









 该研究提出了DUNE,一个使用去噪自编码器和网络嵌入技术的非监督中文医学概念标准化框架。它解决了由于文本噪声、疾病名称多样性、字序和同音异义词等问题导致的命名实体消歧挑战。通过结合文本嵌入和网络嵌入,DUNE在共病网络中捕捉疾病关系,提高了标准化的准确性。实验结果显示,DUNE在不同评估指标上优于传统的编辑距离和词袋模型等基线方法。
该研究提出了DUNE,一个使用去噪自编码器和网络嵌入技术的非监督中文医学概念标准化框架。它解决了由于文本噪声、疾病名称多样性、字序和同音异义词等问题导致的命名实体消歧挑战。通过结合文本嵌入和网络嵌入,DUNE在共病网络中捕捉疾病关系,提高了标准化的准确性。实验结果显示,DUNE在不同评估指标上优于传统的编辑距离和词袋模型等基线方法。
一,题目
Chinese Medical Concept Normalization by Using Text and Comorbidity Network Embedding
Y. Zhang, X. Ma and G. Song, “Chinese Medical Concept Normalization by Using Text and Comorbidity Network Embedding,” 2018 IEEE International Conference on Data Mining (ICDM), 2018, pp. 777-786, doi: 10.1109/ICDM.2018.00093.
北京大学
二,摘要
提出DUNE(Disease Unsupervised Normalization by Embedding); 一个能过使用 denoising auto-encoder(DAE) 、network embedding 技术进行非监督中文概念标准化框架;
三,提出的方法
3.1 问题认识
“Medical concept normalization is to map the mentions to corresponding entities.”
通常医学概念标准化可以被视为一个命名实体消歧(NED)问题(Named Entity Disambiguation。
为什么可以理解成NED问题?
这项任务的主要问题是消除文本中噪声带来的歧义,例如多数据库的拼写错误和非标准表达。
3.2 解决问题
-
注释医疗数据的成本高;
-
中文疾病名称充满着各种噪音(说白了中文含义太太多了);
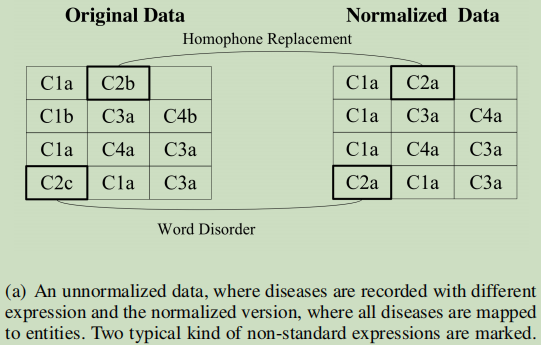
非标准的字序与同音异义字
Edit Distance–不能处理字序问题,BM-25(Bag-of-Words vector)不能处理同音异义字的问题;
-
共病信息利用困难
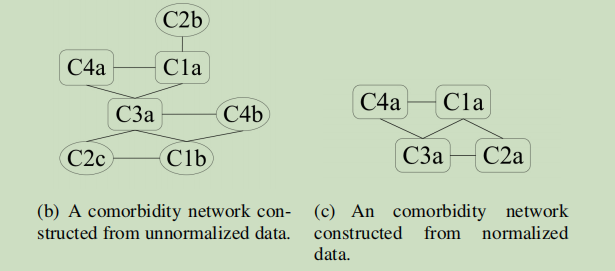
(b)为非标准化的数据构建成的合并症网络;
(c)表示标准化的数据构建的 ;
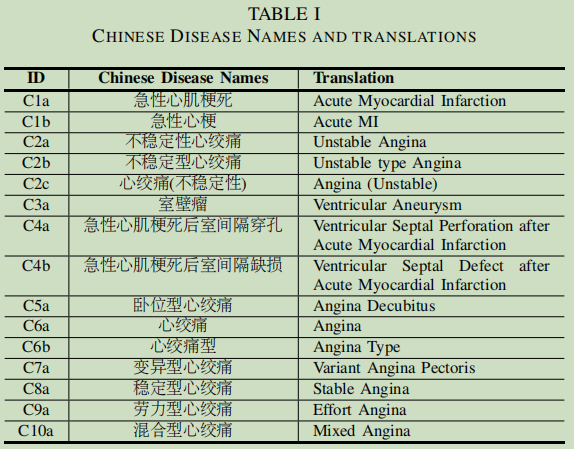
注意,上面的code要配合下面的表来看的,上面的图只是一个疾病ID:
提出 denoising auto-encoder (DAE) – Multi-view attention based denoising auto-encoder – text-involved second-order proximity based
network embedding technique
3.3 输入数据
电子病历: R = *{d1, d2, … , dn}di
di = {mi1, mi2, … , mik} – 病人的第i个诊断,mj为mention;
标准疾病数据库: K = {e1, e2, … , en}
3.4 Comorbidity Network – 共病性网络
R -> G = (V , W) , V为mentions集合, W为邻接矩阵;Wij表示对应边的权重。表示vi,vj在同一病历中同时出现;
建网络的步骤:
- Node Set Initialization.
搜索整个记录R,并提取所有不同的疾病名称作为共病网络中的节点。将标准名称设置为Entity节点,并将非标准名称设置为mentions节点,椭圆表示mentions, 矩形表示entity。
- Weight Matrix Calculation
a. 初始化W所有元素为0.
b. 如果两个mentions在同一病历的,Wij = Wij+1
注意到每个疾病的名称视为一个节点,有几个节点可能对应于一个实体,这导致难以测量共病相似性。我们称这种现象称为网络结构噪声(Network Structure Noise)。
3.5 Problem Statement: Chinese Medical Concept Normalization
包含文本噪声的电子病R --> 构建的包含网络结构噪声的共病网络G
标准数据库K --> 非标准名称查找最相似的实体。
3.6 方法论
主要思想是嵌套的方法。
通过比较mention-entity对,对每个mentions选择最近似的实体作为标准化结果。
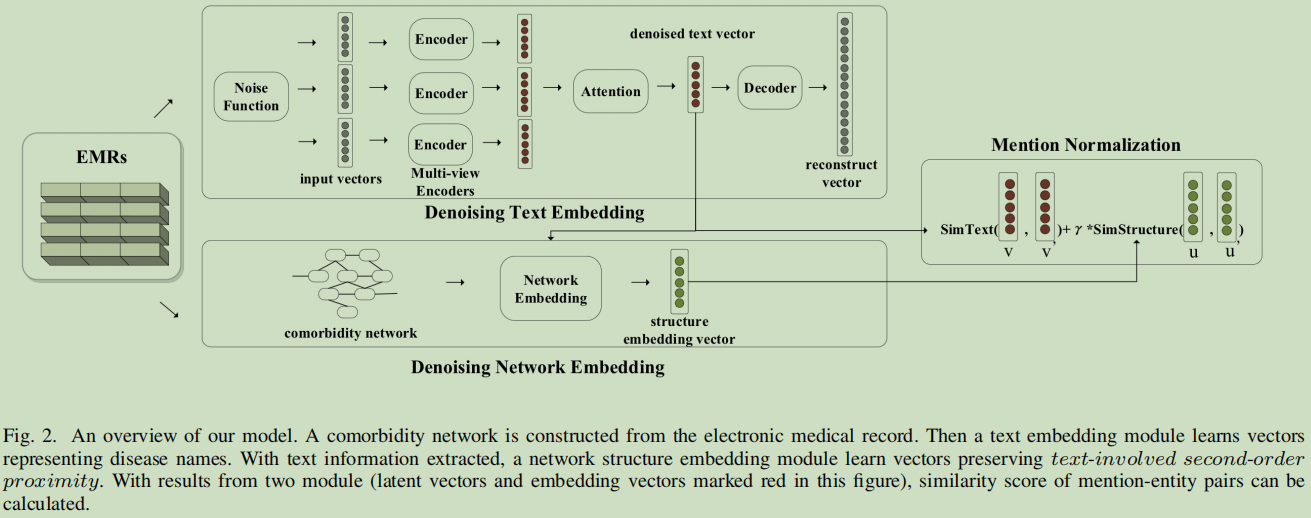
3.6.1 Denoising Text Embedding – 文本嵌入
文本嵌入模块,把疾病名嵌入到向量中;
使用非标准化的mentions与实体作为输入,采用Noise函数进行对这些输入进行破坏,然后在DAE中进行训练。这样来完成文本嵌入。输入有两个特点:short与noise,故提出: multi-view attention based denoising auto-encoder (MADAE)
- Multi-view Encoders – 多视图编码
**Word View ** – 词
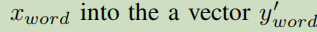
Character View – 字
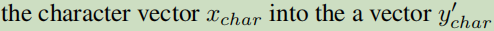
Pronunciation View – 音

- Attention Layer for Combining Multiple Views – 合并多视图的Attention层

- MADAE Model and Training
采用所有的mentions与entity来训练。
noise函数在有经验的医生的指导下设计: Character Deletion:随机删除一个字符; Homophone Replacement: 同音词替换;
以重构原始输入作为训练,使用了更个robust去设计:
reconstructs Bag-of-Character vector of original text;
single layer neural network;

损函数:
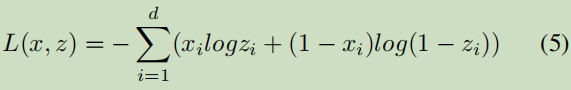
xi为原语料的词袋表示,zi是sigmoidl输出,这里不知道词大少为多少?
3.6.2 Denoising Network Embedding
这里是图嵌入模块。
直觉的方法:衡量mention-entity关系对的first-order proximity与second-order proximity. 参考:Line: Large-scale information network embedding
first-order方法假设权重大的两点比较相似;
second-order方法表示节点与具有相似邻域网络结构的其他节点相似。通过领域的信息来表现自己,这个像gcn的了。
这个缺点,没有考虑自身的情况:

提出:Text-Involved Second-Order Proximity – 测量文本和网络结构中节点邻居的相似性。
xi = (Wi1, Wi2, … , W_i|M|),两个因素决定两节点的距离:
因素1:x_u和x_v之间的相似性;
因素2:u和v的邻居所包含的文本信息之间的相似性;
2) Denoising Network Embedding Model
计算vi与vj匹配的概率公式:
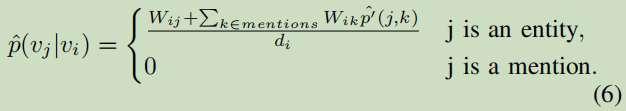
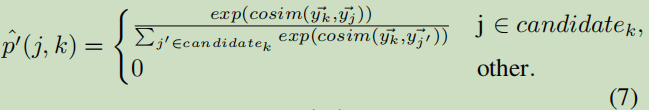
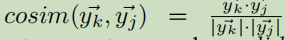
y表示文本嵌入。
计算嵌入向量:
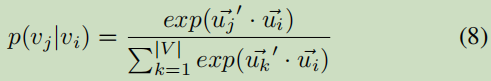
损失函数–(K-L 散度):
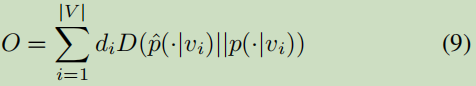
简化为:
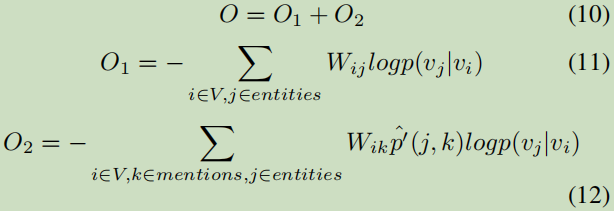
优化:
式10的计算要遍历所有的节点,这是一个比较麻烦的东西,这里通过负采样的方法来代替logp(.|.)的计算。
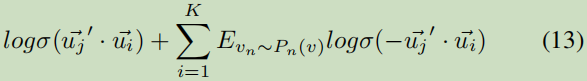
3.6.3 Mention Normalization
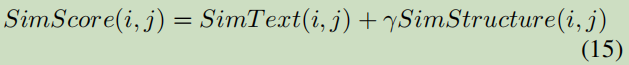
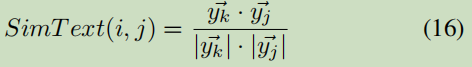
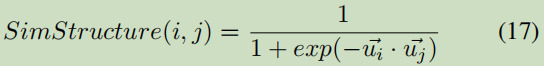
y表示文本嵌入;u表示网络结构嵌入。
实验
数据集:270000 diagnoses
评估策略:
top-1 accuracy
top-5 accuracy
top-10 accuracy
基线:
Bow (Bag-of-words)
BM25
Naive Edit Distance
Rule-Based Edit Distance
Auto-Encoder
LINE(Line: Large-scale information network embedding)
非监督实验结果
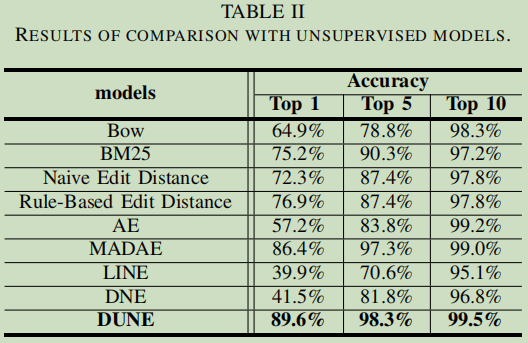
MADAE,DNE,DUNE为论文的模型,DUNE为前两的混合。另外前面有一个基于规则编辑距离也是可以参考的一个好方法。
与监督类实验的结果对比
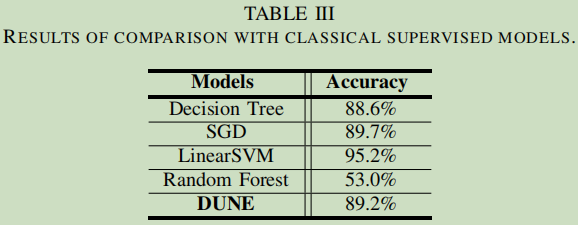
LinearSVM在有监督方面还是可以去参考的,其实本论文的结果也是不错的的了。
消融分析
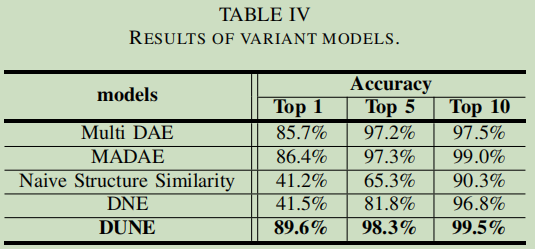
维度分析
向量的维度数对于实验结果影响不大。
案例分析
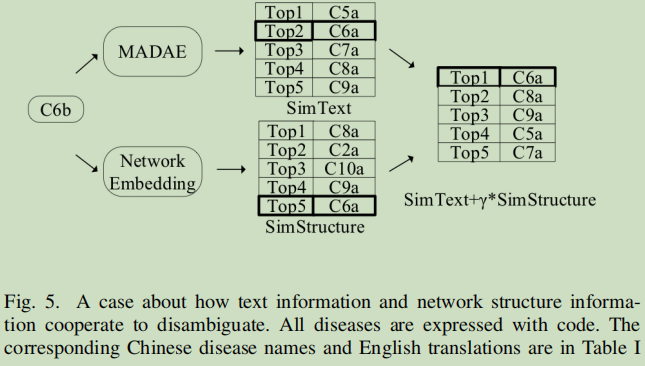
“C6b”:“心绞痛型”
“C6a” :“心绞痛”
“C5a” :“卧位型心绞痛” 【在文本嵌入中,这个与目标更近】
C8a :稳定型心绞痛
总结
对于所研究的数据,模型有有大的提升,其实是很想知道把这个模型移到其它数据上,效果是依然是佳的。
相关工作
Medical Concept Normalization
一般有两条思路去解决这个问题:
思路1: 局部方法 – 难达到好的效果
思路2: 全局方法 – 在像病历的短文本也是比较难用的。
具体方法:
| 题目 | 解释 |
|---|---|
| 2012-An inference method for disease name normalization | 朴素编辑距离,字典查找与字符串匹配 |
| 2013-Dnorm:disease name normalization with pairwise learning to rank | 典型的词典与语法相结合的方法,pairwise学习 |
Auto-encoder
Sparse Auto-Encoder, stacked Auto-Encoder and Denoising Auto-Encoder
Network Embedding
2015- Line: Large-scale information network embedding
https://blog.csdn.net/ld326/article/details/117717723?spm=1001.2014.3001.5501

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









