







数据选用
代码
数据处理
f = open(r"housing.data.txt")
lines = f.readlines()
with open("data.csv","w+") as t:
for i in lines:
i = ",".join(i.split())
t.writelines([i])
t.write("\n")
模型构建
import numpy as np
import pandas as pd
import tensorflow as tf
from keras.layers import Dense
import matplotlib.pyplot as plt
# 划分数据集
train_data = data[:int(len(data)*0.9)]
y_train = train_data[:,-1]
test_data = data[int(len(data)*0.9):]
y_test = test_data[:,-1]
# 添加序列模型
model = tf.keras.Sequential([
Dense(128,input_shape=(14,),activation="relu"),
Dense(64,activation="relu"),
Dense(1)
])
model.compile(optimizer="adam",loss="mse")
model.summary()
# 对模型进行拟合
model.fit(train_data,y_train,epochs=10,batch_size=8)
# 对模型进行评估 0.23200644552707672
model.evaluate(test_data,y_test)
# 利用测试集对数据进行预测
result = model.predict(test_data)结果可视化
new_data = pd.DataFrame({"Prediction":result.reshape(-1),"Actual":y_test.reshape(-1)})
new_data.plot()
plt.show()
回归算法
数据选用:
利用机器学习(LinearRegression)方法对比预测结果
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
data = pd.read_csv("data.csv")
# 数据划分
X,y = np.array(data.drop(["MEDV"],1)),np.array(data['MEDV'])
# 训练集和测试集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1) # random_state=0
# 模型拟合
linear = LinearRegression(n_jobs=-1)
linear.fit(X_train, y_train)
# 评估 0.8124025816789091
acc = linear.score(X_test, y_test)
prediction = linear.predict(X_test)
# 计算预测和实际值均方差 21.916277197562923
mse = mean_squared_error(y_test, prediction)
# 可视化
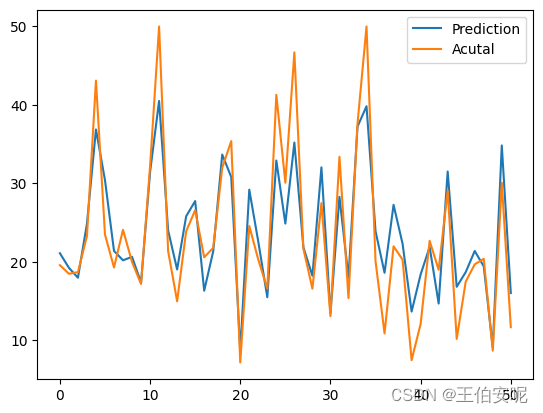
contrast = pd.DataFrame({"Prediction":prediction,"Acutal":y_test})
contrast.plot()
plt.show()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









