










摘要:下载与配置最新版的flume-ng1.7.0.第一步,测试一个Avro例子,第二步,测试一个HDFS例子,最后一步把这两个例子放在一起,从单个节点扩展到三个节点来实现集群,各个子节点上运行agent来收集日志,最后汇总并更新到HDFS上。
前置
大数据学习前夕【02】:JDK安装升级
大数据学习前夕[01]:系统-网络-SSH: http://blog.csdn.net/ld326/article/details/77995835
大数据学习[02]:hadoop安装配置:
http://blog.csdn.net/ld326/article/details/78004402
本实验的运行环境可参照上面三篇文章;
官网
http://flume.apache.org/index.html
flume分为OG与NG,即是新旧版本,这两版本的差别比较大,相对来说NG会简单一些,同时也流行与优点多一些。
flume-ng API: http://flume.apache.org/releases/content/1.3.0/apidocs/index.html
flume-ng主要是一个agent, 网上比较多,有些写得很好,不重复描述.
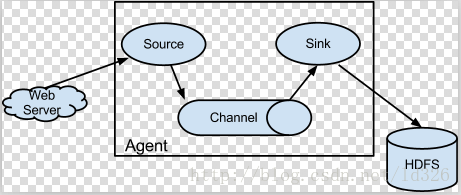
下载
新版本:http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
旧版本:http://archive.apache.org/dist/flume/
本文选择最新版本(1.7.0)来配置。
系统要求
java 1.7或以上
有读写权限
配置01[Avro测试]
# 三个组件
agent1.channels = ch1
agent1.sources = avro-source1
agent1.sinks = log-sink1
# Define a memory channel
agent1.channels.ch1.type = memory
# 定义Avro:
agent1.sources.avro-source1.channels = ch1
agent1.sources.avro-source1.type = avro
agent1.sources.avro-source1.bind = 0.0.0.0
agent1.sources.avro-source1.port = 41414
# 定义sink
agent1.sinks.log-sink1.channel = ch1
agent1.sinks.log-sink1.type = logger
# Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.启动
[hadoop@hadoop01 apache-flume-1.7.0-bin]$ bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n agent1启动client
[hadoop@hadoop01 apache-flume-1.7.0-bin]$ bin/flume-ng avro-client --conf conf -H localhost -p 41414 -F /home/hadoop/testData/tst -Dflume.root.logger=DEBUG,consoleclient端会输出如下信息,表示向flume建立连接与把数据传输去去。
2017-09-23 18:19:58,984 (New I/O server boss #3) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 => /127.0.0.1:41414] OPEN
2017-09-23 18:19:58,989 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 => /127.0.0.1:41414] BOUND: /127.0.0.1:41414
2017-09-23 18:19:58,989 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 => /127.0.0.1:41414] CONNECTED: /127.0.0.1:57820
2017-09-23 18:19:59,661 (New I/O worker #1) [DEBUG - org.apache.flume.source.AvroSource.appendBatch(AvroSource.java:378)] Avro source avro-source1: Received avro event batch of 3 events.
2017-09-23 18:19:59,754 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 :> /127.0.0.1:41414] DISCONNECTED
2017-09-23 18:19:59,754 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 :> /127.0.0.1:41414] UNBOUND
2017-09-23 18:19:59,754 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x52d9e861, /127.0.0.1:57820 :> /127.0.0.1:41414] CLOSED
2017-09-23 18:19:59,755 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.channelClosed(NettyServer.java:209)] Connection to /127.0.0.1:57820 disconnected.
2017-09-23 18:20:03,148 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 68 61 70 70 79 70 72 69 6E 63 hello happyprinc }
2017-09-23 18:20:03,148 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 70 72 69 6E 63 65 2E 2E 2E hello prince... }
2017-09-23 18:20:03,149 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 70 72 69 6E 63 65 2E 2E 2E hello prince... }当client产生日志,flume收集那边是这样显示的:
2017-09-23 18:19:58,633 (main) [DEBUG - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:498)] Batch size string = 5
2017-09-23 18:19:58,658 (main) [WARN - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:634)] Using default maxIOWorkers
2017-09-23 18:19:59,743 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:233)] Finished
2017-09-23 18:19:59,748 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:236)] Closing reader
2017-09-23 18:19:59,752 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:240)] Closing RPC client
2017-09-23 18:19:59,767 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.main(AvroCLIClient.java:84)] Exiting配置02[把文件上传到HDFS上]
vim flume-hdfs.conf创建目录/home/hadoop/testData/flumTmp,并在这个目录下写上一些内容;启动flume就会把这个目录下的目录全都同步读取到hdfs上了。
agent1.channels.ch1.type = memory
agent1.sources.spooldir-source1.channels = ch1
agent1.sources.spooldir-source1.type = spooldir
agent1.sources.spooldir-source1.spoolDir=/home/hadoop/testData/flumTmp
agent1.sinks.hdfs-sink1.channel = ch1
agent1.sinks.hdfs-sink1.type = hdfs
agent1.sinks.hdfs-sink1.hdfs.path = hdfs://hadoop01:9000/test
agent1.sinks.hdfs-sink1.hdfs.filePrefix = events
agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true
agent1.sinks.hdfs-sink1.hdfs.round = true
agent1.sinks.hdfs-sink1.hdfs.roundValue = 10
agent1.channels = ch1
agent1.sources = spooldir-source1
agent1.sinks = hdfs-sink1启动
[hadoop@hadoop01 conf]$ bin/flume-ng agent --conf ./conf/ -f ./conf/flume-hdfs.conf --name agent1 -Dflume.root.logger=DEBUG,console会发现:文件后面加了completed
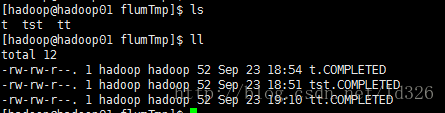
可以在这个目录下,任意增加多个文件,增加完,HDFS的目录下就会显示存在了。
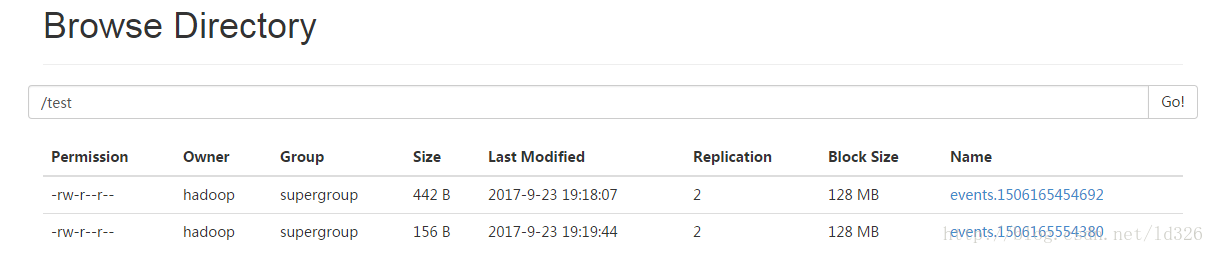
可以随意感受,可以设置这个文件上传完了把这个删掉也是可以了。
配置03(Flume-ng集群)
上面都是在一个主机上的测试,对于一个集群上都有日志,想把全部日志都收集回来,放到hdfs上,现在用三个节点来测试这个想法,具体如下设计:
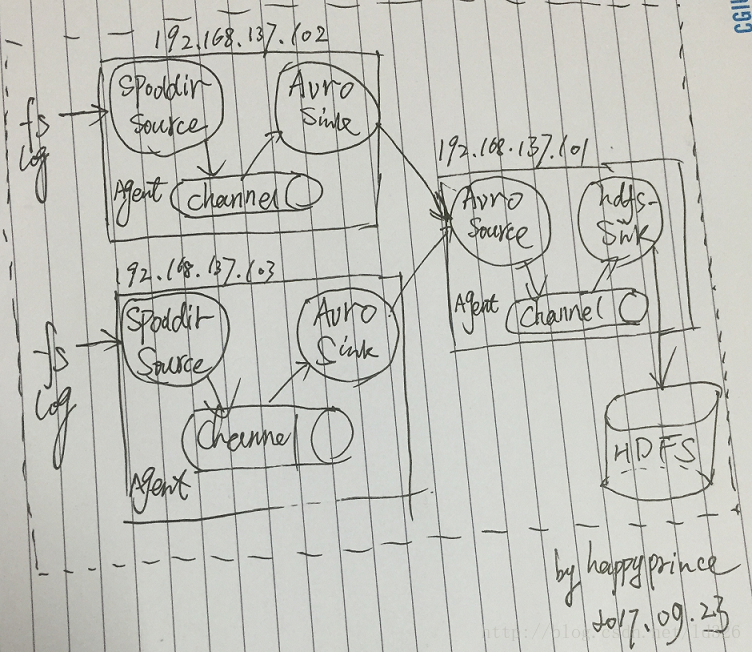
三个主机,102/103为在各自主机的agent,用这个agent来进行数据的收集,101把102与103收集的数据进行汇在一起,叫做consolidatio;
主机192.168.137.102/192.168.137.103配置为:
配置102/103[文件名为:agent.conf]:
#Agent:三个组件
a.channels = c1
a.sources = s1
a.sinks = k1
#Directory Source:采用文档目录形式来存放的log日志
a.sources.s1.type = spooldir
a.sources.s1.spoolDir = /home/hadoop/logs
a.sources.s1.fileHeader = true
a.sources.s1.batchSize =1000
a.sources.s1.channels =c1
a.sources.s1.deserializer.maxLineLength =1024
#FileChannel:Channel也是采用文件的形式来存,官方也是这样推荐的,比较安全
a.channels.c1.type = file
a.channels.c1.checkpointDir = /home/hadoop/apache-flume-1.7.0-bin/checkpoint
a.channels.c1.dataDirs = /home/hadoop/apache-flume-1.7.0-bin/data
a.channels.c1.capacity = 200000
a.channels.c1.keep-alive = 30
a.channels.c1.write-timeout = 30
a.channels.c1.checkpoint-timeout=600
#Sinks:Avro Sinks,把这样信息发送给101来收集
a.sinks.k1.channel = c1
a.sinks.k1.type = avro
# connect to CollectorMainAgent
a.sinks.k1.hostname = 192.168.137.101
a.sinks.k1.port = 9101配置101(文件名为:consolidatio.conf):
# Agent:三个元素
a.channels = c1
a.sources = s1
a.sinks = k1
# source接收各个节点上的数据
a.sources.s1.type = avro
a.sources.s1.channels = c1
a.sources.s1.bind = 192.168.137.101
a.sources.s1.port = 9101
# channel保存在文件中
a.channels.c1.type = file
a.channels.c1.checkpointDir = /home/hadoop/apache-flume-1.7.0-bin/checkpoint
a.channels.c1.dataDirs = /home/hadoop/apache-flume-1.7.0-bin/data
a.channels.c1.capacity = 20000
a.channels.c1.keep-alive = 30
a.channels.c1.write-timeout = 30
a.channels.c1.checkpoint-timeout=600
# sink到HDFS文件中
a.sinks.k1.channel = c1
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path = hdfs://hadoop01:9000/test
a.sinks.k1.hdfs.filePrefix = events
a.sinks.k1.hdfs.useLocalTimeStamp = true
a.sinks.k1.hdfs.round = true
a.sinks.s1.hdfs.roundValue = 10
a.sinks.k1.hdfs.fileType=DataStream
a.sinks.k1.hdfs.writeFormat=Text先启动101:
bin/flume-ng agent --conf conf --conf-file conf/consolidatio.conf --name a -Dflume.root.logger=DEBUG,console然后启动102/103:
bin/flume-ng agent --conf conf --conf-file conf/agent.conf --name a -Dflume.root.logger=DEBUG,console查看hadoop02的chanel储存的目录下数据:
各个节点可以随意增加日志了,会加合部日志都收集到HDFS上。
【作者:happyprince; http://blog.csdn.net/ld326/article/details/78073328】















 3600
3600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









