







目录
一.子集(一)
1)题目描述
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例: 输入: nums = [1,2,3] 输出: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]
2)思路
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始 ;
什么时候for可以从0开始呢?
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
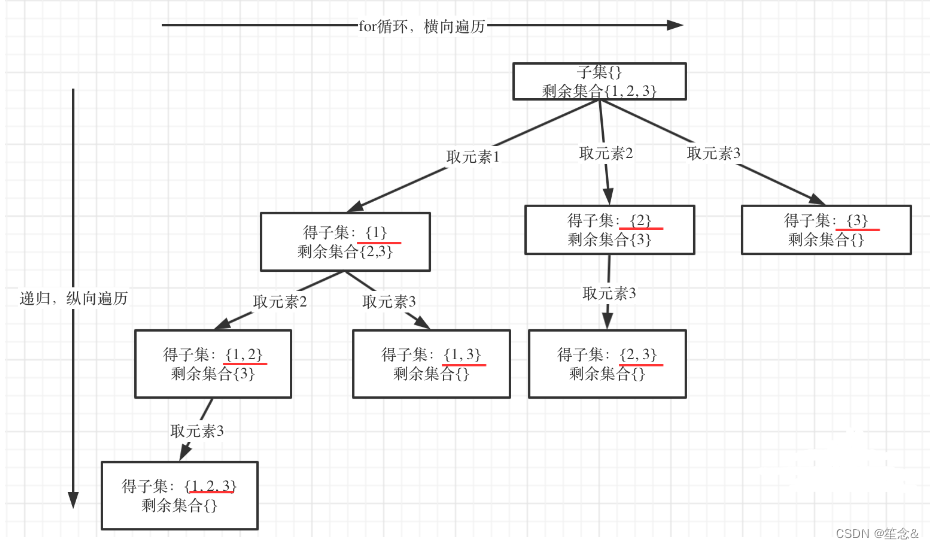
可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合
3)回溯三部曲
- 递归函数参数
全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里)
递归函数参数在上面讲到了,需要startIndex。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {递归终止条件
从图中可以看出:
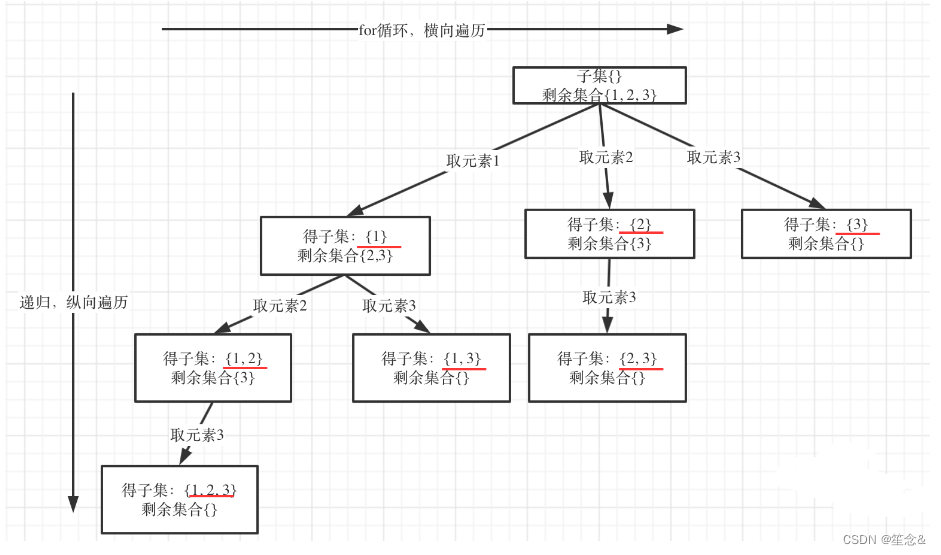
剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
if (startIndex >= nums.size()) {
return;
}
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
- 单层搜索逻辑
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
那么单层递归逻辑代码如下:
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]); // 子集收集元素
backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取
path.pop_back(); // 回溯
}4)代码
int* path;
int pathTop;
int** ans;
int ansTop;
//记录二维数组中每个一维数组的长度
int* length;
//将当前path数组复制到ans中
void copy() {
int* tempPath = (int*)malloc(sizeof(int) * pathTop);
int i;
for(i = 0; i < pathTop; i++) {
tempPath[i] = path[i];
}
ans = (int**)realloc(ans, sizeof(int*) * (ansTop+1));
length[ansTop] = pathTop;
ans[ansTop++] = tempPath;
}
void backTracking(int* nums, int numsSize, int startIndex) {
//收集子集,要放在终止添加的上面,否则会漏掉自己
copy();
//若startIndex大于数组大小,返回
if(startIndex >= numsSize) {
return;
}
int j;
for(j = startIndex; j < numsSize; j++) {
//将当前下标数字放入path中
path[pathTop++] = nums[j];
backTracking(nums, numsSize, j+1);
//回溯
pathTop--;
}
}
int** subsets(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
//初始化辅助变量
path = (int*)malloc(sizeof(int) * numsSize);
ans = (int**)malloc(0);
length = (int*)malloc(sizeof(int) * 1500);
ansTop = pathTop = 0;
//进入回溯
backTracking(nums, numsSize, 0);
//设置二维数组中元素个数
*returnSize = ansTop;
//设置二维数组中每个一维数组的长度
*returnColumnSizes = (int*)malloc(sizeof(int) * ansTop);
int i;
for(i = 0; i < ansTop; i++) {
(*returnColumnSizes)[i] = length[i];
}
return ans;
}二.子集(二)
1)题目描述
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
- 输入: [1,2,2]
- 输出: [ [2], [1], [1,2,2], [2,2], [1,2], [] ]
2)思路
这道题目和子集(一)区别就是集合里有重复元素了,而且求取的子集要去重。
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)
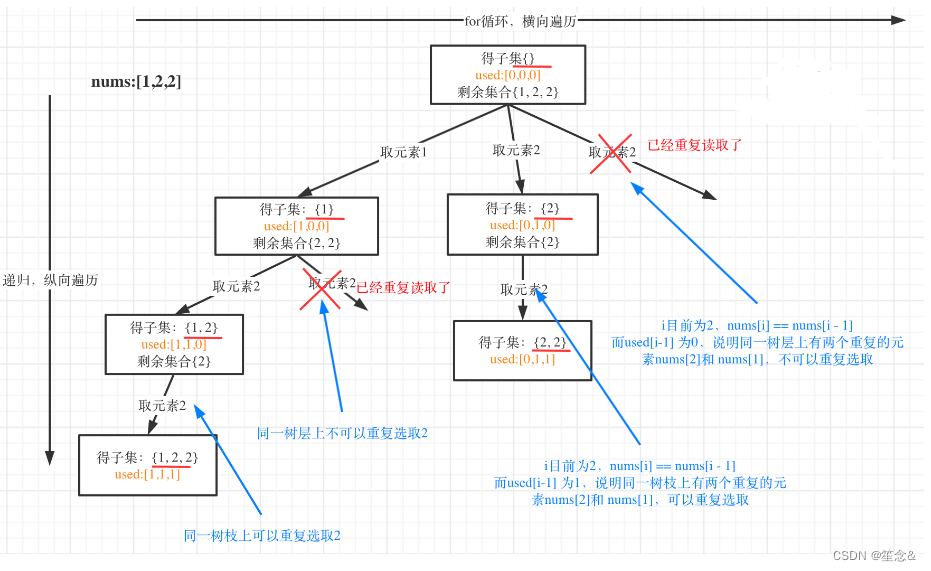
同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
去重在组合问题中讲过,就不再讲咯---》回溯算法(一)组合问题
3)代码
int* path;
int pathTop;
int** ans;
int ansTop;
//负责存放二维数组中每个数组的长度
int* lengths;
//快排cmp函数
int cmp(const void* a, const void* b) {
return *((int*)a) - *((int*)b);
}
//复制函数,将当前path中的元素复制到ans中。同时记录path长度
void copy() {
int* tempPath = (int*)malloc(sizeof(int) * pathTop);
int i;
for(i = 0; i < pathTop; i++) {
tempPath[i] = path[i];
}
ans = (int**)realloc(ans, sizeof(int*) * (ansTop + 1));
lengths[ansTop] = pathTop;
ans[ansTop++] = tempPath;
}
void backTracking(int* nums, int numsSize, int startIndex, int* used) {
//首先将当前path复制
copy();
//若startIndex大于数组最后一位元素的位置,返回
if(startIndex >= numsSize)
return ;
int i;
for(i = startIndex; i < numsSize; i++) {
//对同一树层使用过的元素进行跳过
if(i > 0 && nums[i] == nums[i-1] && used[i-1] == false)
continue;
path[pathTop++] = nums[i];
used[i] = true;
backTracking(nums, numsSize, i + 1, used);
used[i] = false;
pathTop--;
}
}
int** subsetsWithDup(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
//声明辅助变量
path = (int*)malloc(sizeof(int) * numsSize);
ans = (int**)malloc(0);
lengths = (int*)malloc(sizeof(int) * 1500);
int* used = (int*)malloc(sizeof(int) * numsSize);
pathTop = ansTop = 0;
//排序后查重才能生效
qsort(nums, numsSize, sizeof(int), cmp);
backTracking(nums, numsSize, 0, used);
//设置一维数组和二维数组的返回大小
*returnSize = ansTop;
*returnColumnSizes = (int*)malloc(sizeof(int) * ansTop);
int i;
for(i = 0; i < ansTop; i++) {
(*returnColumnSizes)[i] = lengths[i];
}
return ans;
}三.递增子序列
1)题目描述
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
- 输入: [4, 6, 7, 7]
- 输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
- 给定数组的长度不会超过15。
- 数组中的整数范围是 [-100,100]。
- 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
2)思路
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
又是子集,又是去重;在子集问题中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组经行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
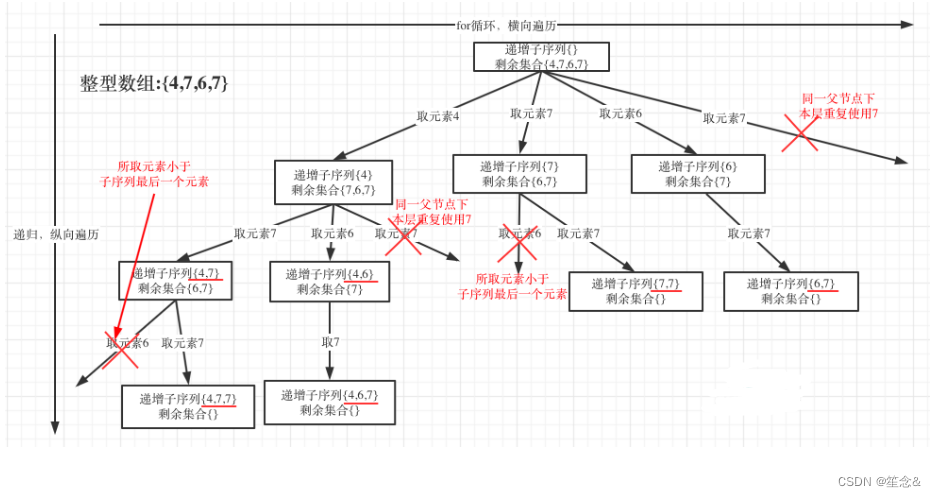
3)回溯三部曲
- 递归函数参数
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置。
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex)- 终止条件
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和求子集问题一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归。
但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,因为要取树上的所有节点
}- 单层搜索逻辑
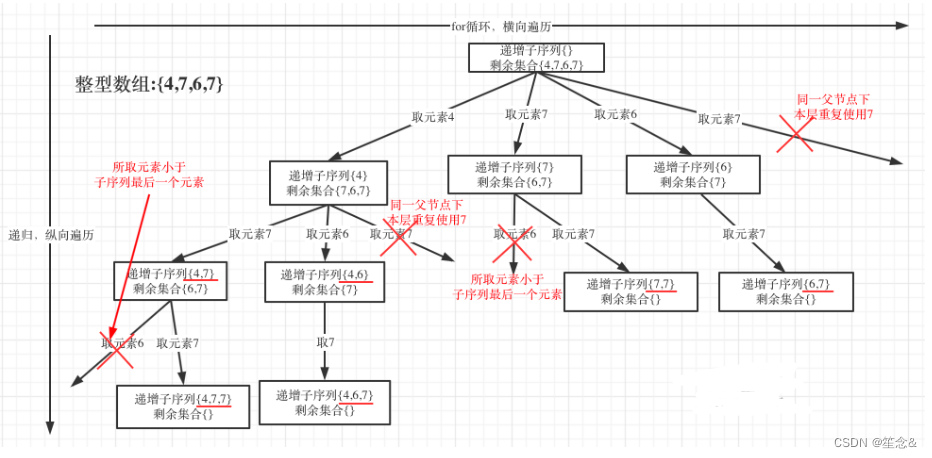
在图中可以看出,同一父节点下的同层上使用过的元素就不能在使用了
那么单层搜索代码如下:
unordered_set<int> uset; // 使用set来对本层元素进行去重
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
} 需要注意的点,unordered_set<int> uset; 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!
4)代码
int* path;
int pathTop;
int** ans;
int ansTop;
int* length;
//将当前path中的内容复制到ans中
void copy() {
int* tempPath = (int*)malloc(sizeof(int) * pathTop);
memcpy(tempPath, path, pathTop * sizeof(int));
length[ansTop] = pathTop;
ans[ansTop++] = tempPath;
}
//查找uset中是否存在值为key的元素
int find(int* uset, int usetSize, int key) {
int i;
for(i = 0; i < usetSize; i++) {
if(uset[i] == key)
return 1;
}
return 0;
}
void backTracking(int* nums, int numsSize, int startIndex) {
//当path中元素大于1个时,将path拷贝到ans中
if(pathTop > 1) {
copy();
}
int* uset = (int*)malloc(sizeof(int) * numsSize);
int usetTop = 0;
int i;
for(i = startIndex; i < numsSize; i++) {
//若当前元素小于path中最后一位元素 || 在树的同一层找到了相同的元素,则continue
if((pathTop > 0 && nums[i] < path[pathTop - 1]) || find(uset, usetTop, nums[i]))
continue;
//将当前元素放入uset
uset[usetTop++] = nums[i];
//将当前元素放入path
path[pathTop++] = nums[i];
backTracking(nums, numsSize, i + 1);
//回溯
pathTop--;
}
}
int** findSubsequences(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
//辅助数组初始化
path = (int*)malloc(sizeof(int) * numsSize);
ans = (int**)malloc(sizeof(int*) * 33000);
length = (int*)malloc(sizeof(int*) * 33000);
pathTop = ansTop = 0;
backTracking(nums, numsSize, 0);
//设置数组中返回元素个数,以及每个一维数组的长度
*returnSize = ansTop;
*returnColumnSizes = (int*)malloc(sizeof(int) * ansTop);
int i;
for(i = 0; i < ansTop; i++) {
(*returnColumnSizes)[i] = length[i];
}
return ans;
}















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









