







 本文介绍了如何在Java环境下创建一个简单的基于内容的搜索引擎。首先,通过爬虫获取数据并提取有用信息存储到数据库。搜索引擎根据用户输入的关键词计算文档得分,主要包括词频、位置和距离三个维度。虽然已实现基本功能,但仍有改进空间,如自然语言处理和多词匹配等。
本文介绍了如何在Java环境下创建一个简单的基于内容的搜索引擎。首先,通过爬虫获取数据并提取有用信息存储到数据库。搜索引擎根据用户输入的关键词计算文档得分,主要包括词频、位置和距离三个维度。虽然已实现基本功能,但仍有改进空间,如自然语言处理和多词匹配等。
相信很多人都了解过搜索引擎吧,由于之前做校园新闻应用的时候爬下来很多数据,感觉很适合加个检索功能,所以看了看《集体智慧编程》的相关章节,自己动手实践一下。写新闻爬虫的时候用的自然语言处理java库,解析用户输入查询语句的时候也可以用上,所以把书里python代码改成java,写了基于内容的搜索引擎(画外音:其实你就是个搬砖工,别往脸上贴金了!)。这里想给大家分享一下制作过程和结果,希望同样感兴趣的童鞋不吝赐教!
什么是搜索引擎呢,大概意思就是在数据库里记录了一堆item和对应的属性,客户端与数据库交互,每次交互,机器通过一系列算法,计算出item的得分,根据这些得分给item排序,得分越高的item越符合用户需求,然后再返回结果列表到客户端。
基于内容的搜索引擎则是,根据对用户输入的关键词和数据库item的属性信息,来计算item的得分。 我目前只实现了三种最原始的计算item(也就是下面说的文档)得分的方法:统计关键词的词频,在文档中的位置,在文档中的距离。除了这些信息,后续对搜索引擎的研究还可以引进了很多其他属性,比如网页文档内部链接的数量和质量等。
本文主要是讲解如何在java环境下实践基于内容的搜索引擎,架构比较简单,分为两步:
- 后台数据库
- 搜索引擎
1、创建后台数据库
经过爬虫得到的原始文件,其中内容并不全是我们想要的,需要提取有用信息,并存储到数据库管理系统,方便存取。基于内容的搜索引擎只需要保存文档资源位置(url),文档中的词,词在文档中的位置。因此可以做出数据库的ER图:
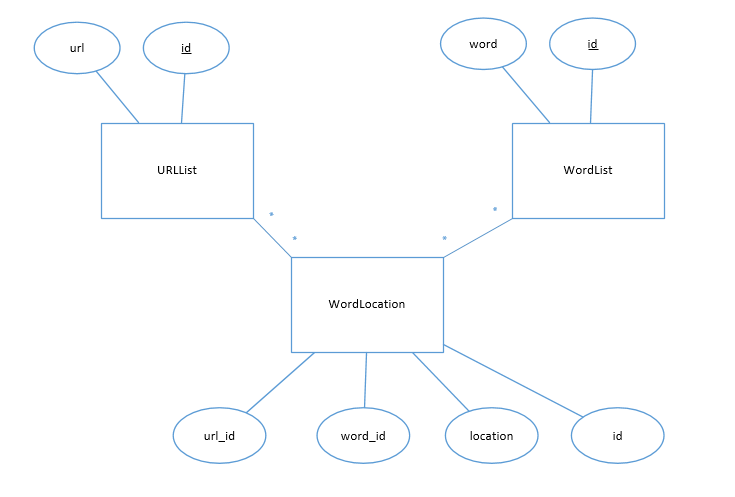
URLlist和WordLocation,WordList和WordLocation,都是一对多的关系,一篇文档可以有很多词,一个词可以出现在多篇文档中,也可以出现在文档中的多个地方。
从原始文件获得以上数据,下面结合包类结构图来分析。
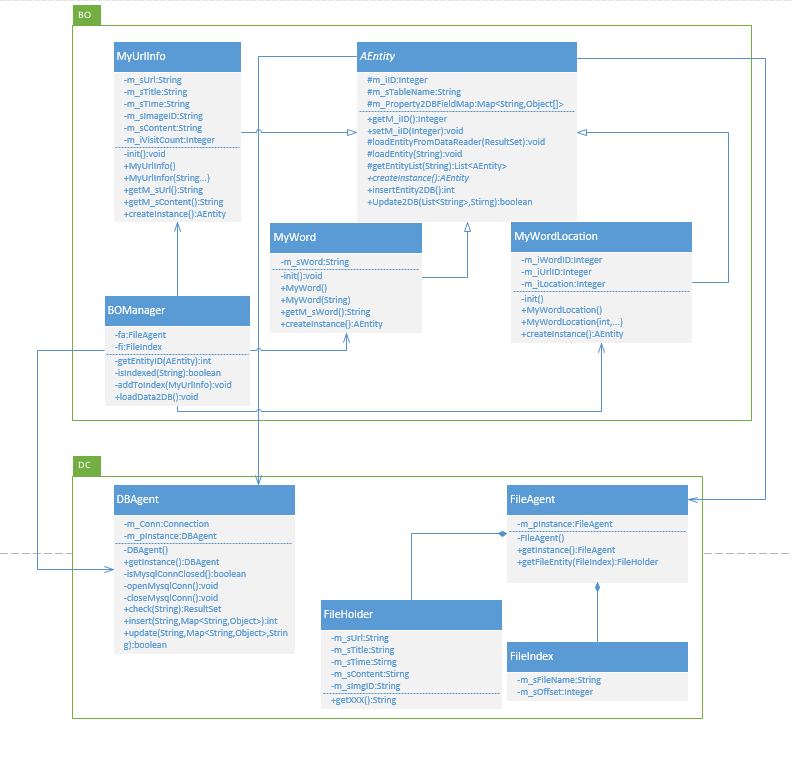
BO层实体与DC层的数据交互的结构已经提到过了(java实现起来需要使用 反射机制,感兴趣的童鞋可以点击查看)这回主要讲解BO层业务处理核心BOManager类的一些方法:
- isIndexed(String):boolean
- addToIndex(MyUrlInfo):void
- loadData2DB():void
//遍历读取原始文件,调用addToIndex建立索引
public void loadData2DB()
{
//原始文件所在文件夹在本地的位置
File file0 = new File(FilePathStaticString.originFilePath+"\\");
String[] inFile = file0.list();
for(int i=0;i<inFile.length;i++)
{
fi.filename = inFile[i];
//遍历文件夹,其中某个文件在本地的位置
File file = new File(FilePathStaticString.originFilePath+"\\"+fi.filename);
fi.j = Integer.valueOf(0);
while(file.length()!=fi.j)
{
//用文件代理获取一条新闻的信息实体
FileHolder ent = fa.getFileEntity(fi);
//为了让BO层和DC层尽量解耦,设计FileHolder作为信息实体的容器
MyUrlInfo urlinfo = new MyUrlInfo(ent.getUrl(),ent.getTime(),ent.getTitle(),ent.getImgID(),ent.getContent(),0);
//建立数据库
addToIndex(urlinfo);
}
}
}
//将文档中的文本分词,
//给url和word建立联系索引
private void addToIndex(MyUrlInfo urlInfo)
{
//检验是否已经记录了文档和词的位置关系,如果已经建立,则跳过
if(isIndexed(urlInfo.getM_sUrl()))
return;
//如果没有建立,则为他们建立关系的索引
//需要先查找数据库是否存在此Entity记录,如果存在则返回其ID
//如果不存在,则插入Entity并返回其ID
int urlid = getEntityID(urlInfo);
//自然语言处理:分词
List<String> words = fa.getSeperateWord(urlInfo.getM_sContent());
MyWordLocation wl = new MyWordLocation();
int i=0;
for(String word : words)
{
i++;
int wordid = getEntityID(new MyWord(word));
wl.setM_iUrlID(urlid);
wl.setM_iWordID(wordid);
wl.setM_iLocation(i);
wl.InsertEntity2DB();
}
}
//判断是否url是否已经存入数据库,否,返回false
//判断url是否与word有索引,否,返回false
//返回true
private boolean isIndexed(String url)
{
String sql ="";
sql = "select * from urllist where url = '"+url+"'";
MyUrlInfo urlinfo = new MyUrlInfo();
urlinfo.LoadEntity(sql);
//如果数据库没有此记录,则得到实体结果的id则为空
if(urlinfo.getM_iID()!=null)
{
int urlid = urlinfo.getM_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3624
3624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









