



 针对一个基于JT808协议的项目,通过AndroidProfiler定位到SocketChannel的read方法导致CPU占用超过10%的问题。通过在read返回-1时增加延时,成功解决了CPU占用过高的情况。
针对一个基于JT808协议的项目,通过AndroidProfiler定位到SocketChannel的read方法导致CPU占用超过10%的问题。通过在read返回-1时增加延时,成功解决了CPU占用过高的情况。
1.接手的项目apk中基于JT808协议用Socket上传位置等消息,用命令top -m 10 -s cpu
查看cpu消耗时发现此app占用cpu超过10%
先把GPS停了,重新运行还是会很耗cpu
2.定位
用Android Profiler查了下点record
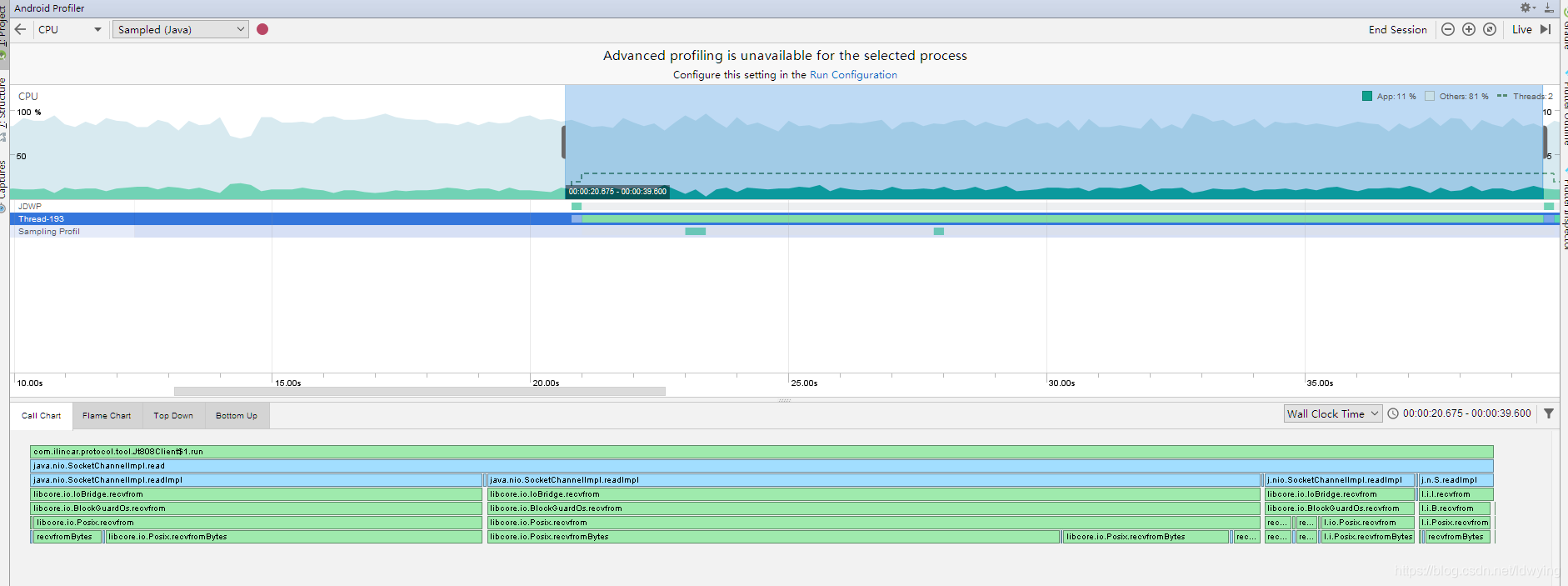
最终定位到
线程里SocketChannel里的read方法
while (true) {
try {
int len = 0;
len = channel.read(readbuffer);
//Log.i(TAG, "channel.read len == " + len);
if ( len > 0 && handler != null) {
发现是死循环里不断read
于是在read读不到也就是返回-1里,做了短暂延时,问题解决.

















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









