







源代码引用
数据介绍
示例数据集:PeMS04.npz PeMS04.csv
数据集由 Caltrans 绩效测量系统 (PEMS-04) 收集
数量:307探测器
时间:2018年1-2月 (2018.1.1——2018.2.28)
特点:流量、占用、速度。
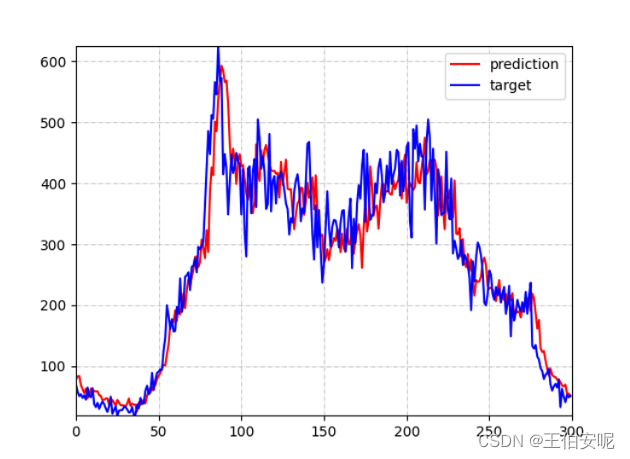
运行结果
运行 traffic_prediction.py,生成 GAT_result.h5 (用于数据存储)gat_node_120.png 第120号检测器数据预测结果。
源数据分析
import numpy as np
import pandas as pd
dataset = np.load("PeMS_04/PeMS04.npz") # np载入npz数据文件
print(dataset)
# NpzFile 'PeMS_04/PeMS04.npz' with keys: data
print(dataset["data]) # 通过键来访问数据
"""
array([[[6.20e+01, 7.70e-03, 6.79e+01],
[5.60e+01, 1.12e-02, 6.84e+01],
[9.00e+01, 1.43e-02, 6.82e+01],
...,
[5.60e+01, 9.80e-03, 6.74e+01],
[4.80e+01, 7.80e-03, 6.95e+01],
[3.80e+01, 9.40e-03, 6.82e+01]],
...
"""
# 看下形状
print("dataset["data"].shape")
# (16992, 307, 3)
data = pd.read_csv("PeMS_04/PeMS04.csv")
print(data["from"].max()) # 306
print(data["to"].max()) # 305
# dataset["data"].shape[1] 必须大于data["from"].max()/data["to"].max()通过数据分析可以得到的
1.在traffic_prediction.py第33/39行,注意到num_nodes=307 和 dataset["data"].shape[1]相同。
2.divide_days=[45, 14] ,time_interval=5, 一共用了59天的数据量,每5分钟记录一次数据。所以 59 * 12 * 24 = 16992。
3.history_length=6 需要与my_net中的in_c=6 保持一致。第92行测试阶段 Target = np.zeros([307, 1, 1]) 307也要与dataset["data"].shape[1]相同。
4.163行nodes_id 需要小于num_nodes
运用自己的数据
引用的数据是某城市地铁客流量信息 只有两个站点,意味着只有一个检测器
数据收集353天的数据量,时间间隔为15分钟。
需要具体数据请私信!
数据处理
# 原数据.npz文件用于存储站点三个特征值 .csv文件用于存储各个站点的cost(Maybe 花费?)
# csv文件我们只需要设置一个站点 因为只有一个监测站
import pandas as pd
# 我们可以这样编写 cost就算作一年的总客流量
dataset = pd.read_csv("9_to_45.csv").values
total = dataset[:,0].sum()
f = open("dataset.csv","+w")
f.write("from,to,cost" + "\n" + f"0,0,{total/4}" + "\n")
"""
from,to,cost
0,0,16675
"""
# .npz文件 我们重塑一下数据
shape = dataset.shape # (33887, 3)
data = dataset.reshape(shape[0],1,3) # 一个检测器
np.savez("dataset.npz",data=data) # 保持成npz文件格式
# 你也可以设置其他类型 但是要改的东西更多了
# data3 = np.reshape(dataset,(4841,7,3)) # 假设有7个检测器
# np.savez("test1.npz",data=data3)源代码修改
根据数据分析所得的在对应的地方进行修改
# num_nodes > data["from"].max()/data["to"].max() (1 > 0)
train_data = LoadData(data_path=["dataset.csv", "dataset.npz"], num_nodes=1, divide_days=[300, 52],
time_interval=15, history_length=4,
train_mode="train")
train_loader = DataLoader(train_data, batch_size=64, shuffle=True, num_workers=1) # num_workers是加载数据(batch)的线程数目
test_data = LoadData(data_path=["dataset.csv", "dataset.npz"], num_nodes=1, divide_days=[300, 52],
time_interval=15, history_length=4,
train_mode="test")
test_loader = DataLoader(test_data, batch_size=64, shuffle=False, num_workers=1)
# 模型选用 in_c 与 history_length 对齐
my_net = ChebNet(in_c = 4, hid_c = 6, out_c = 1, K=2)
# np.zeros([1, 1, 1])与num_nodes 对齐
Target = np.zeros([1, 1, 1]) # [N, T, D],T=1 # 目标数据的维度,用0填充
# 可视化预测结果中的 nodes_id与num_nodes 对齐
visualize_result(h5_file="GAT_result.h5",
nodes_id = 0, time_se = [0, 15 * 4 * 5], # 是节点的时间范围
visualize_file = "result")结果
表现还是不错的
"""
Epoch: 0000, Loss: 0.0592, Time: 0.04 mins
Epoch: 0001, Loss: 0.0229, Time: 0.04 mins
Epoch: 0002, Loss: 0.0217, Time: 0.04 mins
Test Loss: 0.0001
Test Loss: 0.0004
Test Loss: 0.0008
...
Performance: MAE 7.66 0.24% 12.38
"""















 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









