







 Sentence-BERT(SBERT)是2019年EMNLP会议上提出的一种方法,它通过在BERT模型上添加Pooling操作来生成固定长度的句子嵌入。论文表明,平均Pooling(MEAN)策略在多种实验中表现出色,特别是在句子相似性任务上。SBERT还使用了分类、回归和Triplet损失函数,并在多个数据集如STS、AFS和Wikipedia上进行了验证。此外,SentEval工具的评估显示SBERT有显著提升。尽管在学术上缺乏新颖性,但该模型因其简洁和实用性受到推崇,适合工业应用。
Sentence-BERT(SBERT)是2019年EMNLP会议上提出的一种方法,它通过在BERT模型上添加Pooling操作来生成固定长度的句子嵌入。论文表明,平均Pooling(MEAN)策略在多种实验中表现出色,特别是在句子相似性任务上。SBERT还使用了分类、回归和Triplet损失函数,并在多个数据集如STS、AFS和Wikipedia上进行了验证。此外,SentEval工具的评估显示SBERT有显著提升。尽管在学术上缺乏新颖性,但该模型因其简洁和实用性受到推崇,适合工业应用。
1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks | 达姆施塔特工业大学 --德国 | EMNLP | 2019 |
1791 Citations
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. ArXiv, abs/1908.10084.
论文链接:https://aclanthology.org/D19-1410/#
论文代码:https://github.com/UKPLab/sentence-transformers
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| 语义表示 | bert在计算similar时效率底 | 模型上只是在bert上加了一层pooling | 做了比较多实验,效果好,很合适工业的胃口 | sts | 在某些方面的效果比bert好 | 方法 | 句子相似 |
3. 模型(核心内容)
3.1 模型
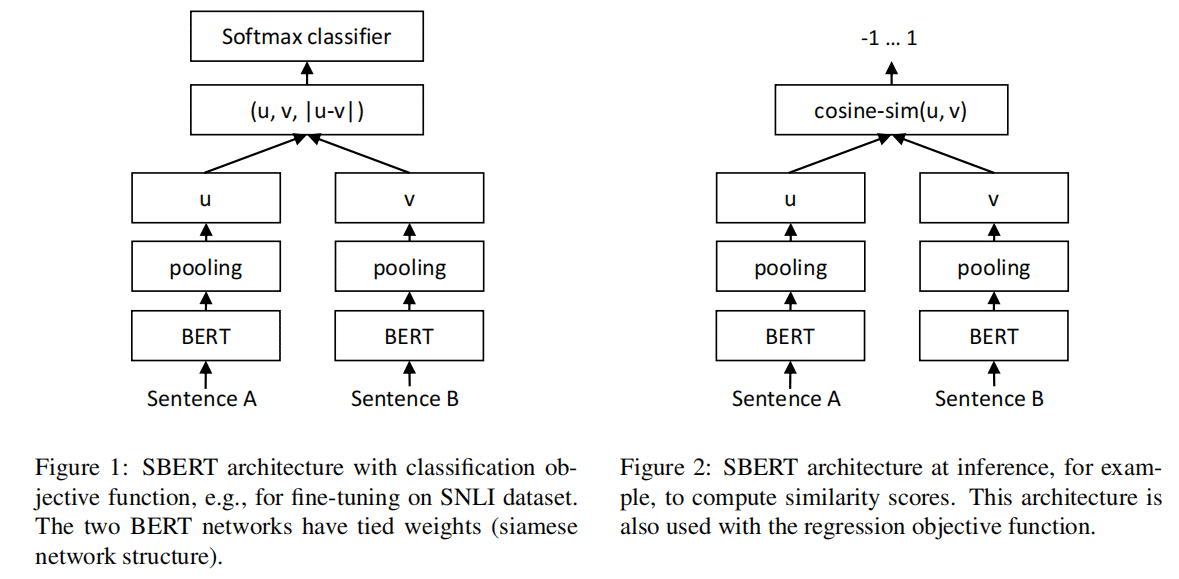
模型结构分两种,左边为分类任务;右边为回归任务及推理框架。回归模型采用了cosin函数来计算相关度.
SBERT是通过在BERT之加入pooling操作来获得一个固定长度的句子嵌入. 用来三种pooling策略
:CLS-token, MAX, MEAN
论文说MEAN的效果比较好。
3.2 损失函数
介绍了三个损失函数:分类,回归,Triplet

4. 实验与分析
4.1 数据集
sts, AFS, Wikipedia
4.2 模型的策略研究

Sbert增加u*v使效果稍差;
|u-v|这个特征的加入对Sbert很重要;
Max策略在BiLSTM中比MEA更好(InferSent用的是BiLSTM).
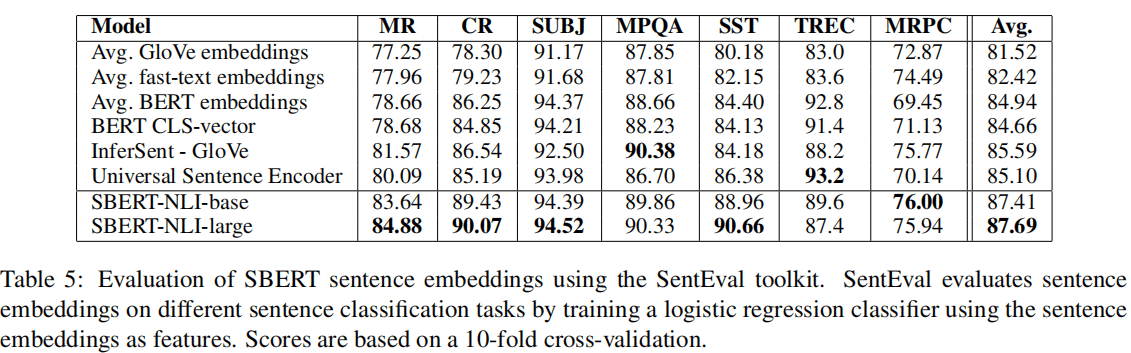
4.3 SentEval平台的效果
SentEval是一个评估句子嵌入的工具,
SBERT在SentEval有两个点的提升
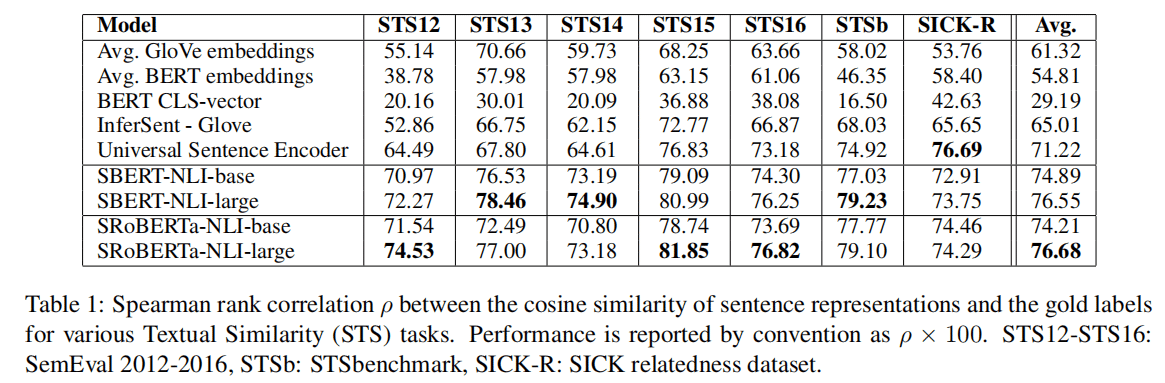
4.4 Unsupervised STS与Supervised STS
非监督
这里的非监督,是指不采用STS的train与dev数据集来训练,却用test数据集来评估.
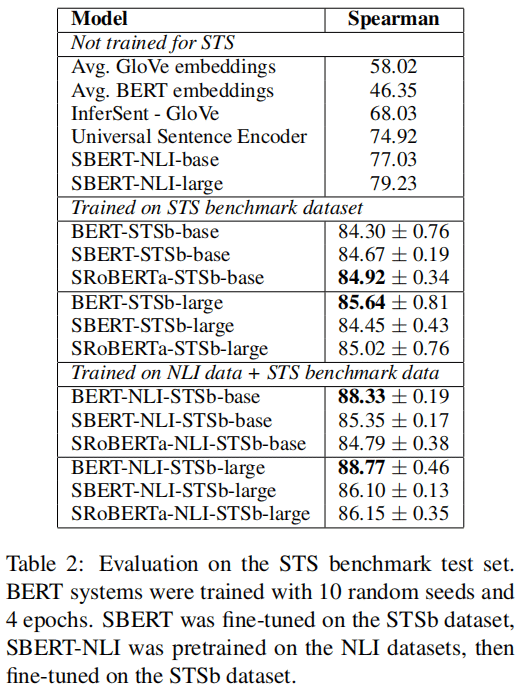
监督
5. 代码
这个的确是使用起来比较友好。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
sentence_embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
6. 总结
这是一篇很实用的文章,模型不复杂,从学术的角度来看,好像没有太多的创新点,可是好用。从工程 的角度来看,很喜欢这样的文章,简单得来又易用。就喜欢这各简单得来,效果好的的东西。
6.1 优
有代码,好用。可以满足很多实际需求。
6.4 不足
三元样本没有看到实验。
另外,如果看成是学术论文,差一点理论创新点。
7. 知识整理(知识点,要读的文献,摘取原文)
句子嵌入: Skip-Thought(encoder-decoder architecture), InferSent(siamese BiLSTM network), poly-encoders,
8. 参考文献
【1】 Ryan Kiros, Yukun Zhu, Ruslan R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Skip-Thought Vectors. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 3294–3302. Curran Associates, Inc.
【2】Alexis Conneau, Douwe Kiela, Holger Schwenk, Lo¨ıc Barrault, and Antoine Bordes. 2017. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, Copenhagen, Denmark. Association for Computational Linguistics
made by happyprince

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









