






MMAction2官方给的基于骨骼点的动作识别数据集构建代码ntu_pose_extraction.py及其数据集构建过程说的比较简单,并且没有给出多个pickle文件合并的代码,这里为了方便,贴出这个代码。
mmpose安装参考
open-mmlab / mmpose安装、使用教程_openmmlab-CSDN博客
mmdetection安装参考
开始你的第一步 — MMDetection 3.2.0 文档
安装过程中出现ModuleNotFoundError: No module named ‘setuptools.command.build
使用如下命令解决:
python -m pip install --upgrade pip setuptools wheel官方例子提取骨骼点命令:
python ntu_pose_extraction.py some_video_from_my_dataset.mp4 some_video_from_my_dataset.pkl建立如图格式的结构,每个文件夹名是类别,每个文件夹里放对应类别的视频。

对F:\mmaction2\tools\data\skeleton\ntu_pose_extraction.py进行修改来批量提取视频的骨骼点,修改main处的文件夹路径,类别数,各类别名称即可。
代码如下:
# Copyright (c) OpenMMLab. All rights reserved.
import abc
import argparse
import os
import os.path as osp
from collections import defaultdict
from tempfile import TemporaryDirectory
import mmengine
import numpy as np
# detection_inference
from mmaction.apis import pose_inference
from mmaction.utils import frame_extract
from pathlib import Path
from typing import List, Optional, Union
import mmengine
import numpy as np
import torch
import torch.nn as nn
from mmengine.utils import track_iter_progress
args = abc.abstractproperty()
args.det_config = 'D:/mmaction2/mmaction2-main/demo/demo_configs/faster-rcnn_r50-caffe_fpn_ms-1x_coco-person.py' # noqa: E501
args.det_checkpoint = 'https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth' # noqa: E501
args.det_score_thr = 0.5
args.pose_config = 'D:/mmaction2/mmaction2-main/demo/demo_configs/td-hm_hrnet-w32_8xb64-210e_coco-256x192_infer.py' # noqa: E501
args.pose_checkpoint = 'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth' # noqa: E501
def intersection(b0, b1):
l, r = max(b0[0], b1[0]), min(b0[2], b1[2])
u, d = max(b0[1], b1[1]), min(b0[3], b1[3])
return max(0, r - l) * max(0, d - u)
def iou(b0, b1):
i = intersection(b0, b1)
u = area(b0) + area(b1) - i
return i / u
def area(b):
return (b[2] - b[0]) * (b[3] - b[1])
def removedup(bbox):
def inside(box0, box1, threshold=0.8):
return intersection(box0, box1) / area(box0) > threshold
num_bboxes = bbox.shape[0]
if num_bboxes == 1 or num_bboxes == 0:
return bbox
valid = []
for i in range(num_bboxes):
flag = True
for j in range(num_bboxes):
if i != j and inside(bbox[i],
bbox[j]) and bbox[i][4] <= bbox[j][4]:
flag = False
break
if flag:
valid.append(i)
return bbox[valid]
def is_easy_example(det_results, num_person):
threshold = 0.95
def thre_bbox(bboxes, threshold=threshold):
shape = [sum(bbox[:, -1] > threshold) for bbox in bboxes]
ret = np.all(np.array(shape) == shape[0])
return shape[0] if ret else -1
if thre_bbox(det_results) == num_person:
det_results = [x[x[..., -1] > 0.95] for x in det_results]
return True, np.stack(det_results)
return False, thre_bbox(det_results)
def bbox2tracklet(bbox):
iou_thre = 0.6
tracklet_id = -1
tracklet_st_frame = {}
tracklets = defaultdict(list)
for t, box in enumerate(bbox):
for idx in range(box.shape[0]):
# for idx in range(1):
matched = False
for tlet_id in range(tracklet_id, -1, -1):
cond1 = iou(tracklets[tlet_id][-1][-1], box[idx]) >= iou_thre
cond2 = (
t - tracklet_st_frame[tlet_id] - len(tracklets[tlet_id]) <
10)
cond3 = tracklets[tlet_id][-1][0] != t
if cond1 and cond2 and cond3:
matched = True
tracklets[tlet_id].append((t, box[idx]))
break
if not matched:
tracklet_id += 1
tracklet_st_frame[tracklet_id] = t
tracklets[tracklet_id].append((t, box[idx]))
return tracklets
def drop_tracklet(tracklet):
tracklet = {k: v for k, v in tracklet.items() if len(v) > 5}
def meanarea(track):
boxes = np.stack([x[1] for x in track]).astype(np.float32)
areas = (boxes[..., 2] - boxes[..., 0]) * (
boxes[..., 3] - boxes[..., 1])
return np.mean(areas)
tracklet = {k: v for k, v in tracklet.items() if meanarea(v) > 5000}
return tracklet
def distance_tracklet(tracklet):
dists = {}
for k, v in tracklet.items():
bboxes = np.stack([x[1] for x in v])
c_x = (bboxes[..., 2] + bboxes[..., 0]) / 2.
c_y = (bboxes[..., 3] + bboxes[..., 1]) / 2.
c_x -= 480
c_y -= 270
c = np.concatenate([c_x[..., None], c_y[..., None]], axis=1)
dist = np.linalg.norm(c, axis=1)
dists[k] = np.mean(dist)
return dists
def tracklet2bbox(track, num_frame):
# assign_prev
bbox = np.zeros((num_frame, 1, 5))
trackd = {}
for k, v in track:
bbox[k, 0] = v
trackd[k] = v
for i in range(num_frame):
if bbox[i, 0][-1] <= 0.5:
mind = np.Inf
for k in trackd:
if np.abs(k - i) < mind:
mind = np.abs(k - i)
bbox[i, 0] = bbox[k, 0]
return bbox
def tracklets2bbox(tracklet, num_frame):
dists = distance_tracklet(tracklet)
sorted_inds = sorted(dists, key=lambda x: dists[x])
dist_thre = np.Inf
for i in sorted_inds:
if len(tracklet[i]) >= num_frame / 2:
dist_thre = 2 * dists[i]
break
dist_thre = max(50, dist_thre)
bbox = np.zeros((num_frame, 5))
bboxd = {}
for idx in sorted_inds:
if dists[idx] < dist_thre:
for k, v in tracklet[idx]:
if bbox[k][-1] < 0.01:
bbox[k] = v
bboxd[k] = v
bad = 0
for idx in range(num_frame):
if bbox[idx][-1] < 0.01:
bad += 1
mind = np.Inf
mink = None
for k in bboxd:
if np.abs(k - idx) < mind:
mind = np.abs(k - idx)
mink = k
bbox[idx] = bboxd[mink]
return bad, bbox[:, None, :]
def bboxes2bbox(bbox, num_frame):
ret = np.zeros((num_frame, 2, 5))
for t, item in enumerate(bbox):
if item.shape[0] <= 2:
ret[t, :item.shape[0]] = item
else:
inds = sorted(
list(range(item.shape[0])), key=lambda x: -item[x, -1])
ret[t] = item[inds[:2]]
for t in range(num_frame):
if ret[t, 0, -1] <= 0.01:
ret[t] = ret[t - 1]
elif ret[t, 1, -1] <= 0.01:
if t:
if ret[t - 1, 0, -1] > 0.01 and ret[t - 1, 1, -1] > 0.01:
if iou(ret[t, 0], ret[t - 1, 0]) > iou(
ret[t, 0], ret[t - 1, 1]):
ret[t, 1] = ret[t - 1, 1]
else:
ret[t, 1] = ret[t - 1, 0]
return ret
def ntu_det_postproc(vid, det_results):
det_results = [removedup(x) for x in det_results]
# print(det_results)
# det_results = det_results[0]
# label = 0
# mpaction = list(range(50, 61)) + list(range(106, 121))
# n_person = 2 if label in mpaction else 1
n_person = 1
is_easy, bboxes = is_easy_example(det_results, n_person)
if is_easy:
print('\nEasy Example')
return bboxes
tracklets = bbox2tracklet(det_results)
tracklets = drop_tracklet(tracklets)
print(f'\nHard {n_person}-person Example, found {len(tracklets)} tracklet')
if n_person == 1:
if len(tracklets) == 1:
tracklet = list(tracklets.values())[0]
det_results = tracklet2bbox(tracklet, len(det_results))
return np.stack(det_results)
else:
bad, det_results = tracklets2bbox(tracklets, len(det_results))
return det_results
# n_person is 2
if len(tracklets) <= 2:
tracklets = list(tracklets.values())
bboxes = []
for tracklet in tracklets:
bboxes.append(tracklet2bbox(tracklet, len(det_results))[:, None])
bbox = np.concatenate(bboxes, axis=1)
return bbox
else:
return bboxes2bbox(det_results, len(det_results))
def pose_inference_with_align(args, frame_paths, det_results):
# filter frame without det bbox
det_results = [
frm_dets for frm_dets in det_results if frm_dets.shape[0] > 0
]
# print(det_results)
pose_results, _ = pose_inference(args.pose_config, args.pose_checkpoint,
frame_paths, det_results, args.device)
# align the num_person among frames
num_persons = max([pose['keypoints'].shape[0] for pose in pose_results])
num_points = pose_results[0]['keypoints'].shape[1]
num_frames = len(pose_results)
keypoints = np.zeros((num_persons, num_frames, num_points, 2),
dtype=np.float32)
scores = np.zeros((num_persons, num_frames, num_points), dtype=np.float32)
for f_idx, frm_pose in enumerate(pose_results):
frm_num_persons = frm_pose['keypoints'].shape[0]
for p_idx in range(frm_num_persons):
keypoints[p_idx, f_idx] = frm_pose['keypoints'][p_idx]
scores[p_idx, f_idx] = frm_pose['keypoint_scores'][p_idx]
return keypoints, scores
def detection_inference(det_config: Union[str, Path, mmengine.Config,
nn.Module],
det_checkpoint: str,
frame_paths: List[str],
det_score_thr: float = 0.9,
det_cat_id: int = 0,
device: Union[str, torch.device] = 'cuda:0',
with_score: bool = False) -> tuple:
"""Detect human boxes given frame paths.
Args:
det_config (Union[str, :obj:`Path`, :obj:`mmengine.Config`,
:obj:`torch.nn.Module`]):
Det config file path or Detection model object. It can be
a :obj:`Path`, a config object, or a module object.
det_checkpoint: Checkpoint path/url.
frame_paths (List[str]): The paths of frames to do detection inference.
det_score_thr (float): The threshold of human detection score.
Defaults to 0.9.
det_cat_id (int): The category id for human detection. Defaults to 0.
device (Union[str, torch.device]): The desired device of returned
tensor. Defaults to ``'cuda:0'``.
with_score (bool): Whether to append detection score after box.
Defaults to None.
Returns:
List[np.ndarray]: List of detected human boxes.
List[:obj:`DetDataSample`]: List of data samples, generally used
to visualize data.
"""
try:
from mmdet.apis import inference_detector, init_detector
from mmdet.structures import DetDataSample
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_detector` and '
'`init_detector` from `mmdet.apis`. These apis are '
'required in this inference api! ')
if isinstance(det_config, nn.Module):
model = det_config
else:
model = init_detector(
config=det_config, checkpoint=det_checkpoint, device=device)
results = []
data_samples = []
print('Performing Human Detection for each frame')
for frame_path in track_iter_progress(frame_paths):
det_data_sample: DetDataSample = inference_detector(model, frame_path)
pred_instance = det_data_sample.pred_instances.cpu().numpy()
bboxes = pred_instance.bboxes
scores = pred_instance.scores
# We only keep human detection bboxs with score larger
# than `det_score_thr` and category id equal to `det_cat_id`.
valid_idx = np.logical_and(pred_instance.labels == det_cat_id,
pred_instance.scores > det_score_thr)
bboxes = bboxes[valid_idx]
scores = scores[valid_idx]
# print(bboxes)
# print(scores)
if with_score:
bboxes = np.concatenate((bboxes, scores[:, None]), axis=-1)
# bboxes = np.concatenate((bboxes[0], scores[0, None]), axis=-1)
# print(bboxes)
results.append(bboxes)
data_samples.append(det_data_sample)
return results, data_samples
def ntu_pose_extraction(vid, label_no, skip_postproc=False):
tmp_dir = TemporaryDirectory()
frame_paths, _ = frame_extract(vid, out_dir=tmp_dir.name)
det_results, _ = detection_inference(
args.det_config,
args.det_checkpoint,
frame_paths,
args.det_score_thr,
device=args.device,
with_score=True)
# print(det_results)
if not skip_postproc:
det_results = ntu_det_postproc(vid, det_results)
anno = dict()
keypoints, scores = pose_inference_with_align(args, frame_paths,
det_results)
anno['keypoint'] = keypoints
anno['keypoint_score'] = scores
anno['frame_dir'] = osp.splitext(osp.basename(vid))[0]
anno['img_shape'] = (1280, 720)
anno['original_shape'] = (1280, 720)
anno['total_frames'] = keypoints.shape[1]
anno['label'] = label_no
tmp_dir.cleanup()
return anno
def parse_args():
parser = argparse.ArgumentParser(
description='Generate Pose Annotation for a single NTURGB-D video')
parser.add_argument('--device', type=str, default='cuda:0')
parser.add_argument('--skip-postproc', action='store_true')
args = parser.parse_args()
return args
if __name__ == '__main__':
work_dir = 'D:/mmaction2/mmaction2-main/tools/data/skeleton/data/assembly/longvideo' #RGB视频文件夹
type_number = 6 #类别数
action_filename_list = ['boxing','handclapping','handwaving', #类别名字
'jogging','walking']
#action_filename_list = ['problem']
for process_index in range(type_number):
action_filename = action_filename_list[process_index]
label_no = process_index
resizedvideo_file = '{}/{}'.format(work_dir, action_filename)
resizedvideos_file_names = os.listdir(resizedvideo_file)
for file_name in resizedvideos_file_names:
video_name = file_name.split('.')[0]
global_args = parse_args()
args.device = global_args.device
args.video = '{}/{}/{}.avi'.format(work_dir,action_filename, video_name)
args.output = '{}/pkl2/{}.pkl'.format(work_dir, video_name)
args.skip_postproc = global_args.skip_postproc
anno = ntu_pose_extraction(args.video, label_no, args.skip_postproc)
mmengine.dump(anno, args.output)
多个pickle文件合并的代码
import os.path as osp
import os
import pickle
result = []
path = './' #你的多个pickle文件夹路径
for d in os.listdir(path):
if d.endswith('.pkl'):
with open(osp.join(path, d), 'rb') as f:
content = pickle.load(f)
result.append(content)
with open('train.pkl', 'wb') as out:
pickle.dump(result, out, protocol=pickle.HIGHEST_PROTOCOL)合并后按照官方给出的例子进行处理,处理结果如图

处理代码如下:
import pickle
#按照自己的方式切割训练集和验证集
split={"train":[],"val":[]}
for i in range(91):
if(i+1<70):
split["train"].append(str(i))
else:
split["val"].append(str(i))
with open('F:/assembly.pkl', 'rb') as f:
annotations=pickle.loads(f.read())
with open('F:/mnist_train.pkl', 'wb') as f:
pickle.dump(dict(split=split, annotations=annotations), f)最后按照官网在F:\mmaction2\configs\skeleton\posec3d修改配置文件。
主要修改 23行num_classes,28行ana_file改成我们生成的pkl文件,94行、104行、106行分别改成train、val、val。
下面是我的slowonly_r50_8xb16-u48-240e_ntu60-xsub-keypoint.py修改结果,你们可以参考
_base_ = '../../_base_/default_runtime.py'
model = dict(
type='Recognizer3D',
backbone=dict(
type='ResNet3dSlowOnly',
depth=50,
pretrained=None,
in_channels=17,
base_channels=32,
num_stages=3,
out_indices=(2, ),
stage_blocks=(4, 6, 3),
conv1_stride_s=1,
pool1_stride_s=1,
inflate=(0, 1, 1),
spatial_strides=(2, 2, 2),
temporal_strides=(1, 1, 2),
dilations=(1, 1, 1)),
cls_head=dict(
type='I3DHead',
in_channels=512,
num_classes=3,
dropout_ratio=0.5,
average_clips='prob'))
dataset_type = 'PoseDataset'
ann_file = 'F:/mnist_train.pkl'
left_kp = [1, 3, 5, 7, 9, 11, 13, 15]
right_kp = [2, 4, 6, 8, 10, 12, 14, 16]
train_pipeline = [
dict(type='UniformSampleFrames', clip_len=48),
dict(type='PoseDecode'),
dict(type='PoseCompact', hw_ratio=1., allow_imgpad=True),
dict(type='Resize', scale=(-1, 64)),
dict(type='RandomResizedCrop', area_range=(0.56, 1.0)),
dict(type='Resize', scale=(56, 56), keep_ratio=False),
dict(type='Flip', flip_ratio=0.5, left_kp=left_kp, right_kp=right_kp),
dict(
type='GeneratePoseTarget',
sigma=0.6,
use_score=True,
with_kp=True,
with_limb=False),
dict(type='FormatShape', input_format='NCTHW_Heatmap'),
dict(type='PackActionInputs')
]
val_pipeline = [
dict(type='UniformSampleFrames', clip_len=48, num_clips=1, test_mode=True),
dict(type='PoseDecode'),
dict(type='PoseCompact', hw_ratio=1., allow_imgpad=True),
dict(type='Resize', scale=(-1, 64)),
dict(type='CenterCrop', crop_size=64),
dict(
type='GeneratePoseTarget',
sigma=0.6,
use_score=True,
with_kp=True,
with_limb=False),
dict(type='FormatShape', input_format='NCTHW_Heatmap'),
dict(type='PackActionInputs')
]
test_pipeline = [
dict(
type='UniformSampleFrames', clip_len=48, num_clips=10, test_mode=True),
dict(type='PoseDecode'),
dict(type='PoseCompact', hw_ratio=1., allow_imgpad=True),
dict(type='Resize', scale=(-1, 64)),
dict(type='CenterCrop', crop_size=64),
dict(
type='GeneratePoseTarget',
sigma=0.6,
use_score=True,
with_kp=True,
with_limb=False,
double=True,
left_kp=left_kp,
right_kp=right_kp),
dict(type='FormatShape', input_format='NCTHW_Heatmap'),
dict(type='PackActionInputs')
]
train_dataloader = dict(
batch_size=1, #实验改为1
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type='RepeatDataset',
times=10,
dataset=dict(
type=dataset_type,
ann_file=ann_file,
split='train',
pipeline=train_pipeline)))
val_dataloader = dict(
batch_size=1, #实验改为1
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
ann_file=ann_file,
split='val',
pipeline=val_pipeline,
test_mode=True))
test_dataloader = dict(
batch_size=1,#实验改为1
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
ann_file=ann_file,
split='val',
pipeline=test_pipeline,
test_mode=True))
val_evaluator = [dict(type='AccMetric')]
test_evaluator = val_evaluator
train_cfg = dict(
type='EpochBasedTrainLoop', max_epochs=24, val_begin=1, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
param_scheduler = [
dict(
type='CosineAnnealingLR',
eta_min=0,
T_max=24,
by_epoch=True,
convert_to_iter_based=True)
]
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.2, momentum=0.9, weight_decay=0.0003),
clip_grad=dict(max_norm=40, norm_type=2))
然后终端输入(需要选择自己改的配置py文件)
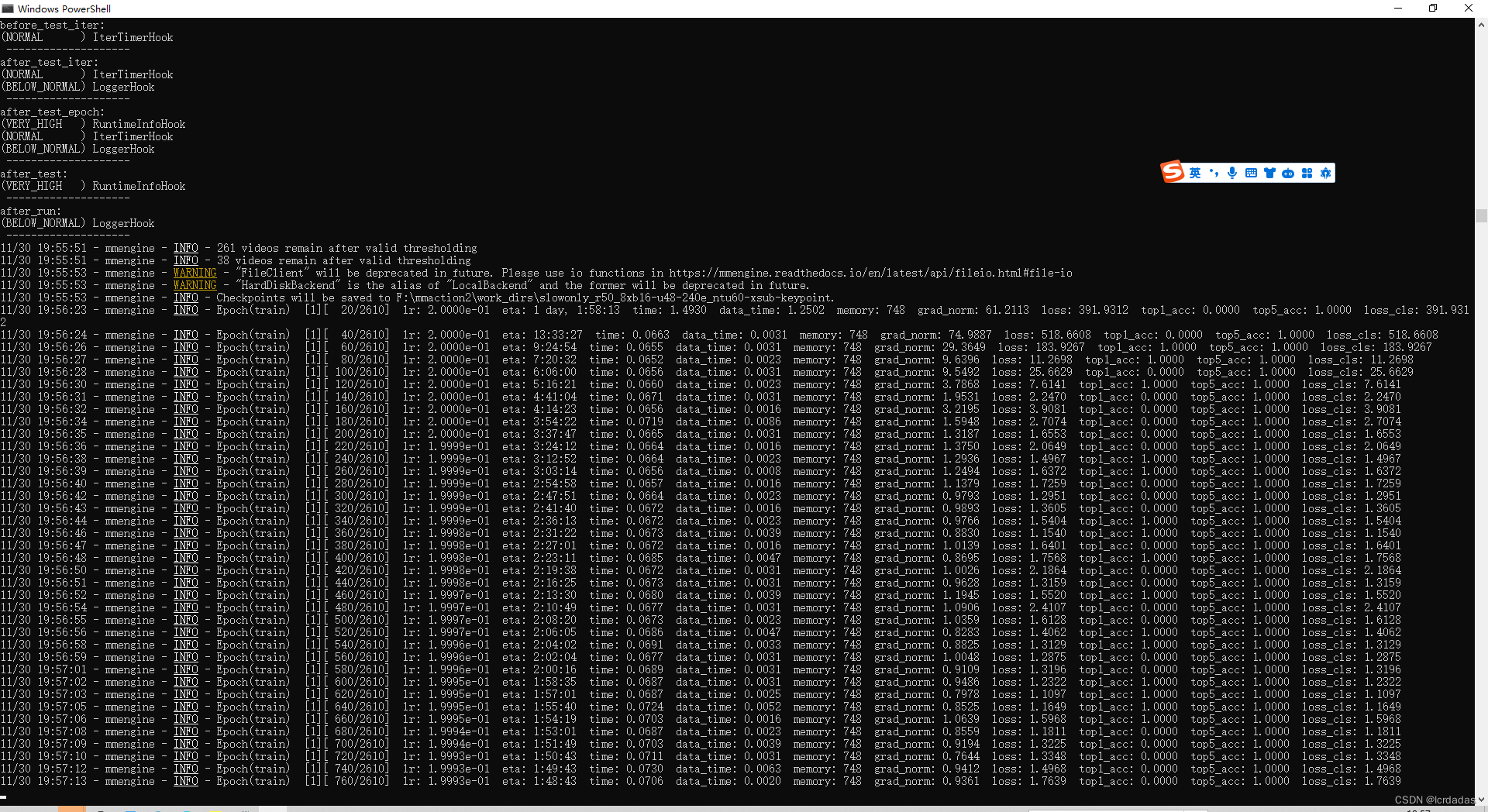
python tools/train.py configs/skeleton/posec3d/slowonly_r50_u48_240e_ntu120_xsub_keypoint.py --work-dir work_dirs/slowonly_r50_u48_240e_ntu120_xsub_keypoint然后就可以成运行:














 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









