






Fast R-CNN改进
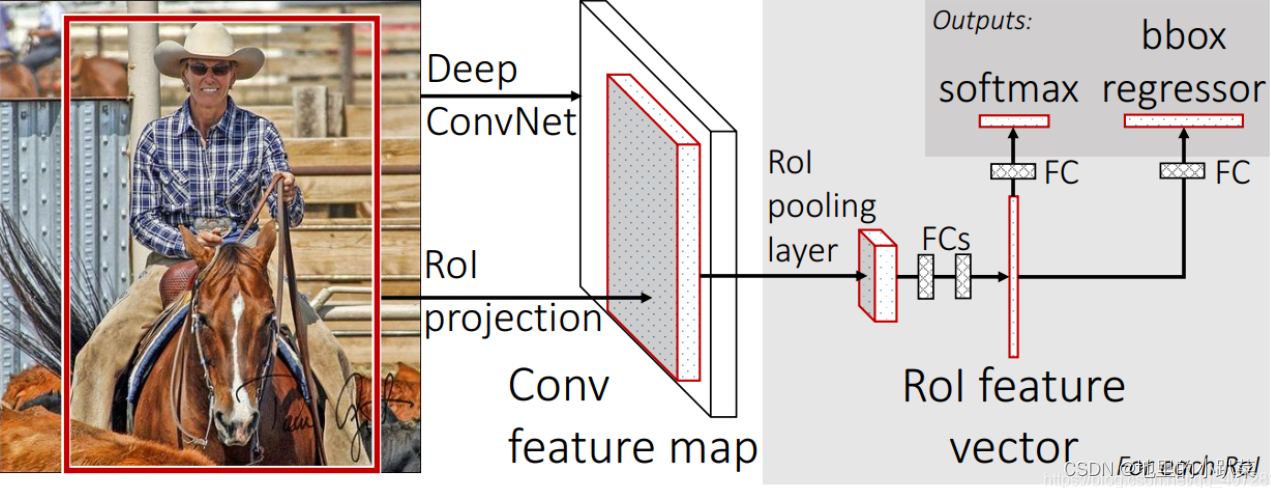
上图为论文中的图片
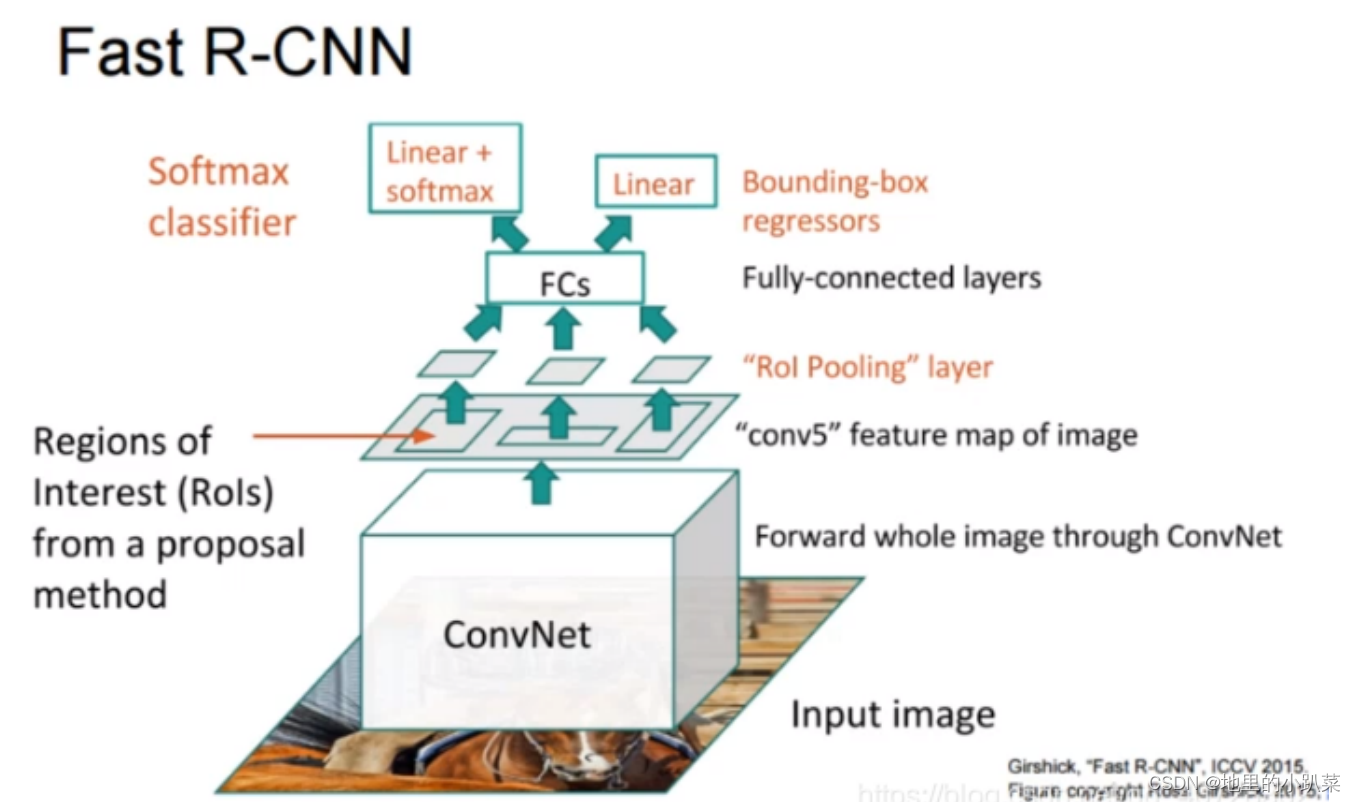 先使用CNN网络获得整体的特征图:这里可以卷积共享,加快速度
先使用CNN网络获得整体的特征图:这里可以卷积共享,加快速度
然后将原图中的Region Proposals(区域)映射到Feature Map中,获得一系 列RoI(感兴趣区域)
然后不再对每个RoI分别进行分类回归,而是通过类似SPP的RoI Pooling层 将不同大小的RoI汇集成相同大小,这样就可以用全连接层了,最后做分类回归
Fast R-CNN实现了end to end 模式(除了使用Selective Search搜索RoI)
端到端:除了输入和输出,所有中间计算都在神经网络中完成
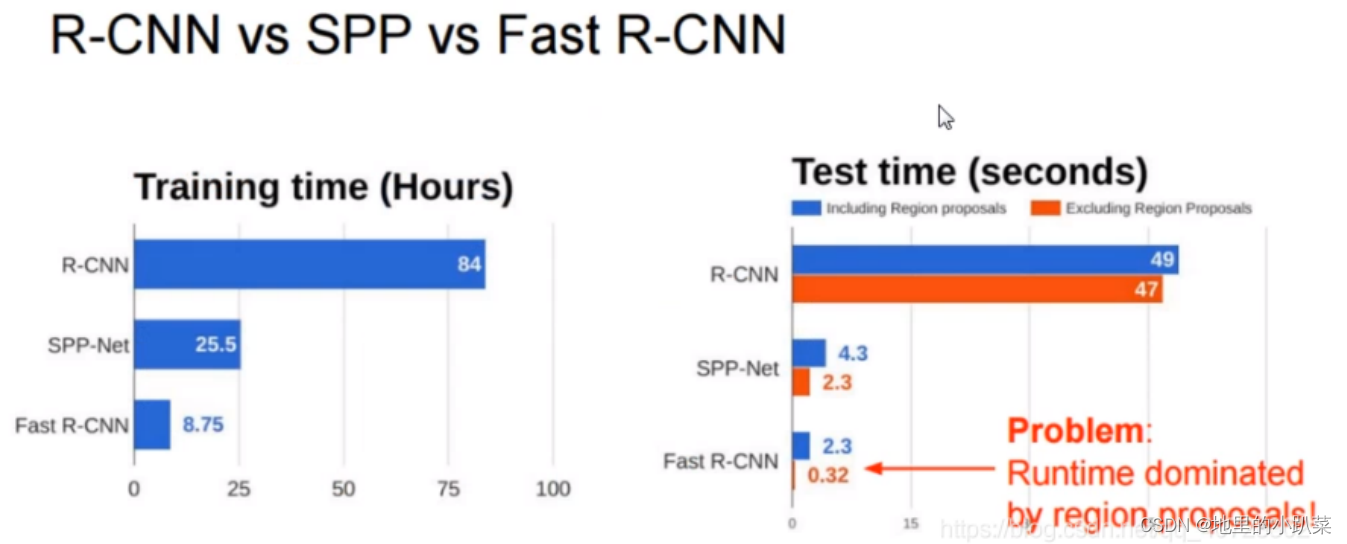
图为几种网络训练耗时和测试耗时对比图 ,显然,卷积共享的确能大幅降 低时耗
从Test time中可以看出,寻找Region Proposals是另一个秒级别的时耗
Faster R-CNN 的三个组成部分思路包括:
1)基础特征提取网络
ResNet,IncRes V2,ResNeXt 都是显著超越 VGG 的特征网络,当然网络的改进带来的是计算量的增加。
2)RPN
通过更准确地 RPN 方法,减少 Proposal 个数,提高准确度。
3)改进分类回归层
分类回归层的改进,包括 通过多层来提取特征 和 判别。
*@改进1:ION*
提出了两个方面的贡献:
1)Inside Net
所谓 Inside 是指在 ROI 区域之内,通过连接不同 Scale 下的 Feature Map,实现多尺度特征融合。
这里采用的是 Skip-Pooling,从 conv3-4-5-context 分别提取特征,后面会讲到。
多尺度特征 能够提升对小目标的检测精度。
2)Outside Net
所谓 Outside 是指 ROI 区域之外,也就是目标周围的 上下文(Contextual)信息。
通过添加了两个 RNN 层(修改后的 IRNN)实现上下文特征提取。 上下文信息 对于目标遮挡有比较好的适应。
来看结构图:
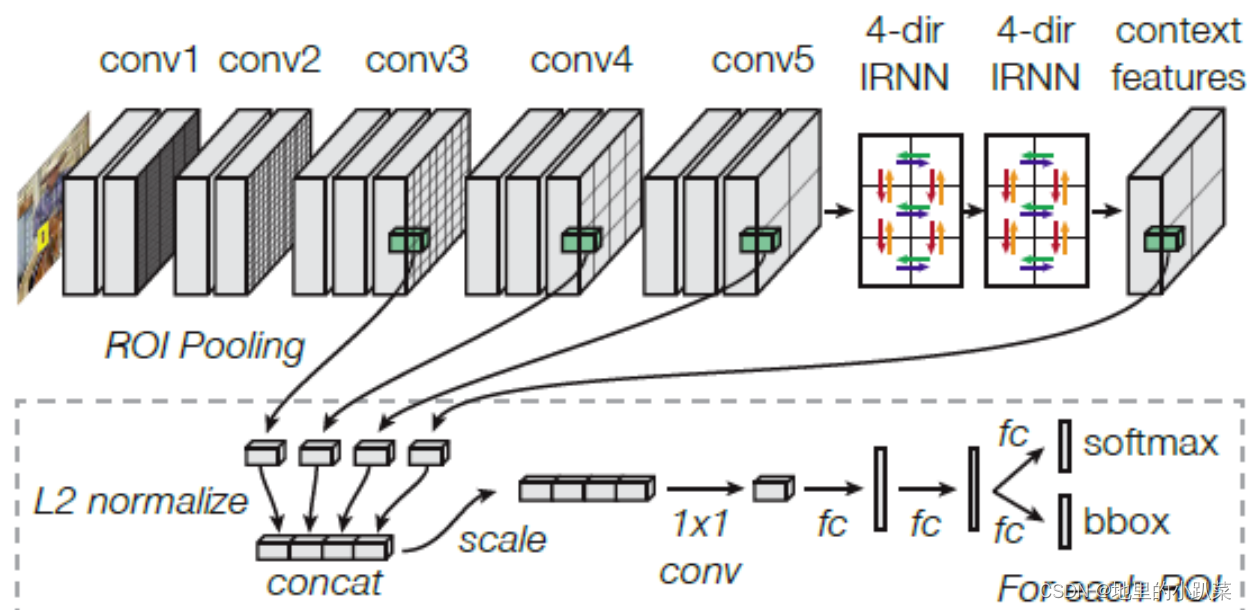
> 多尺度特征
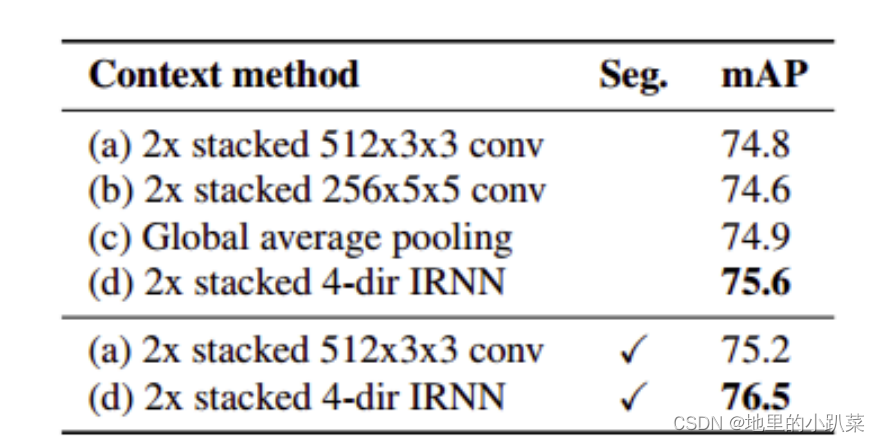
在 ROI 之后,从上图可以看到,分别从 3、4、5 层提取特征,然后再和context得到的特征做一个连接(concat),这样做的依据是什么呢?作者给出了实验验证结果:
 可以看到 Conv2 是用不到的,和我们理解的一致(尺度太大),而特征提取是 通过 L2 Norm + Scale + 1x1 Conv 得到,因为不同 Feature 之间的尺度不一致,Norm 是必须的,通过 归一化 和 Scale 进行特征提取后,送到 FC全连接层进行 分类和回归,如上图所示。
可以看到 Conv2 是用不到的,和我们理解的一致(尺度太大),而特征提取是 通过 L2 Norm + Scale + 1x1 Conv 得到,因为不同 Feature 之间的尺度不一致,Norm 是必须的,通过 归一化 和 Scale 进行特征提取后,送到 FC全连接层进行 分类和回归,如上图所示。
> Contextual 上下文
和前面的多尺度的思路一样,上下文也不是一个新的概念,生成上下文信息有很多种方法,来看下对比示意:
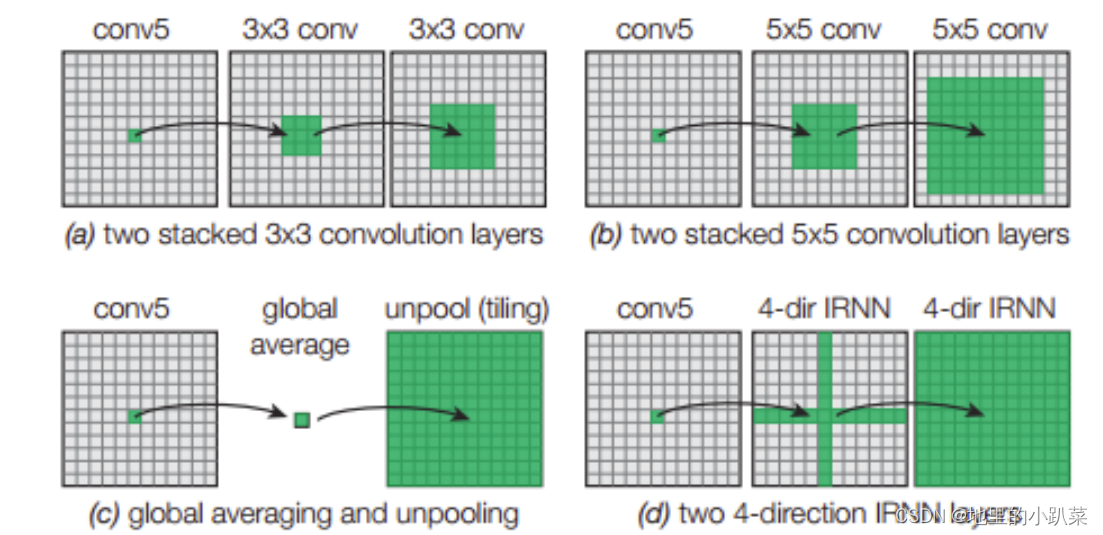
文中用的是 多维的概念,上图(d)(4-dir),如下图所示:
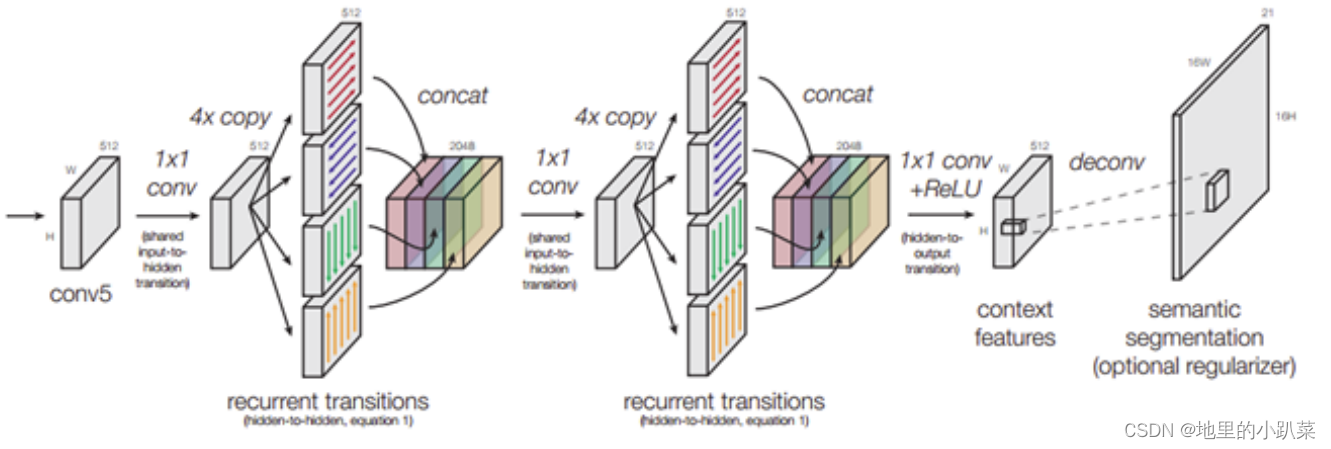
与传统的双向 RNN 不同,文中 通过上下左右四个方向,并且通过两次 IRNN 来增加非线性,更加有效的结合全局信息,看实验效果:
*@改进2:多尺度之 HyperNet*
基于 Region Proposal 的方法,通过多尺度的特征提取来提高对小目标的检测能力,来看网络框图:
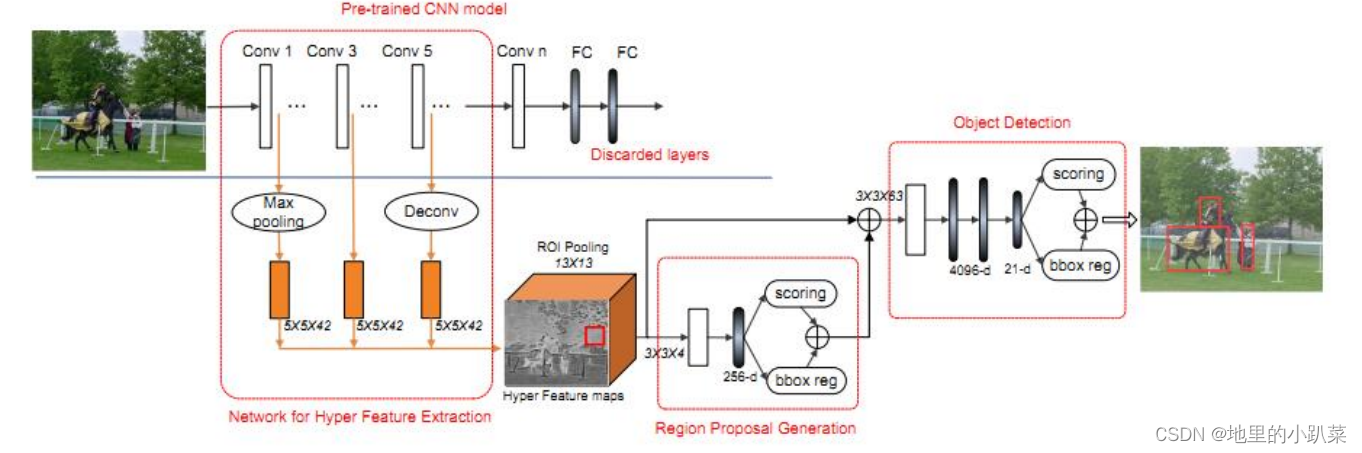
分为 三个主要特征 来介绍(对应上面网络拓扑图的 *三个红色框*):
1)Hyper Feature Extraction (特征提取)
多尺度特征提取是本文的核心点,作者的方法稍微有所不同,他是以中间的 Feature 尺度为参考,前面的层通过 Max Pooling 到对应大小,后面的层则是通过 反卷积(Deconv)进行放大。
多尺度 Feature ConCat 的时候,作者使用了 LRN进行归一化(类似于 ION 的 L2 Norm)。
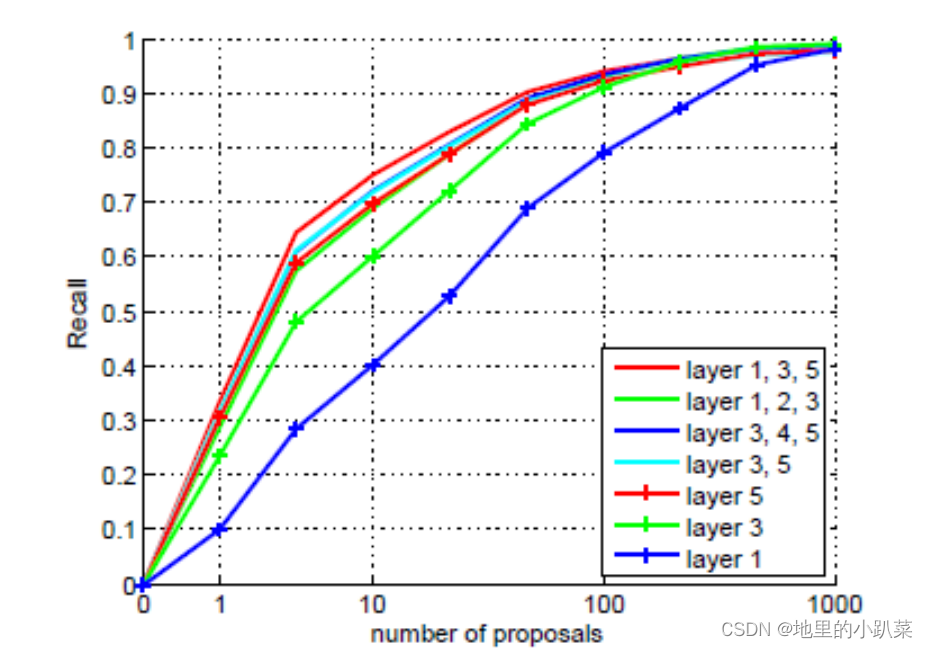
抛开具体方法不表,对小目标检测来讲,这种多尺度的特征提取已经算是标配,下图证明采用 1、3、5 的效果要更优(层间隔大,关联性小)。
2)Region Proposal Generation(建议框生成)
设计了一个轻量级的 ConvNet,与 RPN 的区别不大(为写论文强创新^_^)。
一个 ROI Pooling层,一个 Conv 层,还有一个 FC 层。每个 Position 通过 ROI Pooling 得到一个 13*13 的 bin,通过 Conv(3*3*4)层得到一个 13*13*4 的 Cube,再通过 FC 层得到一个 256d 的向量。
后面的 Score+ BBox_Reg 与 Faster并无区别,用于目标得分 和 Location OffSet。
考虑到建议框的 Overlap,作者用了 Greedy NMS 去重,文中将 IOU参考设为 0.7,每个 Image 保留 1k 个 Region,并选择其中 Top-200 做
Detetcion。
通过对比,要优于基于 Edge Box 重排序的 Deep Box,从多尺度上考虑比 Deep Proposal 效果更好。
3)Object Detection(目标检测)
与 Fast RCNN基本一致,在原来的检测网络基础上做了两点改进:
a)在 FC 层之前添加了一个 卷积层(3*3*63),对特征有效降维;
b)将 DropOut 从 0.5 降到 0.25;
另外,与 Proposal一样采用了 NMS 进行 Box抑制,但由于之前已经做了,这一步的意义不大。
训练过程
采用了 联合训练(joint training)的方法,首先对 Proposal 和Detection 分别训练,固定一个训练另一个,然后 joint 训练,即共享前面的卷积层训练一遍,具体可以参考原文给出的训练流程(这里不再赘述)。
效率改进
算法整体上和 Faster 运行效率相当,因为加入了多尺度的过程,理论上要比 Faster要慢,作者提出了提高效率的改进方法,将 Conv 层放在 ROI
Pooling 层之前,如下图所示:

实验效果对比
通过对比可以看到 mAP 比 Faster 提高了 1%,主要是多尺度的功劳,其他可以忽略,这一点需要正视。

*@改进3:多尺度之 MSCNN*
论文首先给出了不同的多尺度方法(参考下图讲解):

a)原图缩放,多个Scale的原图对应不同Scale的Feature;
该方法计算多次Scale,每个Scale提取一次Feature,计算量巨大。
b)一幅输入图像对应多个分类器;
不需要重复提取特征图,但对分类器要求很高,一般很难得到理想的结果。
c)原图缩放,少量Scale原图->少量特征图->多个Model模板;
相当于对 a)和 b)的 Trade-Off。
d)原图缩放,少量Scale原图->少量特征图->特征图插值->1个Model;
e)RCNN方法,Proposal直接给到CNN;
和 a)全图计算不同,只针对Patch计算。
f)RPN方法,特征图是通过CNN卷积层得到;
和 b)类似,不过采用的是同尺度的不同模板,容易导致尺度不一致问题。
g)上套路,提出我们自己的方法,多尺度特征图;
每个尺度特征图对应一个 输出模板,每个尺度cover一个目标尺寸范围。
> 拓扑图
套路先抛到一边,原理很简单,结合拓扑图(基于VGG的网络)来看:
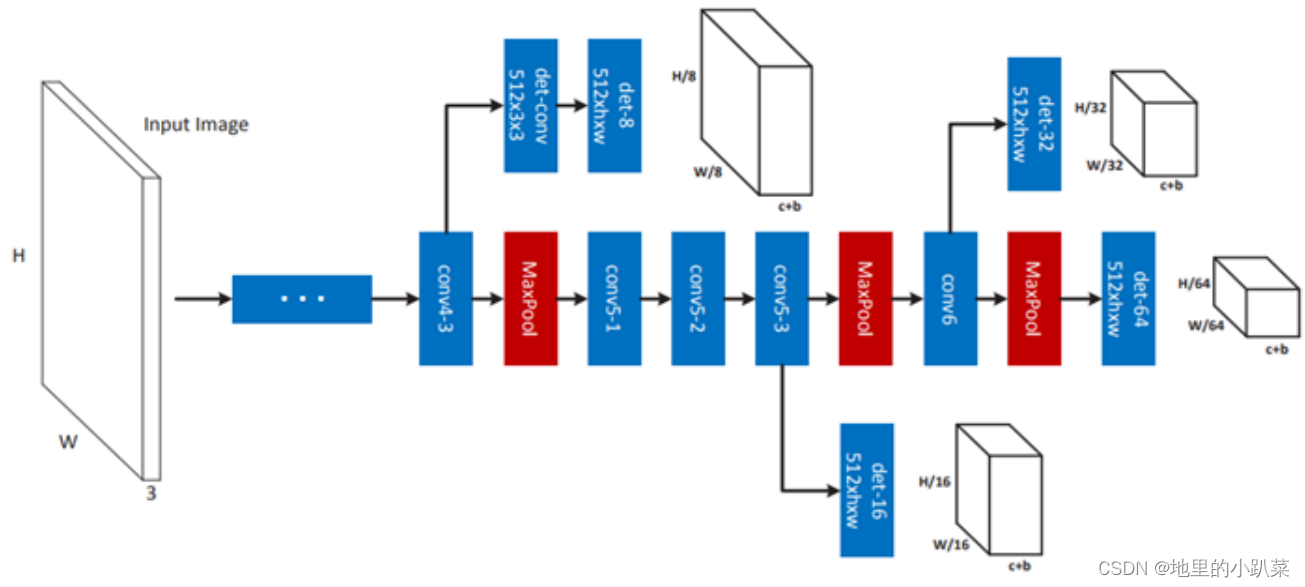
上面是提供 多尺度 Proposal 的子图,黑色 Cube 是网络输出,其中 h*w 表示 filter尺寸,c是分类类别,b是Box坐标。
通过在不同的 Conv Layer 进行输出(conv4-3,conv5-3,conv6),对应不同尺度的 det 检测器,得到4个Branch Output。
PS:作者提到,conv4-3 Branch比价靠近Bottom,梯度影响会比后面的 Branch要大,因此多加入了一个缓冲层。
> Loss函数
再来看 Loss 函数,对于 训练样本 Si =(Xi,Yi),其中 Xi 表示输入图像,Yi={yi,bi}表示 类别标签+Box位置,M代表不同的Branch,训练样本S按照尺度划分到不同的Brach,每个Branch权值不同,用a来表示。















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









