









文章目录
概述
首先通过一张表格对几种误差的名称有一个了解
| 简称(中文) | 英文全称 |
|---|---|
| SSE(残差平方和、和方差) | The sum of squares due to error |
| MSE(均方差、方差) | Mean squared error |
| RMSE(均方根、标准差) | Root mean squared error |
| RMS(均方根值) | Root mean squared |
| MAE(平均绝对误差) | mean absolute error |
| SSR(回归平方和) | Sum of squares of the regression |
| SST(总偏差平方和) | Total sum of squares |
| R-squared(确定系数) | Coefficient of determination |
| Adjusted R-squared(调整R方) | Degree of freedom adjusted coefficient of determination |
1. SSE
SSE(残差平方和、和方差):The sum of squares due to error
该统计参数计算的是拟合数据和原始数据对应点的误差的平方和,计算公式如下
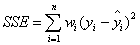
SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。接下来的MSE和RMSE因为和SSE是同出一宗,所以效果一样
2. MSE
MSE(均方差、方差):Mean squared error
该统计参数是预测数据和原始数据对应点误差的平方和的均值,也就是SSE/n,和SSE没有太大的区别,计算公式如下
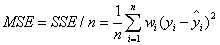
3. RMSE
RMSE(均方根、标准差):Root mean squared error
RMSE也叫回归系统的拟合标准差,是MSE的平方根;和MSE相比,RMSE能够避免出现量纲问题就算公式如下
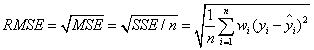
这里在介绍一下 RMS(均方根值)
RMS只是将RMSE中的残差替换成了具体要统计的变量值,和误差的计算关系不大。公式如下:
X r m s = ∑ i = 1 N X i N N = X 1 2 + X 2 2 + . . . + X N 2 N X_{rms} = \sqrt{ \frac{\sum_{i=1}^{N} X_{i}^{N}} {N}} = \sqrt{\frac{X_{1}^{2} +X_{2}^{2}+ ...+X_{N}^{2}} {N}} Xrms=N∑i=1NXiN=NX12+X22+...+XN2
4. MAE
MAE(平均绝对误差):mean absolute error
MAE是绝对误差的平均值,RMSE 与 MAE 的量纲相同,但求出结果后我们会发现RMSE比MAE的要大一些;这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大了较大误差之间的差距。
而MAE反应的就是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。
公式如下:
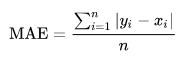
5. R-squared
R-squared(确定系数):Coefficient of determination
R²是一个相对度量,本质上是在基准模型残差和的标准下度量现有模型的残差和,;我们一般使用均值预测作为基准模型;我们也可以使用它来与在相同数据上训练的其他模型进行比较,并用它来大致了解一个模型的相对性能,只需将公式中的SST换做其他模型得到的残差和即可)。
在讲确定系数之前,我们需要介绍另外两个参数SSR和SST,因为确定系数就是由它们两个决定的
(1)SSR(回归平方和):Sum of squares of the regression,即预测数据与原始数据均值之差的平方和,公式如下
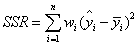
(2)SST(总偏差平方和,样本方差):Total sum of squares,偏差=实际值一标准值,通常用平均值代替标准值;在这里表示原始数据和均值之差的平方和,公式如下
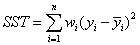
通过观察可以发现,SST=SSE+SSR。而我们的“确定系数”是定义为SSR和SST的比值,故
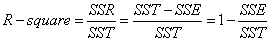
等价形式:
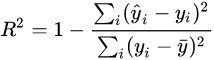
下边通过分析公式 1-SSE/SST 来理解R-squared的具体含义
- 上述公式中分子表示使用预测值预测的残差;分母表示使用样本均值预测所有数据得到的残差
- 当 R-squared <0 时 ,表示模型预测的结果的残差比基准模型(用样本均值预测所有数据)得到的残差还要大,表示模型预测结果非常差
- 当 R-squared >0 时 R-squared越大SSE越小,表示模型预测结果的残差越小,预测效果越好
- SST表示基准模型预测结果得到的残差,一般用样本均值预测所有数据作为基准模型,如果有要对比分析的基准模型,则可以将均值替换
6. Adjusted R-squared
Adjusted R-squared(调整R方) Degree of freedom adjusted coefficient of determination
R
2
(
a
d
j
)
=
1
−
(
R
S
S
/
(
n
−
p
−
1
)
)
/
(
T
S
S
/
(
n
−
1
)
)
\\ R^2 (adj) = 1- (RSS/(n-p-1))/(TSS/(n-1))
R2(adj)=1−(RSS/(n−p−1))/(TSS/(n−1))
(p 为变量个数,n 为样本个数)
R-squared(值范围0-1)描述的 输入变量对输出变量的解释程度。在单变量线性回归中R-squared 越大,说明拟合程度越好。
然而只要曾加了更多的变量,无论增加的变量是否和输出变量存在关系,则R-squared 要么保持不变,要么增加。
So, 需要adjusted R-squared ,它会对那些增加的且不会改善模型效果的变量增加一个惩罚向。
结论,如果单变量线性回归,则使用 R-squared评估,多变量,则使用adjusted R-squared。
在单变量线性回归中,R-squared和adjusted R-squared是一致的。
另外,如果增加更多无意义的变量,则R-squared 和adjusted R-squared之间的差距会越来越大,Adjusted R-squared会下降。但是如果加入的特征值是显著的,则adjusted R-squared也会上升
7 对比 MAE、MSE、RMSE、R-square、Adjusted R-squared
MSE、RMSE本质上都是计算偏差的L2范数,两者都会方法较大的误差,因此可能会使模型牺牲正常样本的偏差,从而去拟合异常值;但RMSE保持了和样本同量纲,MSE计算简便。
MAE能够保持和样本数据同量纲,但是MAE在对参数求导时,每次得到的梯度相同,不会随着损失的减小而减小,从而降低模型的收敛速度和精度,对于线性回归y=ax+b来说,损失函数为|ax+b-y| 对a求偏导为 x,优化过程中x不变,因此每次求解的梯度也不会发生改变;在使用MAE做损失函数时,一般设定可变学习率来动态调整参数更新值的大小。
在回归模型中,损失函数一般使用 MAE、MSE、RMSE,而性能评估指标常用R-square;对于一个回归模型,如果对于每一个观测数据都用观测数据均值多为预测值,似乎也能达到很高的准确率,为了避免这种模型作弊问题,R-square用模型预测偏差的方差与拿观测值均值预测的方差的比值作为评价标准,当R-square=1是表示模型所有的预测值都和观测值相同,R-square=1表示模型预测性能和拿均值预测的性能相同,R-square<0表示模型预测的性能还不如拿均值预测的性能强,总结来说R-square就是在用均值预测的标准下衡量模型的预测性能
Adjusted R-squared 和 R-squared类似,只是在 R-squared 的同时对参数增加了一个L0损失,在最大化R-squared的同时最小化参数个数
想进一步了解深度学习中优化器的深度解析请移步->#深度解析# 深度学习中的SGD、BGD、MBGD、Momentum、NAG、Adagrad、Adadelta,RMSprop、Adam优化器
参考文章:
















 7861
7861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











