









题目
A method based on multi-standard active learning to recognize entities
in electronic medical record
一种基于多标准主动学习的电子病历实体的识别方法
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
摘要
解决人工标注数据问题;
提出基于多标注主动学习来标注实体识别的方法;三个关键标准:标记数据的数量,句子注释的成本,数据采样的平衡;
样本数据下降到66.7%就可以达到传统学习的水平;
提出的方法思路
==不平衡的数据很容易破坏主动的学习性能,==有人通过SVM去解决,可是时间复杂度太大,后来考虑把聚类引入来,可是K-mean只考虑了特征;
提出三个指标:
指标1:聚类–用于平衡样本数据(即数据稀疏性);
指标2:Gini impurity(不确定选择策略) - 去减少标记数据的数量;
指标3:基于不确定性与标注成本混合关系- 根据实际情况来决定;
在医学领域,大部分都基于单标准的,这是第一篇提出多标准的论文;
论文主动学习框架-- Multi-Standard Active Learning(MSAL)
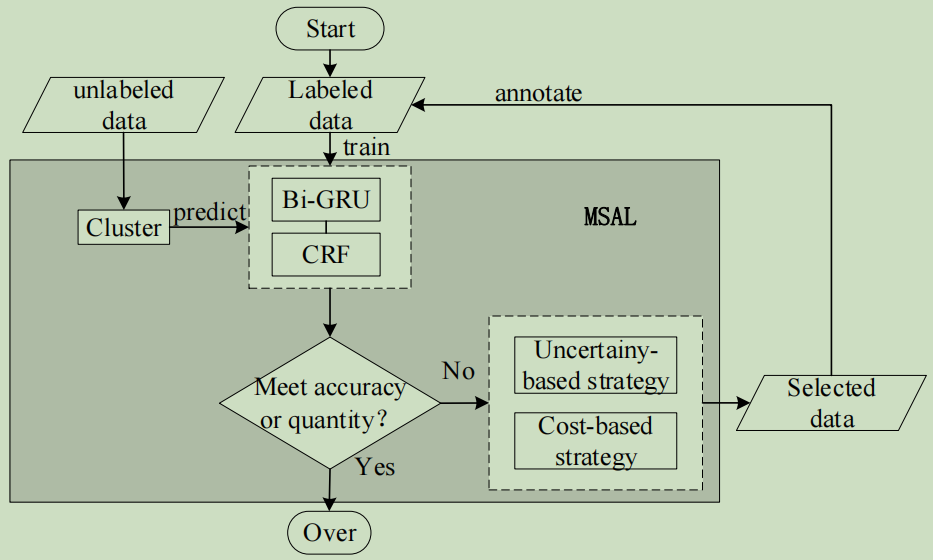
首先,训练MSAL的方法,通过迭代选择训练数据来识别实体,逐步提高模型性能,在较小的数据集中获得较强的泛化能力。
然后,对未标注的数据集作聚类;使用模型去预测聚类的文本;
接着,基于不确定性和基于成本的选择策略选择样本,并作标注;
最后,把标注的样本放入到Labeled数据集中,再进行训练;
关键问题是—样本选择策略—这里关注可靠性,标注成本,数据稀疏性;
一方面,不确定度度量是降低注释成本的最佳方法;
另一方面,聚类可以确保医学短文本数据的数据采样平衡;
关键流程
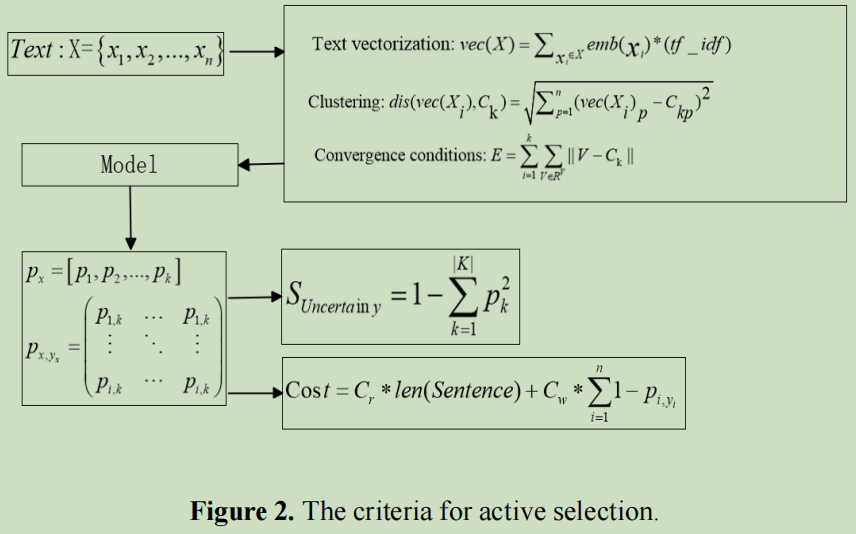
Clustering - 聚类
目的是保证数据样本平衡性。
文本向量:

k-means的Euclidean distance公式:
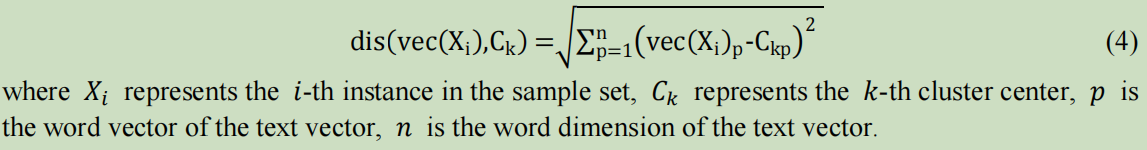
k-means迭代的结束条件–E收敛:
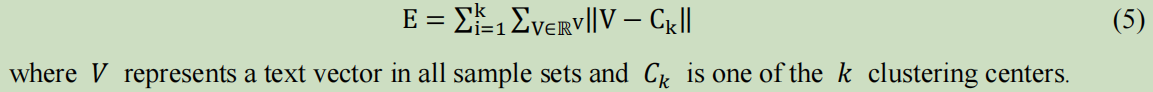
Uncertainty - 不确定性
采用信息熵来衡量不确定性:
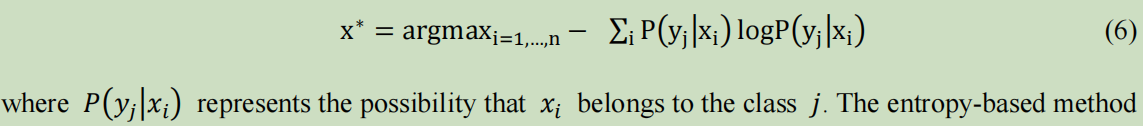
补充一个知识点:
熵定义的实际上是一个随机变量的不确定性,熵最大时,表示随机变量最不确定,也就是随机变量最随机,对其行为做准确预测最困难。
在这里,选择熵最大,也就是表示,样本被模型所标注是最不确定的,是模型是知道这个输出是不知道的。所以,要oracle来标注。
可是这个计算有一个缺点:计算效率问题。所以选择了基尼指数(Gini impurity):
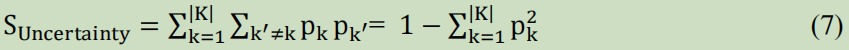
K表示分类数;p_k表示样本属于类k的概率;p_k_`表示样本属于其它类的概率;当实例以相同的概率分布在不同的类中时,Gini指数最大。当所有的实例都属于同一个类时,Gini指数为0,这意味着杂质是最低的。这个本质与熵反映的情况是很相似的。
Gini的知识点:
基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.其实这个公式更好看一些:
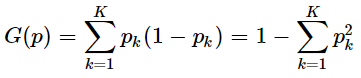
Labeled cost - 标注成本
Annotation Rate (AR)
这里提出,标注一个句子的成本与句子长度是相关的:
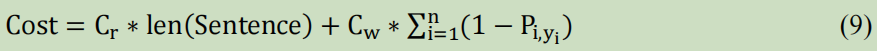
Cr选择句子的阅读时间;
Cw专家修改词的平均时间;
Pi_yi:第i个词标注为y_i的概率;
Combination strategy - 整合

MSAL算法流程

实验
评估采用了精准率:
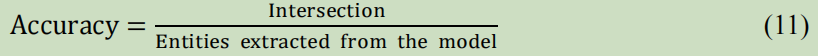
数据集:
本文所使用的实验数据是来自中国上海一家前三名医院的4000例患有乳腺癌的电子病历,具体数据情况:


train : test = 3200:800
训练组的初始规模是35000个短句(约300份医疗记录),它迭代了每轮增加17500个短句(约150份医疗记录)。
实验参数:
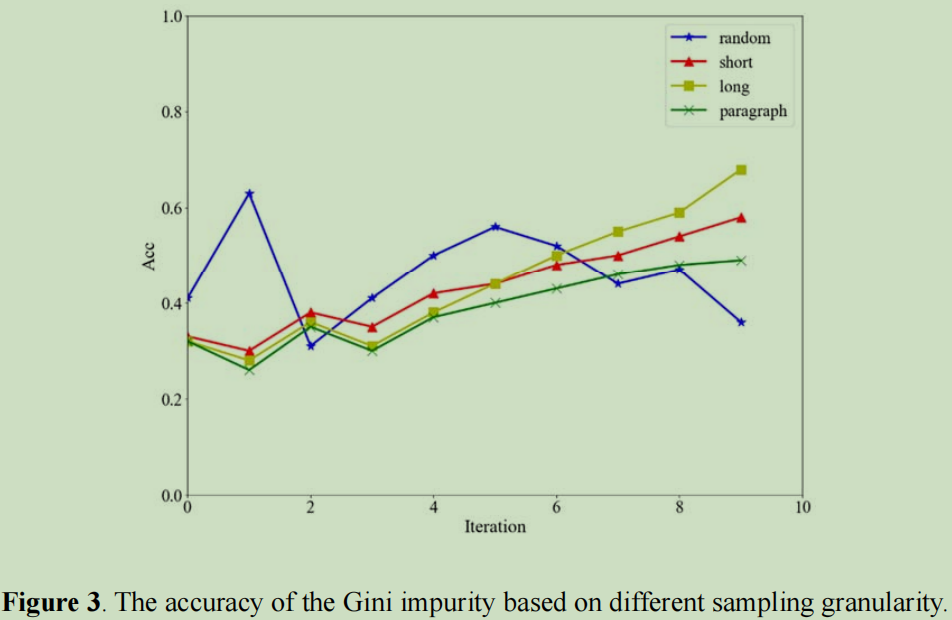
结果1,不同粒度的采样情况
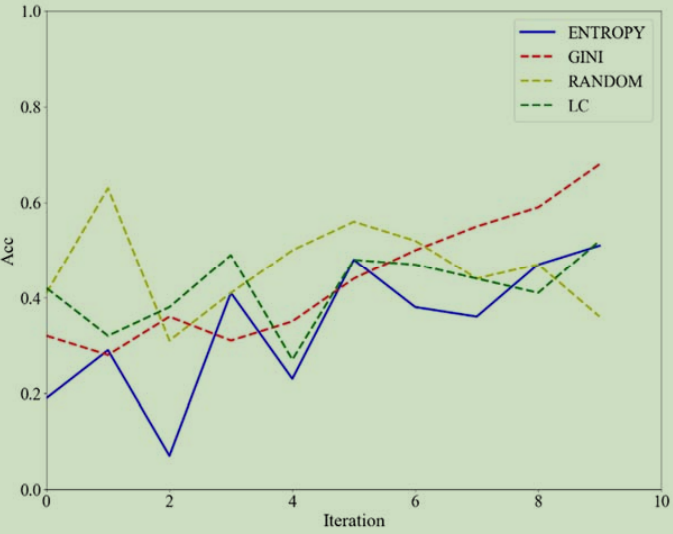
结果2:不确定性策略研究
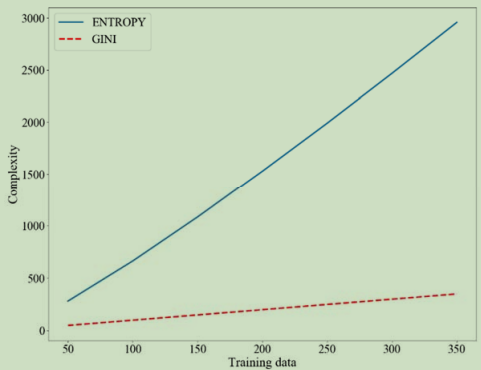
算法复杂性
结果3:消融分析
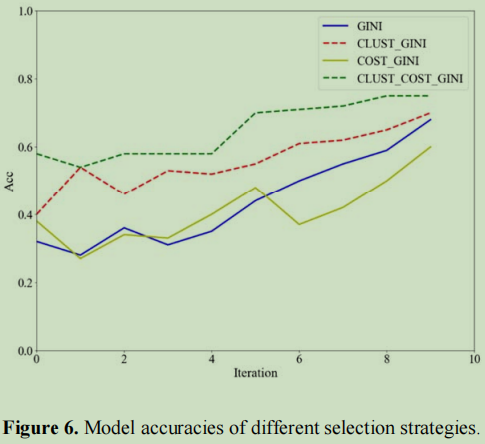
结果4: 综合评价
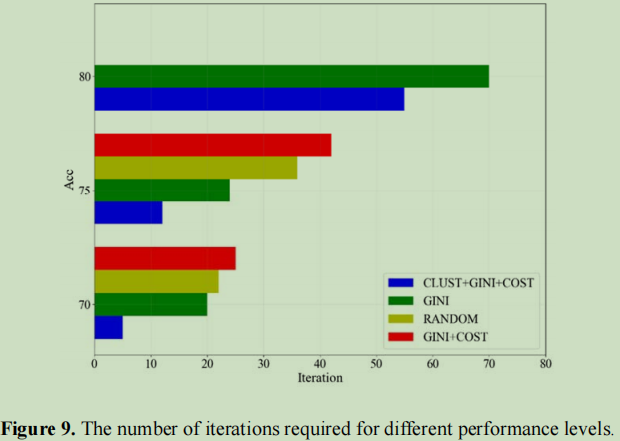
与传统的随机选择标记数据的监督学习方法相比,标记数据的学习量减少了约66.67%。
相关研究
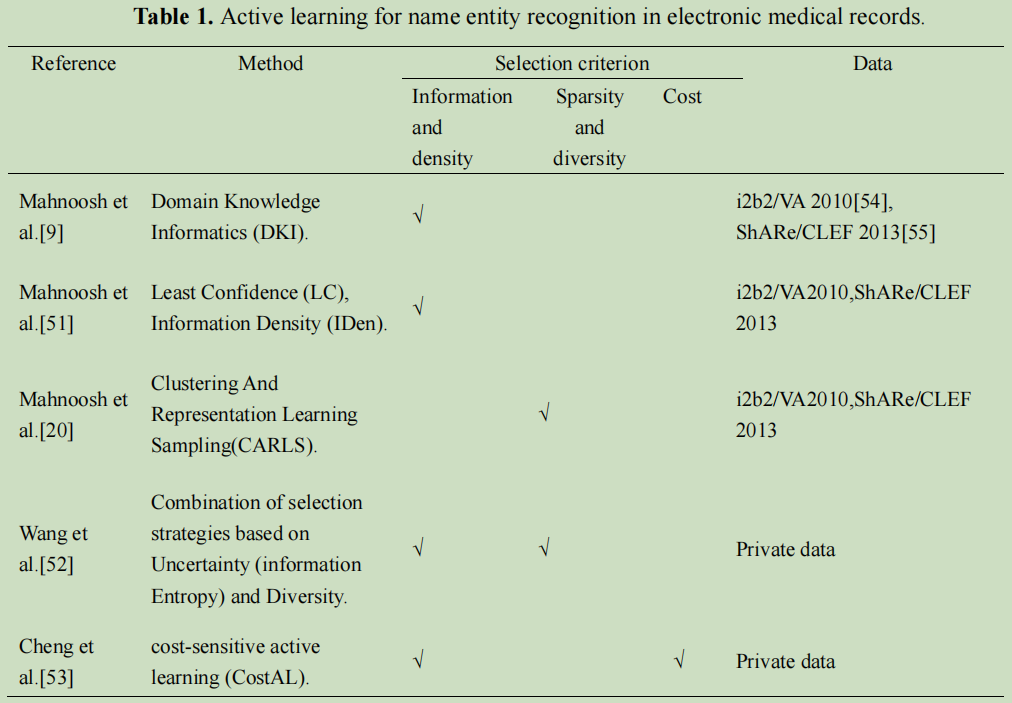
The core technology of active learning is strategy selection. (主动学习的核心技术是策略选择。),最近的研究主要在:
Data sparsity
EMRs数据不平衡。
- SVM相关模型—缺点SVM的时间复杂高
| 模型 | 说明 |
|---|---|
| KSVM active learning algorithm | header 2 |
| improved weighted SVM model | row 1 col 2 |
| the active learning algorithm based on SVM hyperplane position correction |
- clustering方法提出;
- 一种基于聚类的短文本分类方法(K-means,SVD)
缺点,只考虑k-means只是考虑了样本本身的属性特征,忽略了先验信息;
Entity recognition
Bayesian Classification Model [31],
Support Vector Machine (SVM) [32],
Hidden Markov Model (HMM) [33],
Maximum Entropy Markov Models (MEMM) [34],
Conditional Random Fields(CRF) [35]
Active learning
主动学习的核心目标是建立选择对模型最有用的样本数据的标准.
早期
member-based query method [21]
stream-based sampling method [44]
基于池的采样
uncertainty-based sampling[45–47],
version space-reduced sampling [48],
error-reduced sampling [49]
DKI,
考虑句子长度,考虑词,考虑概念都有研究;-
总结
完了一个电子病历抽取的一个实践,从纯的计算机技术的角度来看,用到的算法还是基本算法。整体来看,是简单可行,对于中文病历在对比上有参考价值。遗憾是没有读出眼前一亮的感觉,没有找到可以复现的代码。
参考
【1】Pan Q , Huang C , Chen D . A method based on multi-standard active learning to recognize entities in electronic medical record[J]. Mathematical Biosciences and Engineering, 2021, 18(2):1000-1021.
http://awstest-alb.aimspress.com/article/doi/10.3934/mbe.2021054
happyprince,https://blog.csdn.net/ld326/article/details/117334983















 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









