哪里?(把它们用矩形框框住)
目前常用的目标检测算法有Faster R-CNN和基于YOLO的目标检测的算法
3、semantic segmentation(语义分割)
通常意义上的目标分割指的就是语义分割
语义分割(下图左)就是需要区分到图中每一点像素点,而不仅仅是矩形框框住了。但是同一物体的不同实例不需要单独分割出来。对下图左,标注为人,羊,狗,草地。而不需要羊1,羊2,羊3,羊4,羊5等。
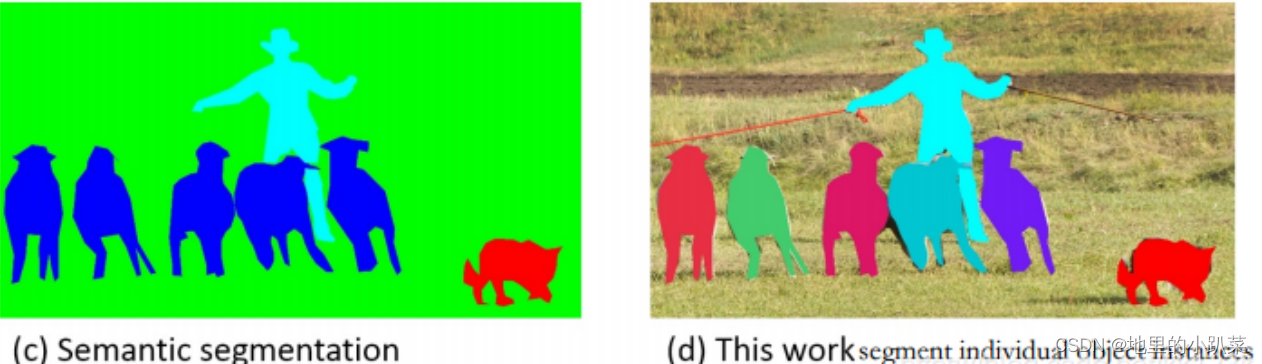
4、Instance segmentation(实例分割)
实例分割(上图右)其实就是目标检测和语义分割的结合。相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体(羊1,羊2,羊3...)
目前常用的实例分割算法是Mask R-CNN
Mask R-CNN 通过向 Faster R-CNN 添加一个分支来进行像素级分割,该分支输出一个二进制掩码,该掩码表示给定像素是否为目标对象的一部分:该分支是基于卷积神经网络特征映射的全卷积网络。将给定的卷积神经网络特征映射作为输入,输出为一个矩阵,其中像素属于该对象的所有位置用 1 表示,其他位置则用 0 表示,这就是二进制掩码。
一旦生成这些掩码, Mask R-CNN 将 RoIAlign 与来自 Faster R-CNN 的分类和边界框相结合,以便进行精确的分割:
5、Panoramic segmentation(全景分割)
全景分割是语义分割和实例分割的结合。跟实例分割不同的是:实例分割只对图像中的object进行检测,并对检测到的object进行分割,而全景分割是对图中的所有物体包括背景都要进行检测和分割。

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









